社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
通过上次的小猪短租爬虫实战,我们再次熟悉的使用requests发送一个网页请求,并使用BeautifulSoup来解析页面,从中提取出我们的目标内容,并将其存入文档中。同时我们也学会了如何分析页面,并提取出关键数据。
下面我们将进一步学习,并爬去小猪短租的详情页面,提取数据。
Just do it~~!
目标URL:https://weheartit.com/inspirations/beach?page=1
明确内容: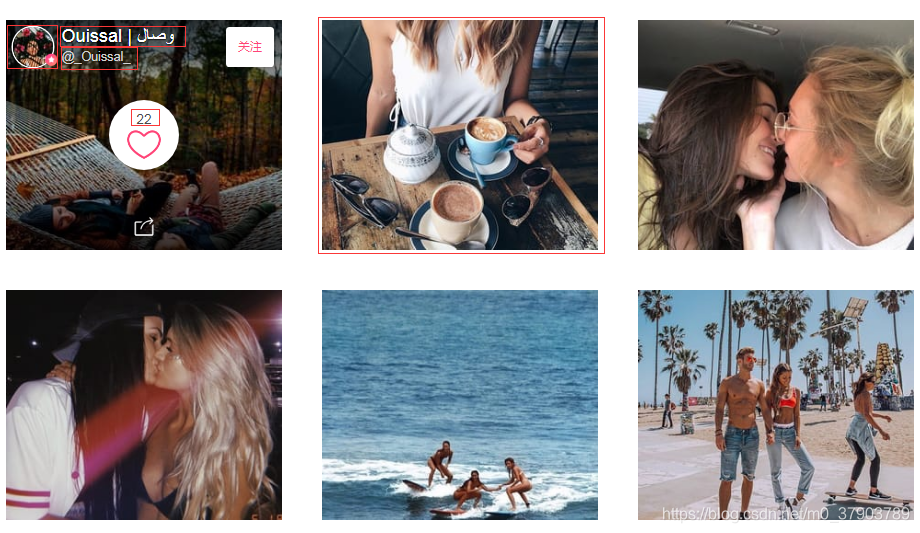
在列表页面中,找的了我们需要的数据:如title,img_src,name,host_src,comment等(红色方框中的内容)
下面我们需要遍历所有的列表页面,并从中提取目标数据。
1.查找规律
遍历所有的列表页,再下翻几页后,我们发现***page=X***(其中X为1,2,3,4…)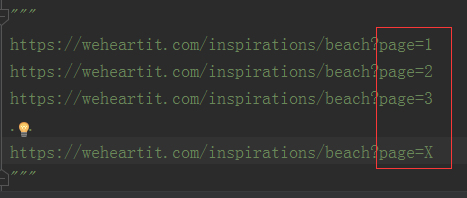
# 解析列表页面,并提取详情页的URL
def parse_html(self, html):
soup = BeautifulSoup(html, 'lxml')
lis = soup.select("div#page_list > ul > li")
for li in lis:
# 提取详情页URL
page_url = li.select("a")[0].attrs['href']
2.提取数据
# 解析网页,并提取数据
def parse_html(self, html):
item_list = []
soup = BeautifulSoup(html, 'lxml')
divs = soup.select("div.entry.grid-item")
for div in divs:
title = div.select("span.text-big")[0].get_text()
img_src = div.select("img.entry-thumbnail")[0].attrs['src']
temp_name = div.select("a.js-blc-t-user")[0].attrs['href']
name = temp_name.replace('/', '')
host_src = div.select("img.avatar")[0].attrs['src']
comment = div.select("span.js-heart-count")[0].get_text()
item = dict(
title=title,
img_src=img_src,
name=name,
host_src=host_src,
comment=comment,
)
print(item)
item_list.append(item)
return item_list
3.保存数据
# 保存数据
def save_item(self, item_list):
with open('WeHeartIt.txt', 'a+', encoding='utf-8') as f:
for item in item_list:
json.dump(item, f, ensure_ascii=False, indent=2)
f.close()
print("Save success!")

好了,本次讲解,到这里就差不多该结束啦~感兴趣的同学,可以动手试试。
通过上面的爬虫,我们获得了图片链接,那我们有该怎么讲图片下载下来?并保存到本地呢?
源码地址:https://github.com/NO1117/WeHeartIt_Spider
Python交流群:942913325 欢迎大家一起交流学习
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
