社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
最近有读者反映想要下载千图网的高清背景图片,但是需要会员才能下载,而且需要的量非常大,问博主有没有办法能免费下载这些图片。
付费,不存在的o( ̄▽ ̄)o!,博主今天讲解如何通过python爬取千图网的高清背景图片。
快,快,坐好小板凳,拿好小瓜子,听博主吹牛,额,是讲课,讲课!╰( ̄ω ̄o)
为了完美食用本篇教程贴,搭建好如下环境
可以上互联网的win7或win10电脑一台
火狐浏览器(版本无要求)
Python(版本3就可以了)
requests库(版本没啥要求)
lxml库(版本:4.3.3,需要带有etree的lxml库)
我们本次要爬取的网页是:千图网背景图片模块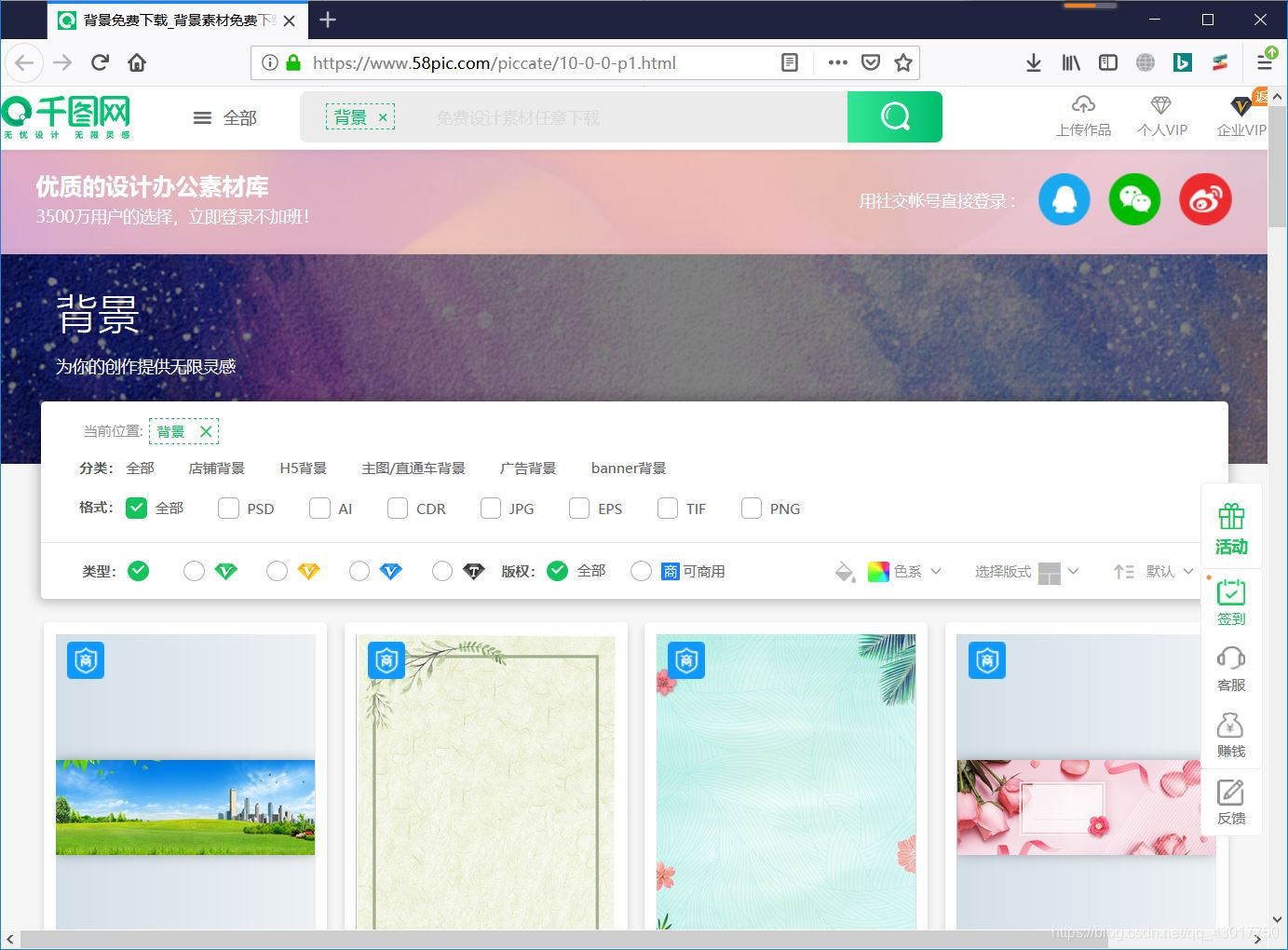
我们【右键】下面的四张背景图片中的其中一张,在弹出的选项栏中选择【查看元素】,查看背景图片的网页代码
在这里插入图片描述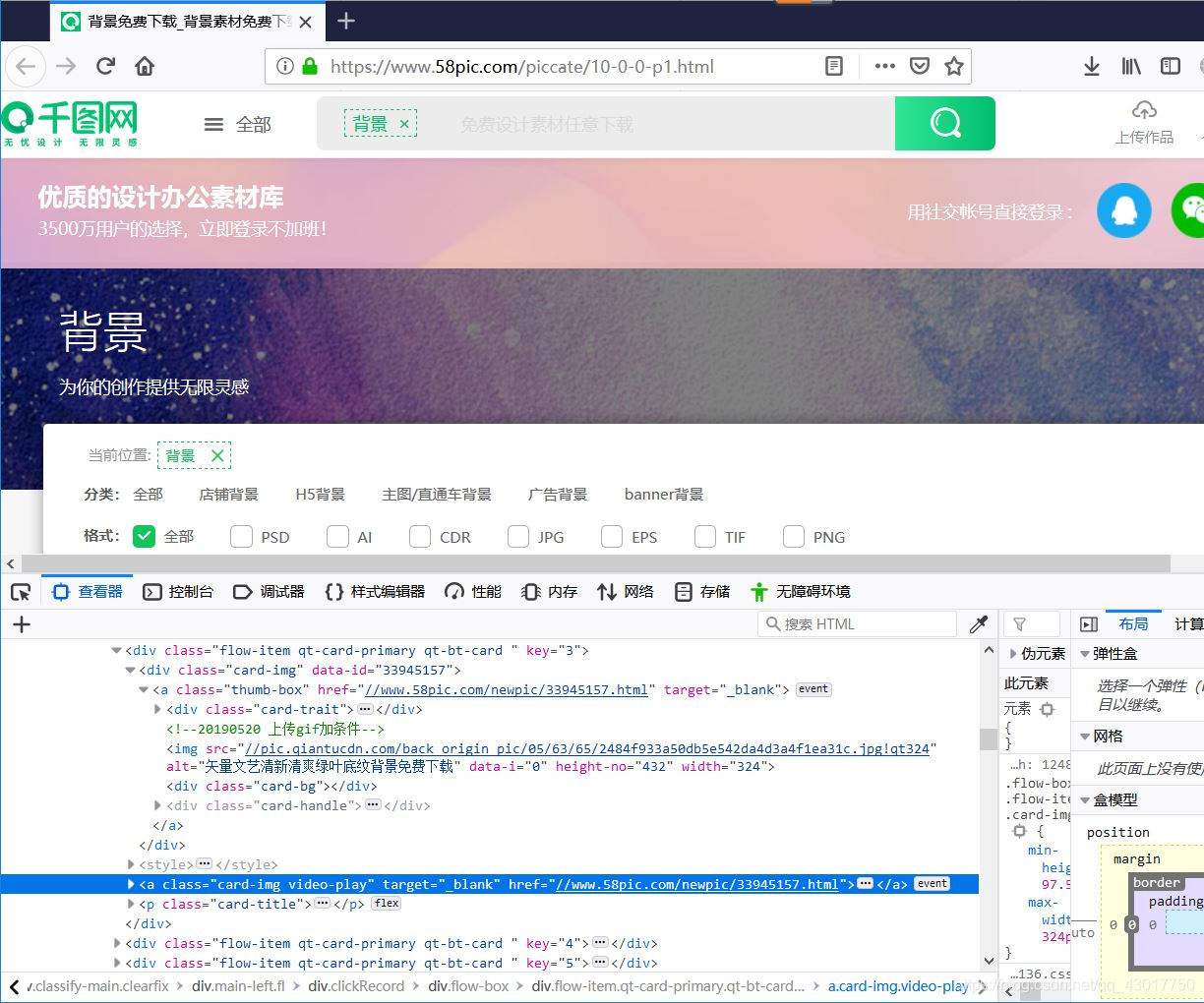 可以看到图片指向了一个url,我们将这个url复制出来,在新的标签页中打开。看看,是不是到了图片的高清大图页面。
可以看到图片指向了一个url,我们将这个url复制出来,在新的标签页中打开。看看,是不是到了图片的高清大图页面。
url链接【//www.58pic.com/newpic/33945157.html】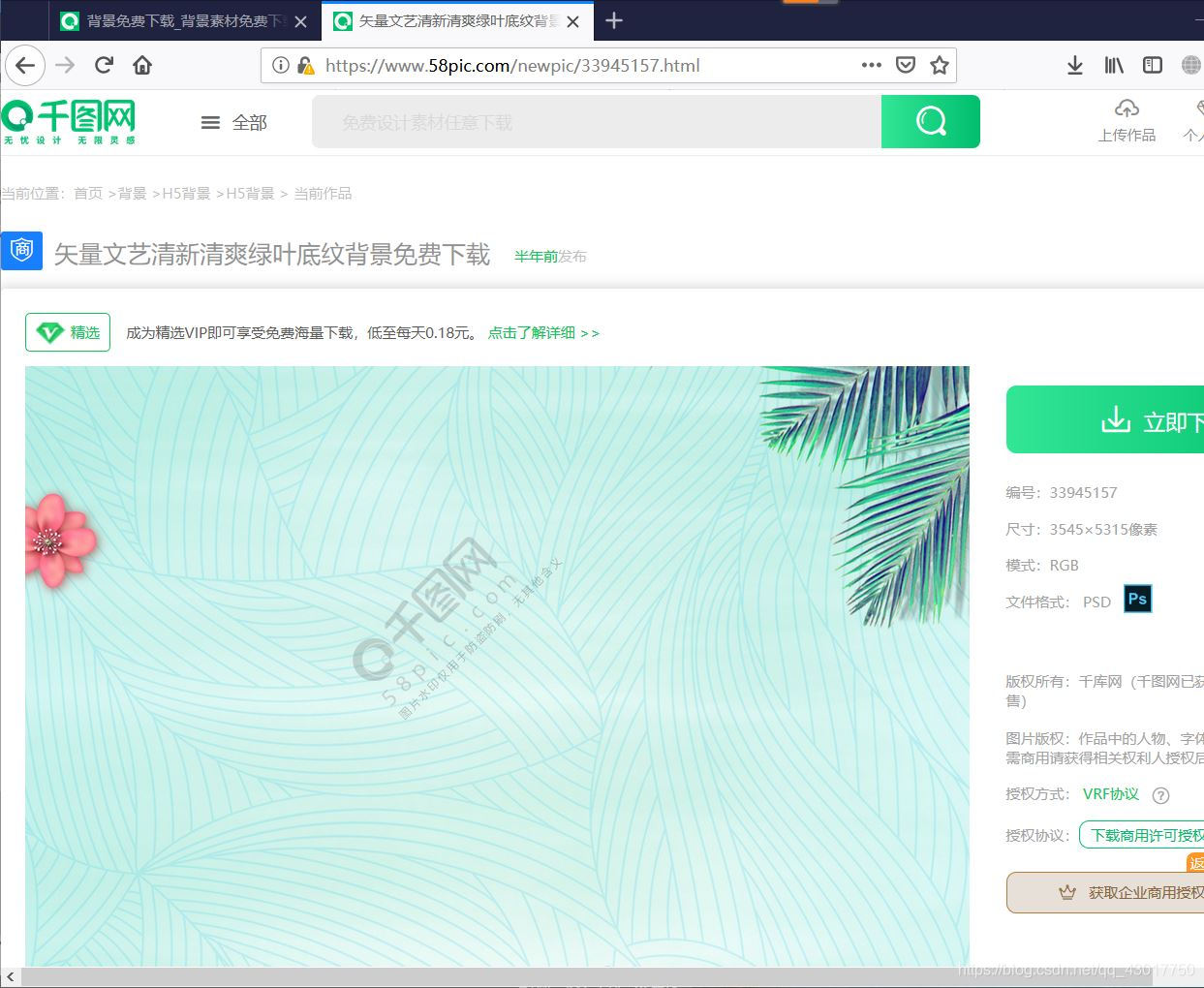 可以看到进入了图片的高清大图页面。证明,我们最开始打开的页面
可以看到进入了图片的高清大图页面。证明,我们最开始打开的页面
【https://www.58pic.com/piccate/10-0-0-p1.html】 的源代码中包含着每张图片的高清大图页面的url。这就说明,我们可以通过爬取最开始打开的页面的源代码进入对应的背景图片的详情页面。(0◇0)/好棒!
我们在看看能不能在背景图片详情页面的源代码中找到图片对应的url,如果有url,我们就可以直接请求url下载高清大图了,就能实现和登陆下载一样的效果。
【右键】图片,点击【查看元素】,即可跳转到网页源代码中图片源码的位置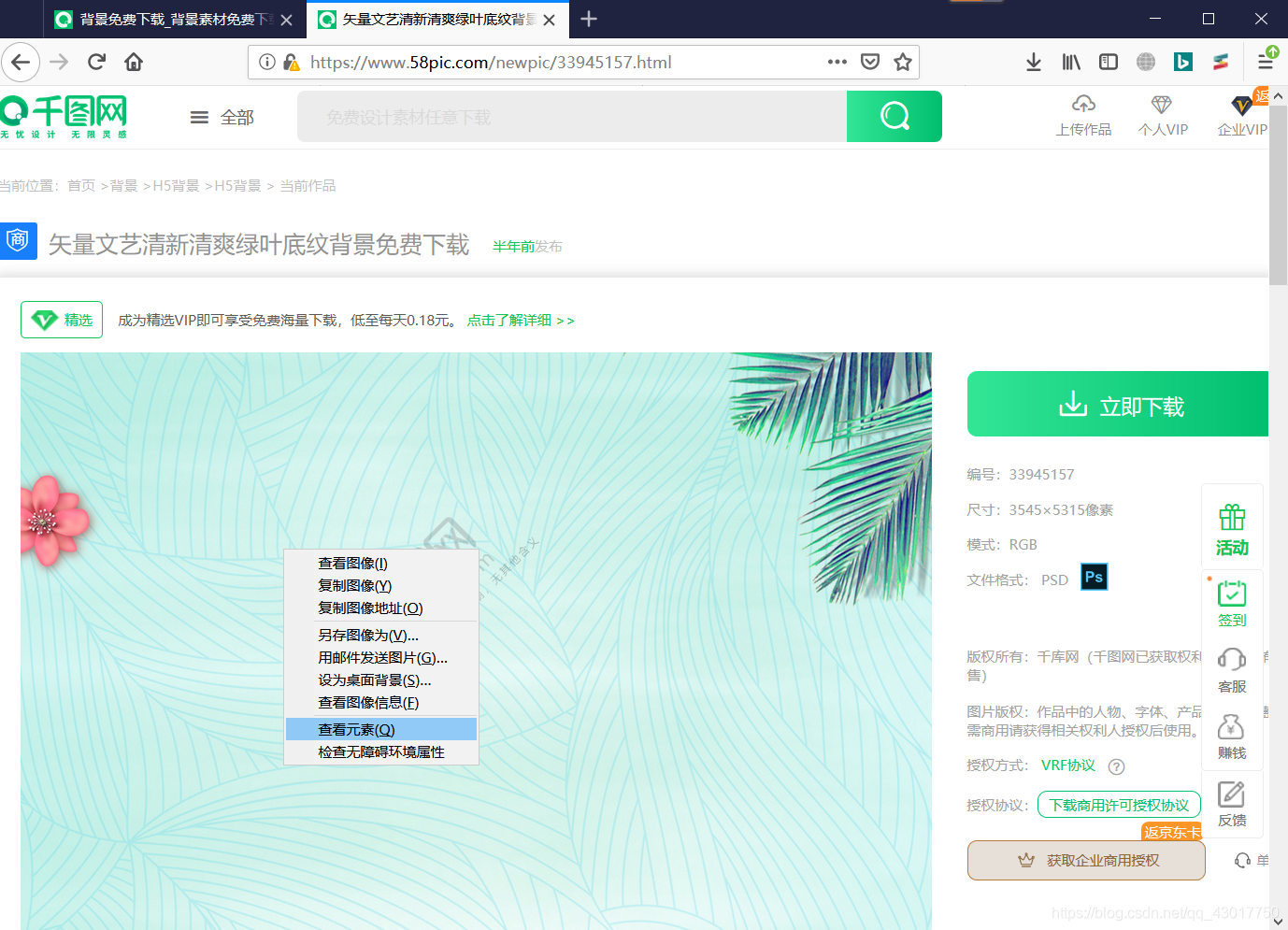 打开后的页面如下:
打开后的页面如下: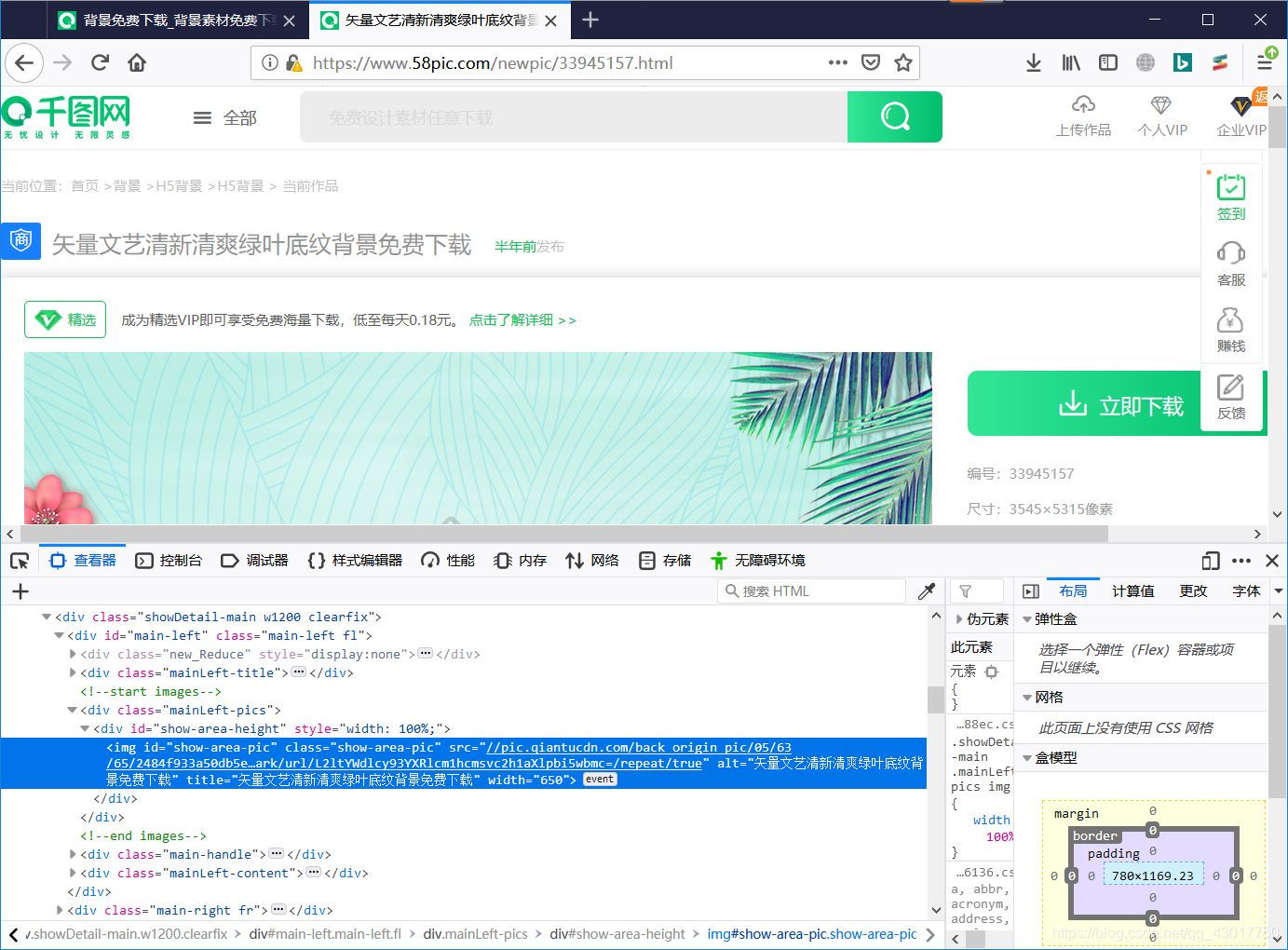 可以看到高清大图的url存在于页面的源代码当中。我们将这个图片的网址复制出来,在新页面中打开看看,是不是对应的这张图片。
可以看到高清大图的url存在于页面的源代码当中。我们将这个图片的网址复制出来,在新页面中打开看看,是不是对应的这张图片。
图片链接【//pic.qiantucdn.com/back_origin_pic/05/63/65/2484f933a50db5e542da4d3a4f1ea31c.jpg!/fw/1024/watermark/url/L2ltYWdlcy93YXRlcm1hcmsvc2h1aXlpbi5wbmc=/repeat/true 】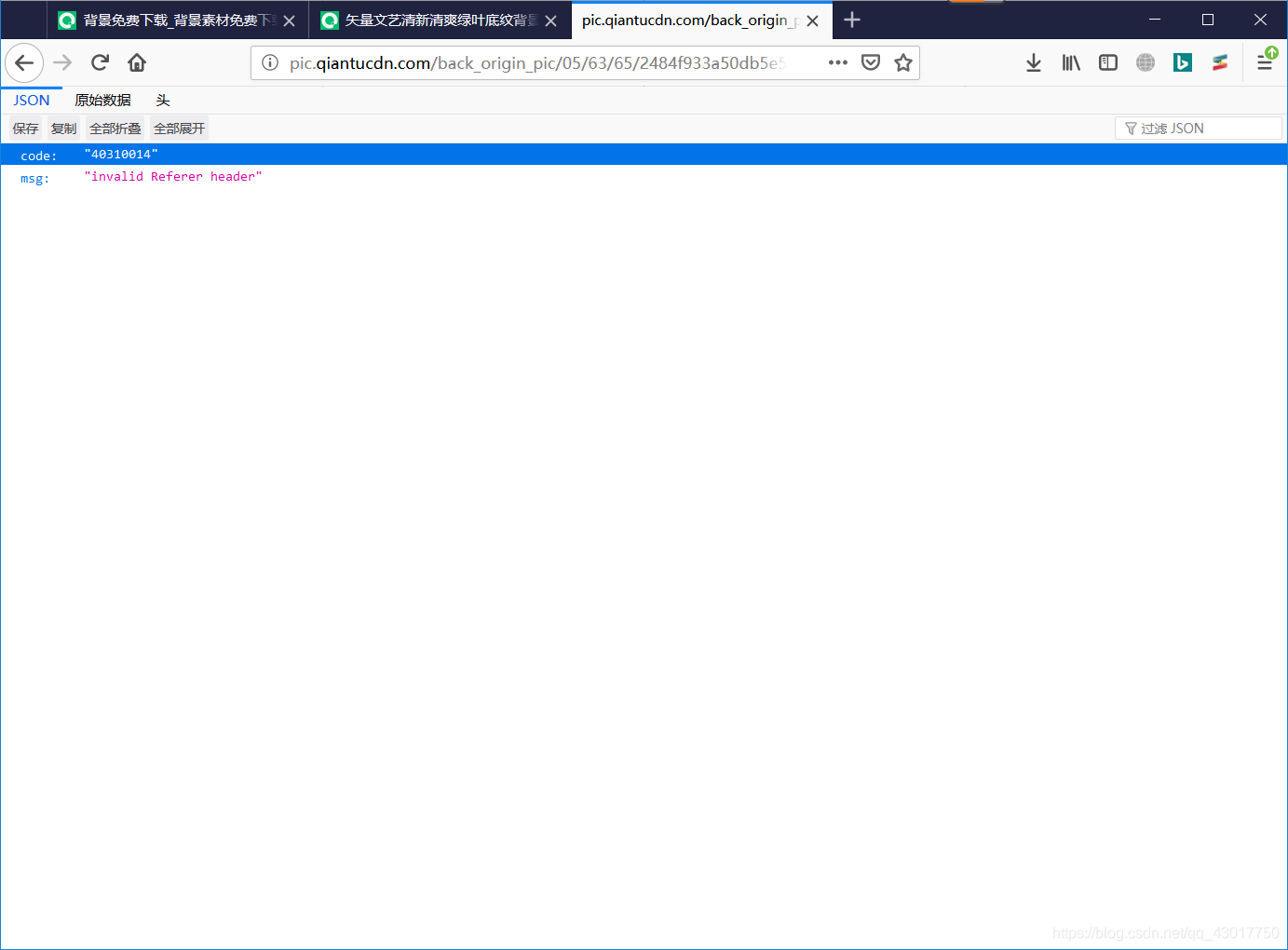 提示referer头错误,证明下载图片时,请求头中需要携带referer参数。
提示referer头错误,证明下载图片时,请求头中需要携带referer参数。
那这个referer参数是干啥的呢(⊙o⊙)?
referer你可以理解为告诉网站服务器,我是从哪个网页跳转过来的。
我们现在总解下上面分析的内容:
1.首先爬取首页面,比如说这个【https://www.58pic.com/piccate/10-0-0-p1.html 】,首页面的源代码中包含有详情页的url
2.详情页的url中包含有高清大图的详细url
3.请求高清大图的url时需要在请求头中携带referer参数
好腻害,我们居然猜到了网页设计着的思路╰( ̄ω ̄o)
话不多说,我们来写python代码
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月21日
第一行 # -*- coding:utf-8 -*-的意思时指点该程序使用的utf-8编码,这个utf-8编码是干啥的呢?这里博主先不做讲解,我们先指导程序的开头需要写上这句代码就可以了。(づ ̄ 3 ̄)づ皮一下,很开心。
第二行和第三行不是必须要写的,可以省略。。。。
import requests
from lxml import etree
这个requests的作用你可以理解为是获取网页代码的,etree的作用类似于转换网页格式,并提取我们想要的信息。
main_url = 'https://www.58pic.com/piccate/10-0-0-p1.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Referer':'https://www.58pic.com/piccate/10-0-0-p1.html',}
这个main_url指的就是我们首先要爬取的主页面的url,
headers存储的就是请求头信息,什么是请求头呢?就是用于告诉服务器我的信息,
headers中的User-Agent参数就是告诉服务器我使用的浏览器版本信息,我使用的这个就是告诉服务器,我使用的是火狐浏览器,是一台win10,64位的电脑。
headers中的Referer参数用于表示我是从哪个网页跳转过去的。
def get_html(url):
'''下载网页代码'''
html = requests.get(url,headers).text
return html
我们定义了一个get_html函数专门用于下载网页代码,每次使用这个函数下载网页代码时,需要给其传递一个url参数。
函数中,我使用requests库的get方法下载了网页的源代码,get方法使用了变量url和变量headers作为参数,这里的变量url,就是函数调用时传递的url参数,headers是我们在步骤2导入模块中设置的变量,用于作为请求头,我们讲下载到的网页代码的以文本的形式存储在变量html中,然后讲网页代码作为函数的执行结果弹出
我们先测试下执行效果
def get_html(url):
'''下载网页代码'''
html = requests.get(url,headers).text
return html
html = get_html(main_url)
print (html)
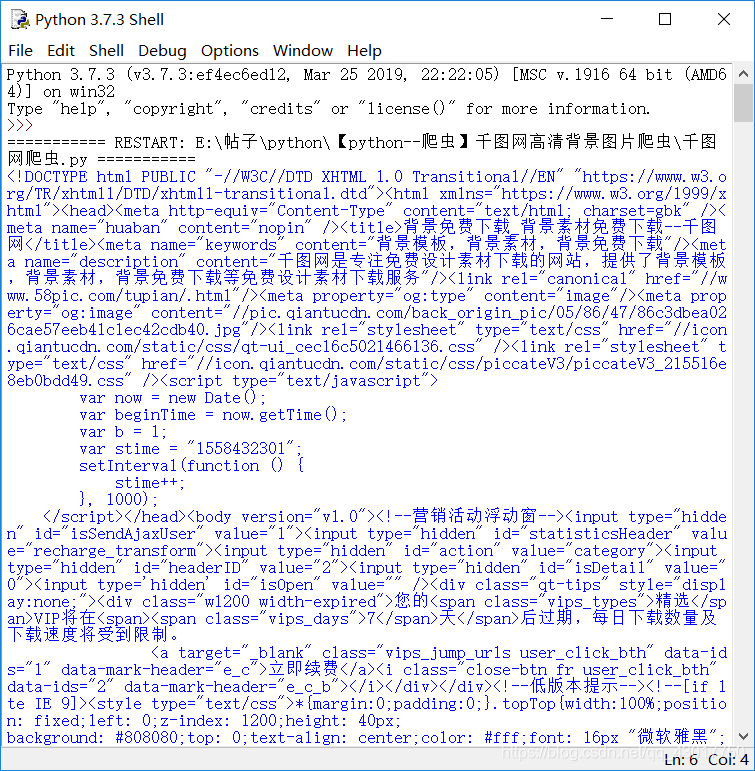 可以看到,我们成功的下载到了网页的源代码,好棒,好棒。鼓掌鼓掌ˋ( ° ▽、° )
可以看到,我们成功的下载到了网页的源代码,好棒,好棒。鼓掌鼓掌ˋ( ° ▽、° )
现在我们能下载到网页的源代码了,还需要提取出来网页代码中图片的详情页面的url
def get_page_url(data):
'''提取详情页url'''
html = etree.HTML(data)
url_list = html.xpath('//a[@class="thumb-box"]/@href')
return url_list
这里我们创建了一个名为get_page_url的函数专门用于提取主页面源代码中的图片详情页的url,调用该函数时需要将主页面的源代码作为参数传递进来。
首先我先使用etree.HTML()将传递进来的源代码html,转换为etree格式的数据,然后使用xpath匹配出了网页源代码中的所有图片详情页面的url
为啥xpath后面的括号中要写【’//a[@class=“thumb-box”]/@href’】呢?,因为在【需求分析】的第二张图片中讲到了,图片详情页的url存储在主页面源代码中class属性为"thumb-box"的a标签的href属性中( •̀ ω •́ )
我们调用查看下效果:
html = get_html(main_url)
url_list = get_page_url(html)
print (url_list)

现在我们获取到了图片详情页的url了,接着获取图片详情页的源代码
for url in url_list:
html=get_html('http:'+url)
print (html)
使用for循环提取出来详情页的url,然后使用前面创建的get_html进行下载网页源码,由于获取到的详情页的url缺少字符’http:'所以我使用【‘http’+url】将其补全。
当前我们的代码如下:
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月21日
import requests
from lxml import etree
main_url = 'https://www.58pic.com/piccate/10-0-0-p1.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Referer':'https://www.58pic.com/piccate/10-0-0-p1.html',}
def get_html(url):
'''下载网页代码'''
html = requests.get(url,headers).text
return html
def get_page_url(data):
'''提取详情页url'''
html = etree.HTML(data)
url_list = html.xpath('//a[@class="thumb-box"]/@href')
return url_list
html = get_html(main_url)
url_list = get_page_url(html)
for url in url_list:
html=get_html('http:'+url)
print (html)
实现了获取主页面的源码,然后提取出详情页的url,接着在获取详情页的源码。
执行后可以看到我们下载到了图片详情页的源代码了。 我们也能获取详情页面的源码了,接着就该提取出详情页中的高清大图的url
我们也能获取详情页面的源码了,接着就该提取出详情页中的高清大图的url
def get_img_url(data):
'''提取高清大图url'''
html = etree.HTML(data)
url = html.xpath('//img[@class="show-area-pic"]/@src')[0]
title = html.xpath('//img[@class="show-area-pic"]/@title')[0]+'.jpg'
return url,title
这里我们创建了一个名为get_img_info的函数专门用于提取详情页代码中的图片信息,包括图片的url和图片的标题,调用该函数时需要将详情页的源代码作为参数传递进来。
首先我先使用etree.HTML()将传递进来的源代码html转换为etree格式的数据,然后使用xpath匹配出了网页源代码中的图片的url和title
为啥xpath后面要写[0]呢?,因为xpath默认匹配出的数据是以列表的形式存在的( •̀ ω •́ ),为了将内容提取出来所以要加[0],为啥匹配title的xpath最后面还有 【+‘.jpg’】,应为此时只有文件名,没有后缀,所以博主这里使用【+】加号将其拼接成完整的文件名。然后使用return将图片的url和图片的名称传递出来。
def get_img(url,file):
'''下载图片'''
file_name = 'picture\'+file
img = requests.get(url,headers=headers).content
with open (file_name,'wb') as save_img:
save_img.write(img)
这里我们创建了一个名为get_img的函数专门用于下载图片,包括下载图片和保存图片到指定目录下,调用该函数时需要将图片的网址和文件名作为参数传递进来。
首先我将保存的文件夹和文件名合并得到图片完整的存放路径,然后使用requests库的get 方法下载图片的二进制数据,将url和headers传递给get方法,headers作为get方法的请求头。将得到的图片数据保存到指定的文件中。
# -*- coding:utf-8 -*-
#作者:猫先生的早茶
#时间:2019年5月21日
import requests
from lxml import etree
main_url = 'https://www.58pic.com/piccate/10-0-0-p1.html'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0',
'Referer':'https://www.58pic.com/piccate/10-0-0-p1.html',}
def get_html(url):
'''下载网页代码'''
html = requests.get(url,headers).text
return html
def get_page_url(data):
'''提取详情页url'''
html = etree.HTML(data)
url_list = html.xpath('//a[@class="thumb-box"]/@href')
return url_list
def get_img_url(data):
'''提取高清大图url'''
html = etree.HTML(data)
url = html.xpath('//img[@class="show-area-pic"]/@src')[0]
title = html.xpath('//img[@class="show-area-pic"]/@title')[0]+'.jpg'
return url,title
def get_img(url,file):
'''下载图片'''
file_name = 'picture\'+file
img = requests.get(url,headers=headers).content
with open (file_name,'wb') as save_img:
save_img.write(img)
html = get_html(main_url)
url_list = get_page_url(html)
for url in url_list:
html = get_html('http:'+url)
img_url,img_title = get_img_url(html)
get_img('http:'+img_url,img_title)
print ('正在下载{}'.format(img_title))
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

{kind=link}