社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
我们要爬取的网址是:http://www.mzitu.com/
需要用到的库:requests,bs4,re,os,time,random
首先,进入网站首页,可以看到图片的分类和页码,虽然有很多类别,但仔细观察后就能发现所有类别的图片都包含在首页里。

然后点开第一张图片,发现了

看到这里,就能发现这个网站的首页有很多页,每一页中又有许多组图片,每一组也有很多页,一页只有一张图片。这就像离散数学中的树结构了。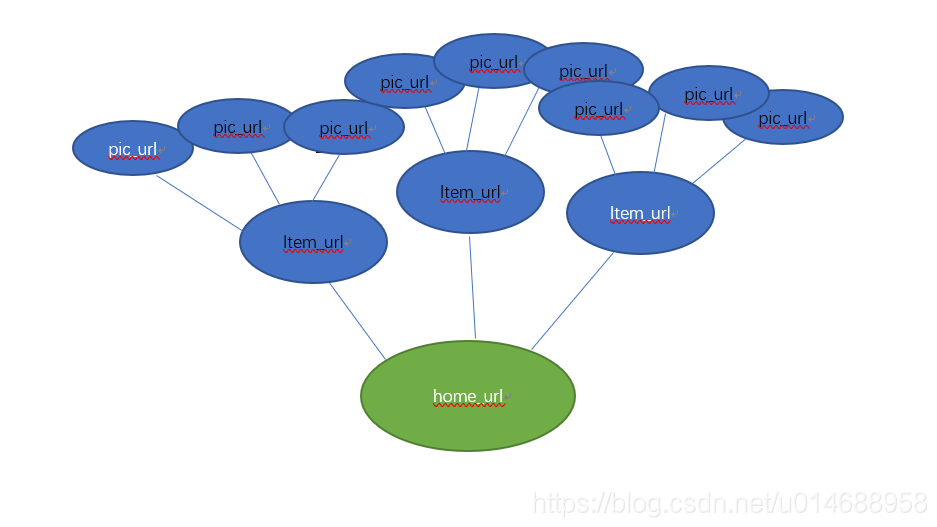
这样,这个网站的爬取思路就出来啦。
url = 'http://www.mzitu.com/'
kv = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'}
#如果不在headers里设置kv,则会出现防盗链,因为这个网站有反爬虫机制
path = os.getcwd()
def getItemUrls(html,ils):#得到主页里的所有item
items = re.findall('<span><a href="(.*?)" target="_blank">(.*?)</a></span><span class="time">.*?</span>',html)
for item in items:
item_url = item[0]
item_title = item[1]
ils.append([item_url,item_title])
这里使用re模块正则表达式抓取每一组图片的链接和标题并添加到列表里。
def getHtml(url):
r = requests.get(url,headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def getPicUrls(item):#得到每个item里的每张图片的url
if os.path.exists(path+'\'+item[1]):
pass
else:
os.mkdir(os.path.join(path, item[1])) #创建目录文件夹
print('创建路径成功: ',item[1])
item_path = path + '\' + item[1]
html = getHtml(item[0])
pages = re.findall("<a href='.*?'><span>(d+)</span></a>",html)
if pages:
max_page = max(map(int,pages)) #每一组图片中的最大页码
print('一共有{page}张图片:'.format(page=max_page))
for page in range(2,max_page+1):
pic_url= item[0] + '/' + str(page) #item中每一页的链接
downloadPic(pic_url,item_path) #下载图片
time.sleep(random.choice(0,5))
def downloadPic(pic_url,item_path):#保存下载图片
r = requests.get(pic_url,headers = kv)
r.raise_for_status()
html_ = r.text
soup = BeautifulSoup(html_,'html.parser')
pic_title = soup.find('h2',class_="main-title").string
pic_path = item_path + '\'+ str(pic_title) + '.jpg'
r_kv = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36','referer':pic_url}
pic_url1 = re.findall('<div class="main-image"><p><a href=".*?" ><img src="(.*?)" alt=".*?" /></a></p',html_)
#print(type(pic_url1)) #re.findall()的返回值是一个列表
if pic_url1:
response = requests.get(pic_url1[0],headers = r_kv)
response.raise_for_status()
with open(pic_path,'wb') as f:
f.write(response.content)
f.close()
print('图片保存成功:',pic_title)
以上的代码只实现了hom_url里第一页图片的下载。
def maxPage(text):
#判断最大页数
pages = re.findall('''<a class='page-numbers' href='.*?'><span class="meta-nav screen-reader-text"></span>(d+)<span class="meta-nav screen-reader-text"></span></a>''',text)
return max(map(int, pages))
def turnPages(url,html):
max_ = maxPage(html)
print('主页里的最大页码:',max_+1)
for i in range(2,max_):
next_url = url + 'page/' + str(i) + '/'
f_html = getHtml(next_url)
ilt = []
getItemUrls(f_html,ilt)
for item in ilt:
getPicUrls(item)
这样便下载了所有页码的图片。
def main():
html = getHtml(url)
ils = []
getItemUrls(html,ils)
for item in ils:
getPicUrls(item)
turnPages(url,html)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
