社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
学python也快2个礼拜了,从开始看别人写的爬虫代码,然后试着抄着学习,感觉没太大进步,最大收获就是改了几处bug(可能有些地方不适用我的pyyhon平台报错)。
中午看到一个帖子校花妹子图使用爬虫进行批量下载,看了下,感觉不错(我说的技术,哈哈哈)。
然后决定自己写一个爬虫,已经看书两个礼拜了,也要练一练了。
声明:代码写的不怎么好,大神别嫌弃,可以给些建议。
先来点图片养个眼,提升下动力。
这个是批量下载的一个妹子的图片。
开始爬虫:本次使用的环境是linux-ubantu,python3。
import urllib.request
from bs4 import BeautifulSoup
import requests先获取页面链接内容
get_url = urllib.request.Request(url, headers)
res = urllib.request.urlopen(get_url).read()
res是获取的html网页。使用python的现成库BeautifulSoup去进行搜索。先去网页F12分析:
如下图:
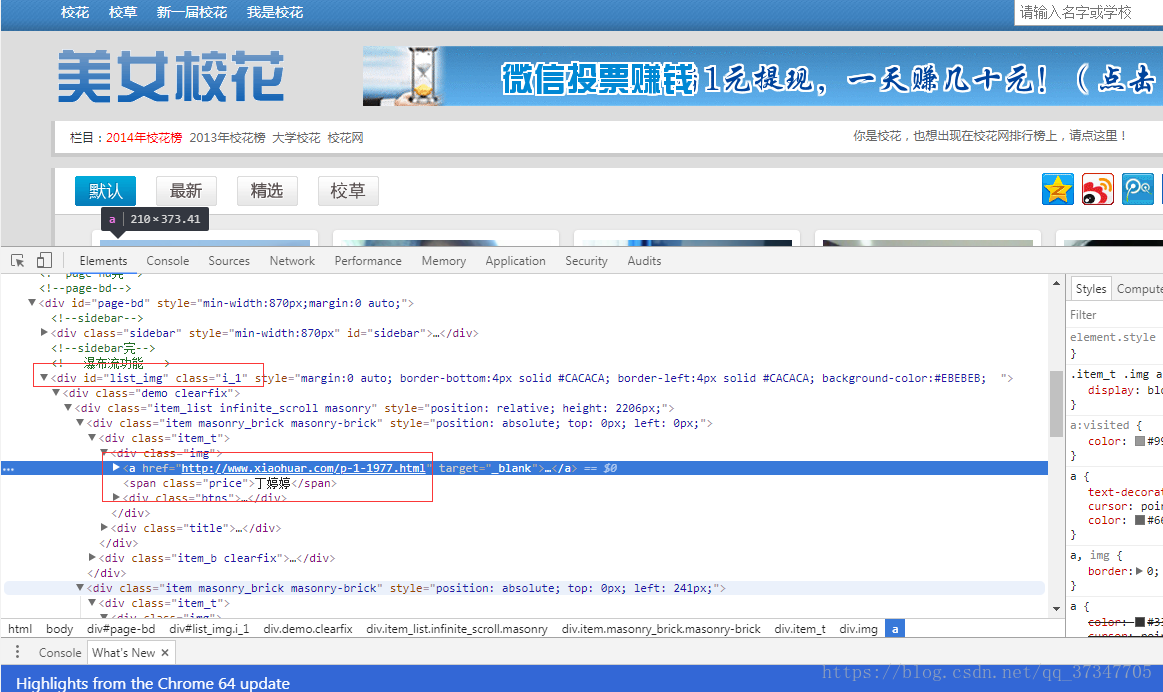
我画红框的那两个关键点,第一个是图片的list表,从这里可以获取每一个校花的列表。
soup = BeautfulSoup(res, "html.parser")
pict_list = soup.find('div', id='list_img').find_all('a', target='_blank')获取完的信息是下面这样的,可以看出一个校花的信息出现了两次,那就写一个判断的每次只取一个(方法简单不单独写了,所有代码附在最后)
find方法找到一整个列表, find_all方法发现每个校花的详细信息。
第二个烈表示其中之一校花的网页链接,通过这个链接可以知道这个校花所有的图片,然后打开这个网页,再针对单个校花进行分析:看图
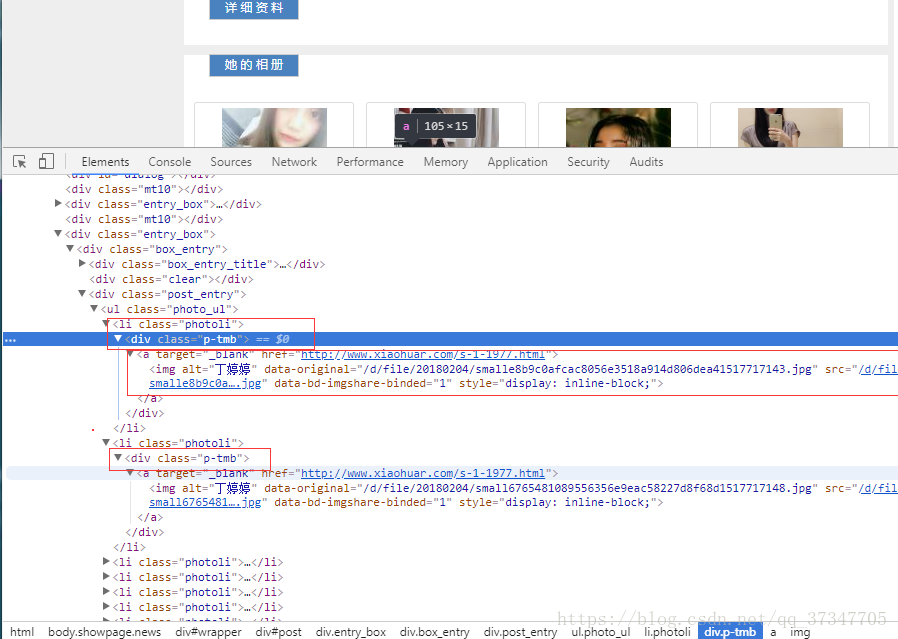
分析得出:每张妹子图都在div的class =="p-tmb"中间,使用find_all方法找出所有的,然后单独找出每一张的图片所在的信息行,使用find找出来。
soup = BeautifulSoup(ret_girl_url, "html.parser")
picture = soup.find_all('div', class_='p-tmb')仔细看,jpg格式的链接,是不完整的,自己把头部加一下,头部就是这个网页的首页地址。
获得了这么多信息,就可以直接进行下载保存了
这就下载好了,下载好的图片在一开始就已经展示了,在这里就不再展示了,把源码附在这里,想学习的可以看看,也可以给点建议,共同进步。
import urllib.request
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102UBrowser/6.1.2107.204 Safari/537.36'}
url_list = []
def get_href(url):
if url in url_list:
return None
else:
url_list.append(url)
return url
def down_pic(url):
r = requests.get(url, headers)
name = url[-10:-4]
print(name)
with open(name+'.jpg', 'wb') as f:
for chunk in r.iter_content(1024):
if chunk:
f.write(chunk)
def get_url_list(url):
get_url = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(get_url).read()
soup = BeautifulSoup(res, "html.parser")
pict_list = soup.find('div', id='list_img').find_all('a', target='_blank')
return pict_list
def get_new_url(content):
html = content['href']
new_url = get_href(html)
if new_url == None:
return None
else:
return new_url
def get_picture_url_info(url):
girl_url = urllib.request.Request(url, headers=headers)
ret_girl_url = urllib.request.urlopen(girl_url).read()
soup = BeautifulSoup(ret_girl_url, "html.parser")
picture = soup.find_all('div', class_='p-tmb')
return picture
def get_addr(girl_url):
tmp = girl_url.find('img')
addr = tmp['src']
www = "http://www.xiaohuar.com"
return www+addr
def start():
url = 'http://www.xiaohuar.com/list-1-d+.html'
lst = get_url_list(url)
for line in lst:
new_url = get_new_url(line)
if new_url == None:
continue
info = get_picture_url_info(new_url)
for girl in info:
addr = get_addr(girl)
print('addr:', addr)
down_pic(addr)
break
if __name__ == '__main__':
start()如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!