社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
https://github.com/1012598167/scrapy-wikipedia-country-company-google/tree/master/wiki_google
2)描述:根据用户输入的关键字搜索,爬取搜索结果页面内容,如url、内容等
3)输入:关键字。
4)输出:搜索结果前5页内容及url。
5)字段:关键字#标题#内容#url
6)要求:爬取搜索结果前5页
由于文件名是wiki_google,可能会造成误解,先声明爬的是google,与wiki无关!文件名取wiki_google只是想和别的文件统一一下,好看。
另外翻墙请务必开全局模式不用PAC模式!不然DNS会lookup failed。
自己实现的话会有各种各种各种各种各种奇奇怪怪鸡毛蒜皮但磨人性子的问题,本人花了好久才解决,代码倒不难,就是google的机制是真的恶心,一些细节提示会在‘中间过程’附上,请务必注意!
本人写小段代码没有封装很多函数的习惯,势必会有代码逻辑就不清的情况,请不要模仿!
conda install scrapy
选择一个文件夹,打开powershell
mkdir internship spider scrapy
cd internship spider scrapy
scrapy startproject wiki_google
scrapy genspider googlespider
scrapy list#看有没有生成这个spider 结果有googlespider
之后在wiki_country文件下放querys和results文件存输入和输出
startproject完了就差不多是这样,主要是为了大家知道querys和results的位置。
除了spider外基本就动了一个robots,主要是想说注意事项的。
先是在各种不同操作系统的云服务器上可能出的问题,比如这边云服务器用的CentOs,遇到了这些问题。
问题:处理字符串时报错 比如.replace(’xa0’, ’ ')
错误:UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xa0 in position 0等
解决:不要用runspider用框架 或者 将字符串改成如u’xa0’ u’ ’
问题:一些参数不能使用
错误:TypeError: ‘encoding’ is an invalid keyword argument for this function等
解决:运行时使用如python3 -m scrapy xxxx
当然你也可以
#source py3env/bin/activate
basepath=$(cd dirname $0; pwd)
echo $basepath
等去搞个新环境什么的
错误:SyntaxError: Non-ASCII character ‘xe6’ in file
解决:确保
# -- coding: utf-8 --
一定放在第一行没用回车空格之类的
问题:同一个网址 服务器和本地解析的完全不同 服务器的response.body和本地的完全不一致
或者xpath helper结果和实际不同
解决:在本地网址中加上/en之类的确保网站是英文的
(另外如google之类会经常重定向 导致解析的和实际输入网址加载出来的东西完全不一样(即使网址输错了也会让你觉得输对的 比如把?q=输成各种#q q之类 输错的那个没有response 但浏览器上那个网址的确可以)
解决:肯定是动态网页或者对面一堆服务器 要么根据network来解析 或者带着错误的url去google搜)
另:这么设了 还是可能会有不一致 请一切以view(response)开出来的html或者response.body的结果为准,具体为什么两边可能不一致,比如有的会多一些浏览结果和窗口,并且结果顺序和个数也不一致,我也解释不清楚。
试着在正则串前加r’’ (本项目中后来把正则去了)
整个运行可通过bash a.sh来完成
将 pac 模式改为全局模式
类似软件相同, 使用全局代理就没有问题
屡试不爽
这招也对用IP地址代替url访问不了一样有用。
在使用Scrapy Shell命令行时,一定要记得用引号将网址包括起来, 否则urls包含的参数 (ie. &character)会不起作用.
Widows系统下,使用双引号代替:
scrapy shell "http://quotes.toscrape.com/page/1/"
若直接用谷歌的任意其中一个IP地址172.217.14.78会报Invalid DNS-ID(如果robot设成true直接报错终止 设成false会报warning )是因为scrapy官方库没写好罢了#当初一直坚持用IP 甚至导致本地windows crawl的时候没response是因为要统一windows和云服务器CentOS那边的界面 方便调试
因为用了ip地址,twisted将其传给verify hostname,所以验证失败(正如ping不通那个ip地址但是能上网站一样 因为google服务器禁止了ping),因为SSL/TLS算法告诉他失败,这只能说是scrapy本身报错的提示写得不好(在ScrapyClientTLSOptions的definition里面)说成Invalid DNS-ID,实际上DNS-ID是个啥。。说不清楚 就简单的说直接用url别用ip就完了
另:如果用ip地址能上google也只是因为挂了代理 用校网或者PAC代理模式是上不去的
确保用的是url不是IP地址,并且代理设成了全局模式。
是因为加载出来的界面就不一样,,,,google就是辣么神奇
所以一切以view(response)出来的为准,若用的不是图形化界面,可以通过改代码之后命令行scrapy crawl输出view(response)的html界面,然后发给图形化界面的操作系统去分析html。
ROBOTSTXT_OBEY = False
先不遵守君子协议robot,不然随随便便google就把你拦了,说你什么DNS,TCP之类的问题,甚至可能出现超时或者直接被墙被重定向被recaptcha之类的问题,所以肯定是不遵守。
# -*- coding: utf-8 -*-
#由于scrapy开出来的界面与实际完全不一样 甚至在windows和CentOS开出来也不一样 所以一切以scrapy爬出来的实际结果为准
import scrapy
import json
import time
import random
import re
#from ..items import WikiGoogleItem
#from ..getProxy import get_ip_list,get_proxies,getHTMLText
class GooglespiderSpider(scrapy.Spider):
name = 'googlespider'
#allowed_domains =['www.google.com']
# def __init__(self):
# self.pagenow=''
# self.page = 1
def start_requests(self):
with open(r'wiki_google/querys/input.json', 'r') as f:
querys = json.load(f)
id=1#第几个query
for query in querys['query']:
pre_query=query#用来当文件名输出
###HTML ASCII Reference
new_query=''
for alpha in query:
o=ord(alpha)
if (o >= 33 and o <= 47) or (o >= 58 and o <= 64) or (o >= 91 and o <= 96) or (o >= 123 and o <= 126):
new_query+=hex(o).replace('0x','%')
else:
new_query+=alpha
query = new_query.replace(' ','+')
###
path = 'https://www.google.com/search?q=%s&hl=en' % query#因为服务器开出来的是english版本 所以爬english的
# 若直接用谷歌的任意其中一个IP地址172.217.14.78会报Invalid DNS-ID(如果robot设成true直接报错终止 设成false会报warning )是因为scrapy官方库没写好罢了
# 当初一直坚持用IP 甚至导致本地windows crawl的时候没response是因为要统一windows和云服务器CentOS那边的界面 方便调试
#把CentOS的DNS手动改成8.8.8.8
yield scrapy.Request(url=path,meta={'query': query,'pre_query':pre_query,'id':id,'page':{id:1}},callback=self.parse)# # 下一个要执行的函数为parse
id+=1
def parse(self, response):
query = response.meta['query']
pre_query=response.meta['pre_query']
id=response.meta['id']
page=response.meta['page']
fields = response.xpath('.//div[@class="ZINbbc xpd O9g5cc uUPGi"]')
page_value=page[id]
res_path = r'wiki_google/results'
f_name = res_path + '/' + str(id) + '_' + pre_query + '_page'+ str(page_value)+ '.txt' # 要导入结果的文件名
fw = open(f_name, 'w', encoding='utf-8') # 覆盖写
fw.write('key#title#content#urln')
for field in fields:
# 考虑到最开始会有视频 还有一些小标签之类的 要把所有信息提出来 所以分类讨论
#所谓的视频标签和正常小块等等的区别 在于标题的class是BNeawe vvjwJb AP7Wnd还是BNeawe deIvCb AP7Wnd
#或者有左右的滚轮或者没有左右滚轮(如球队啊视频啊之类的)即len(content_list)是否=2
content_list=field.xpath('..//div[@class="BNeawe s3v9rd AP7Wnd"]')
if (len(content_list)==2):#不是视频
title = field.xpath('..//div[@class="BNeawe vvjwJb AP7Wnd"]/text()').extract_first()
if not(title):
title = field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract_first()
#不排除的确是滚轮但是只有两项的情况
if(title):#不是视频和标签之类 是正常的一个小块
content = content_list[0].xpath('string(.)').extract_first()#把�换成/!!! 不需要换了 浏览器那显示�只不过是本地编码的问题
#url = field.xpath('..//div[@class="BNeawe UPmit AP7Wnd"]/text()').extract_first().replace(' › ', '/')#把>换成/!!!
url = 'https://www.google.com' + field.xpath('..//a//@href').extract_first().replace(' › ', '/')
#print(title,content,url,'n')用于调试
#这里结果中会有些一条内容占多行 用str将其拉成一行
#fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n') 如果不要一行 保留原来空格 把str去了就是
else:#是标签
title=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]/text()').extract_first()
content = content_list[0].xpath('string(.)').extract_first() # 把�换成/!!!
url = 'https://www.google.com'+field.xpath('..//a//@href').extract_first().replace(' › ', '/')
fw.write(pre_query)
# try:
fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n')
# except:
# print('#######title:', title, 'n')
# print('#######content:', content, 'n')
# print('#######url:', url, 'n')
# return
elif len(content_list)==0:#比如republic of china里的Top stories
title=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract_first()
titles=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract()[1:]
content_list = field.xpath('..//a[@class="tHmfQe"]')
for content_ in content_list:
content = content_.xpath('string(..//div[@class="BNeawe deIvCb AP7Wnd"])').extract_first().replace('n', '')
url = 'https://www.google.com' + content_.xpath('.//@href').extract_first()
fw.write(pre_query)
fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n')
else:#在首页的视频里边
content_list=field.xpath('..//a[@class="BVG0Nb"]')
title = field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract_first()
if not(title):
title = field.xpath('..//div[@class="BNeawe vvjwJb AP7Wnd"]/text()').extract_first()
#不排除title是非首页最上方title的滚轮情况
content_exist=field.xpath('..//div[@class="BNeawe wyrwXc AP7Wnd"]')#比如PEOPLE ALSO SEARCH FOR 等标签
if not(content_exist):#无标签 就正常的最前面的那种大标签
for content_ in content_list:
content = content_.xpath('string(.)').extract_first().replace('n', '')
url = 'https://www.google.com' + content_.xpath('.//@href').extract_first()
fw.write(pre_query)
# try:
fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n')
# except:
# print('#######title:',title,'n')
# print('#######content:', content, 'n')
# print('#######url:', url, 'n')
# return
else:#有比如PEOPLE ALSO SEARCH FOR / TEAMS 之类标签
block_without_title=field.xpath('..//div[@class="xpc"]')
long_content=''
iters=block_without_title.xpath('.//div[contains(@class,"jfp3ef")]')
key=0#决定是内容还是下面的滚轮
for iter in iters:
is_label=iter.xpath('./span/div[@class="BNeawe wyrwXc AP7Wnd"]')
if key==0:
if not(is_label):
long_content +=iter.xpath('string(.)').extract_first()
else:
key=1
content=long_content
url = 'https://www.google.com' + field.xpath('.//@href').extract_first()
fw.write(pre_query)
fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n')
title = iter.xpath('string(.)').extract_first()#第一次key=1的title
else:
if is_label:
title = iter.xpath('string(.)').extract_first()
else:
content=iter.xpath('string(.)').extract_first().replace('n', '')
url = 'https://www.google.com' + iter.xpath('../../../../a//@href').extract_first()
fw.write(pre_query)
fw.write('#' + str(title) + '#' + str(content) + '#' + str(url) + 'n')
page_value+=1
fw.close()
if page_value==6:
print('#############################################################n')
#self.crawler.engine.close_spider(self, 'scrape %s in google for 5 page successfully!' % query)
print('scrape %s in google for 5 page successfully!' % pre_query)
print('#############################################################n')
return
next_page=response.xpath('//a[@aria-label="Next page"]//@href').extract_first()
if not(next_page):
print('#############################################################n')
print('scrape %s in google for %d page successfully!nthis query has only %d page!n'%(pre_query,page_value-1,page_value-1))
print('#############################################################n')
return
else:
pagenow_value = 'https://www.google.com'+next_page
yield scrapy.Request(url=pagenow_value, meta={'query': query,'pre_query':pre_query,'id':id,'page':{id:page_value}}, callback=self.parse)
time.sleep(random.random() * 5)
我的代码出名的乱。。然后拆开来解释,照着这个就是一个个函数。
with open(r'wiki_google/querys/input.json', 'r') as f:
querys = json.load(f)
id=1#第几个query
for query in querys['query']:
pre_query=query#用来当文件名输出
###
path = 'https://www.google.com/search?q=%s&hl=en' % query#因为服务器开出来的是english版本 所以爬english的
# 若直接用谷歌的任意其中一个IP地址172.217.14.78会报Invalid DNS-ID(如果robot设成true直接报错终止 设成false会报warning )是因为scrapy官方库没写好罢了
# 当初一直坚持用IP 甚至导致本地windows crawl的时候没response是因为要统一windows和云服务器CentOS那边的界面 方便调试
#把CentOS的DNS手动改成8.8.8.8
yield scrapy.Request(url=path,meta={'query': query,'pre_query':pre_query,'id':id,'page':{id:1}},callback=self.parse)# # 下一个要执行的函数为parse
id+=1
id代表第几个query,meta里的给parse服务。
###HTML ASCII Reference
new_query=''
for alpha in query:
o=ord(alpha)
if (o >= 33 and o <= 47) or (o >= 58 and o <= 64) or (o >= 91 and o <= 96) or (o >= 123 and o <= 126):
new_query+=hex(o).replace('0x','%')
else:
new_query+=alpha
query = new_query.replace(' ','+')
这是在处理HTML ASCII Reference,就比方说在query中输了一个空格,但是url总不允许有空格吧,那么Reference是按把空格变成+,那就这么变呗。至于其他的 比如+变成%2B 都是ASCII码10进制转16进制的结果,具体可以自行谷歌HTML ASCII Reference。
情况按照各种xpath格式分成巨多类,先把情况展示如下。
最一般的:
一个标题,一个其实不是URL的链接,一段内容,这占了几乎所有的情况,由这段来解决。
content_list=field.xpath('..//div[@class="BNeawe s3v9rd AP7Wnd"]')
if (len(content_list)==2):#不是滚轮
title = field.xpath('..//div[@class="BNeawe vvjwJb AP7Wnd"]/text()').extract_first()
if not(title):
title = field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract_first()
#不排除的确是滚轮但是只有两项的情况
if(title):#不是视频和标签之类 是正常的一个小块
content = content_list[0].xpath('string(.)').extract_first()#把�换成/!!! 不需要换了 浏览器那显示�只不过是本地编码的问题
#url = field.xpath('..//div[@class="BNeawe UPmit AP7Wnd"]/text()').extract_first().replace(' › ', '/')#把>换成/!!!
url = 'https://www.google.com' + field.xpath('..//a//@href').extract_first().replace(' › ', '/')
特殊1:
[外链图片转存失败(img-x5m0QvaR-1564892125566)(https://github.com/1012598167/my-tuchuang/raw/master/1564852559903.png)]]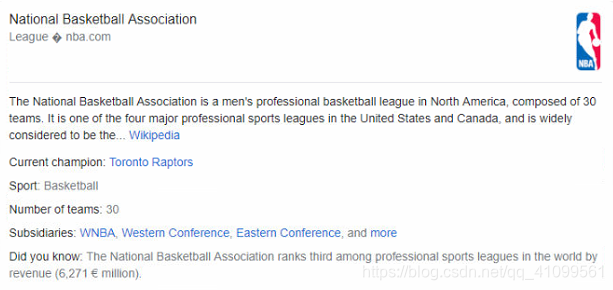
else:#是标签
title=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]/text()').extract_first()
content = content_list[0].xpath('string(.)').extract_first() # 把�换成/!!!
url = 'https://www.google.com'+field.xpath('..//a//@href').extract_first().replace(' › ', '/')
特殊2:
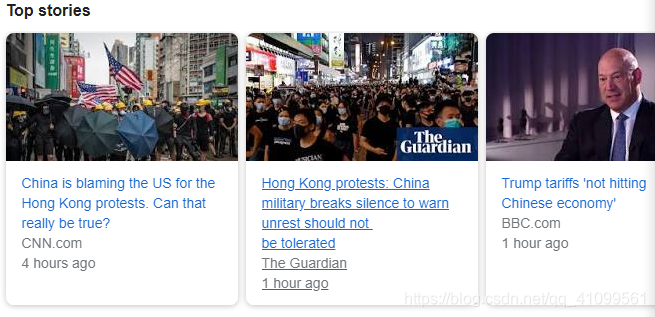
elif len(content_list)==0:#比如republic of china里的Top stories
title=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract_first()
titles=field.xpath('..//div[@class="BNeawe deIvCb AP7Wnd"]//text()').extract()[1:]
content_list = field.xpath('..//a[@class="tHmfQe"]')
for content_ in content_list:
content = content_.xpath('string(..//div[@class="BNeawe deIvCb AP7Wnd"])').extract_first().replace('n', '')
url = 'https://www.google.com' + content_.xpath('.//@href')
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_41099561/article/details/98456918
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

{kind=link}