社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
说起 Kafka 的第一个突出特定就是“快”,而且是那种变态的“快”。据最新的数据:每天利用 Kafka 处理的消息超过1万亿条,在峰值时每秒钟会发布超过百万条消息,就算是在内存和 CPU 都不高的情况下,Kafka 的速度最高可以达到每秒十万条数据,并且还能持久化存储。那么,Kafka 是如何做到的呢?
分布式消息系统 Kafka
授权协议:Apache
开发语言:Scala
操作系统:跨平台
开发厂商:Apache
Github:https://github.com/apache/kafka ★6120
Kafka 是一种分布式的,基于发布/订阅的消息系统。原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。之后成为 Apache 项目的一部分,主要用于处理活跃的流式数据。
kafka 有如下特性:
● 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
● 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
● 支持通过kafka服务器和消费机集群来分区消息。
● 支持Hadoop并行数据加载。
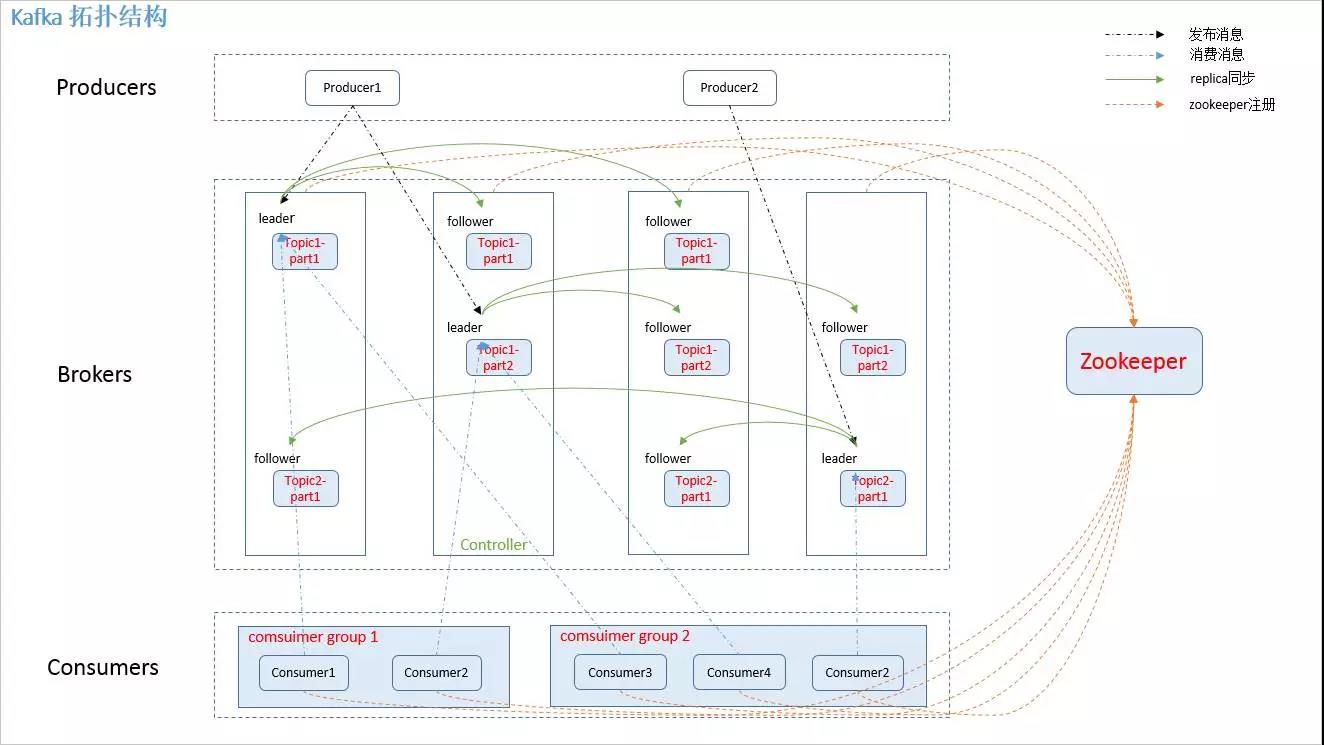
Kafka 的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。Producer,consumer 实现 Kafka 注册的接口,数据从 producer 发送到broker,broker 承担一个中间缓存和分发的作用。broker 分发注册到系统中的consumer。broker 的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。
kafka 相关名词解释如下:
1、producer:消息生产者,发布消息到 kafka 集群的终端或服务。
2、broker:kafka 集群中包含的服务器。
3、topic:每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
4、partition:partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。
5、consumer:从 kafka 集群中消费消息的终端或服务。
6、Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 的一个 Consumer 消费,但可以被多个 consumer group 消费。
7、replica:partition 的副本,保障 partition 的高可用。
8、leader:replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
9、follower:replica 中的一个角色,从 leader 中复制数据。
10、controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
11、zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息。
Kafka 有四个核心的 API。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的 TCP 协议。
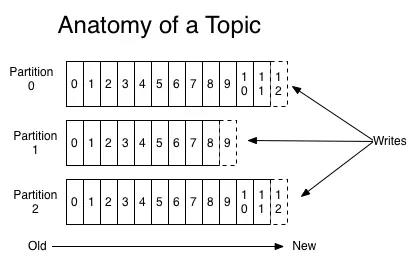
因为每条消息都被 append 到该 Partition 中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是 Kafka 高吞吐率的一个很重要的保证)。 Kafka 集群分区日志如下所示:
每个分区是一个有序的,不可变的记录序列,不断附加到结构化的提交日志中。每个分区中的记录都被分配一个顺序的 id 号,称为唯一标识分区中每个记录的偏移量。
消息队列
比起大多数的消息系统来说,Kafka 有更好的吞吐量,内置的分区,冗余及容错性,这让 Kafka 成为了一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并尝尝依赖于 Kafka 提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如 ActiveMR 或 RabbitMQ。
行为跟踪
Kafka 的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的 Topic 里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到 hadoop 离线数据仓库里处理。
元信息监控
作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控吧。
日志收集
日志收集方面,其实开源产品有很多,包括 Scribe、Apache Flume。很多人使用 Kafka 代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或 HDFS)进行处理。然而 Kafka 忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让 Kafka 处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如 Scribe 或者 Flume 来说,Kafka 提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
流处理
这个场景可能比较多,也很好理解。保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始 Topic 来的数据进行阶段性处理,汇总,扩充或者以其他的方式转换到新的 Topic 下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从 RSS 数据源中抓取文章的内容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返还给用户。这就在一个独立的 Topic 之外,产生了一系列的实时数据处理的流程。Strom 和 Samza 是非常著名的实现这种类型数据转换的框架。
事件源
事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。比如动态汇总(News feed)。
持久性日志(commit log)
Kafka 可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka 类似于 Apache BookKeeper 项目。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!