社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
爬图的数量根据你输入的页数确定,纯洁的我只是适当的爬了几张学习技术。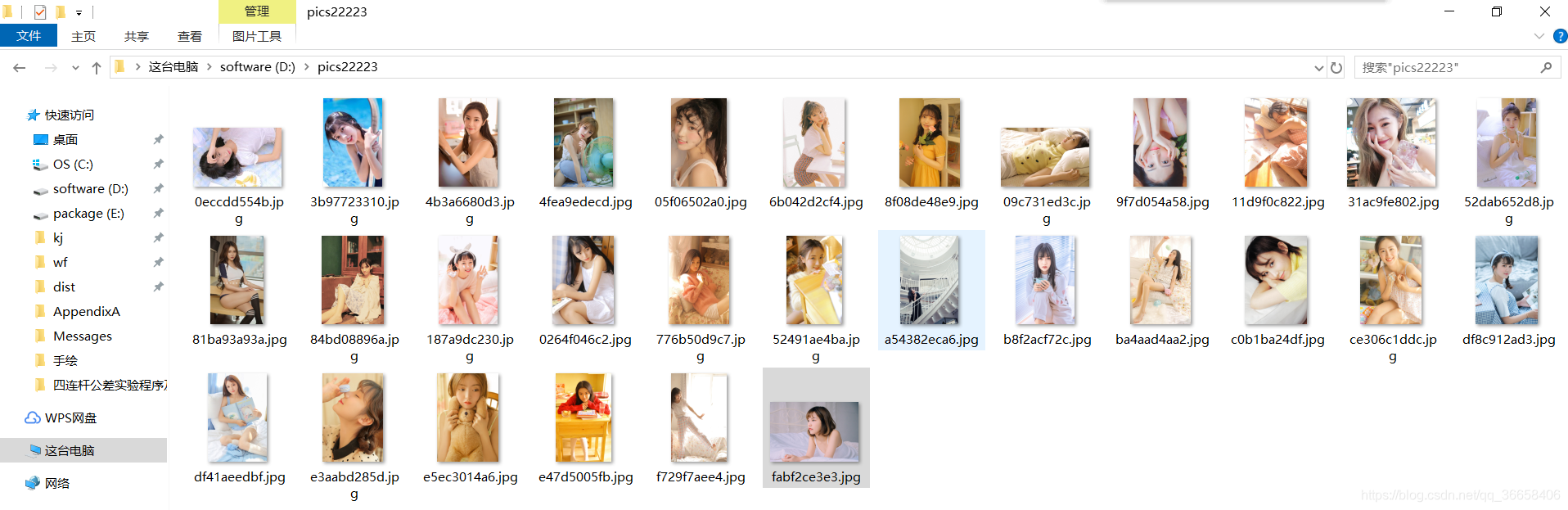
打开cmd控制台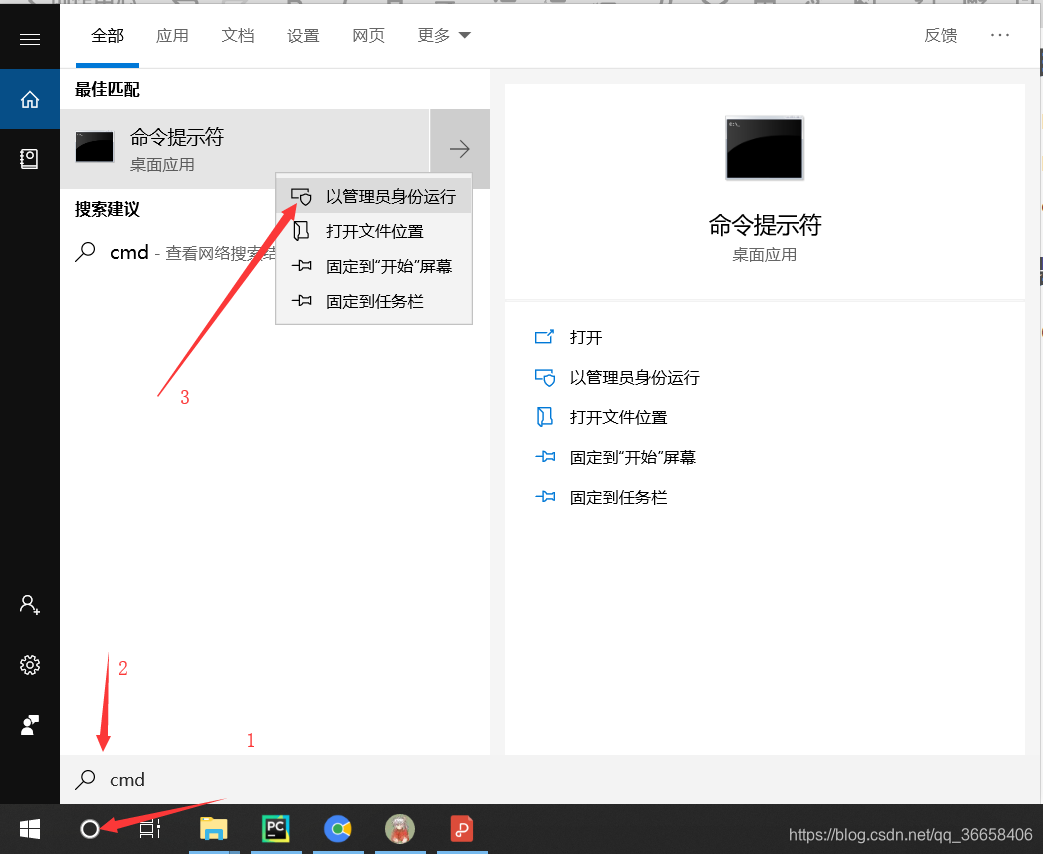
在控制台分别输入以下代码:
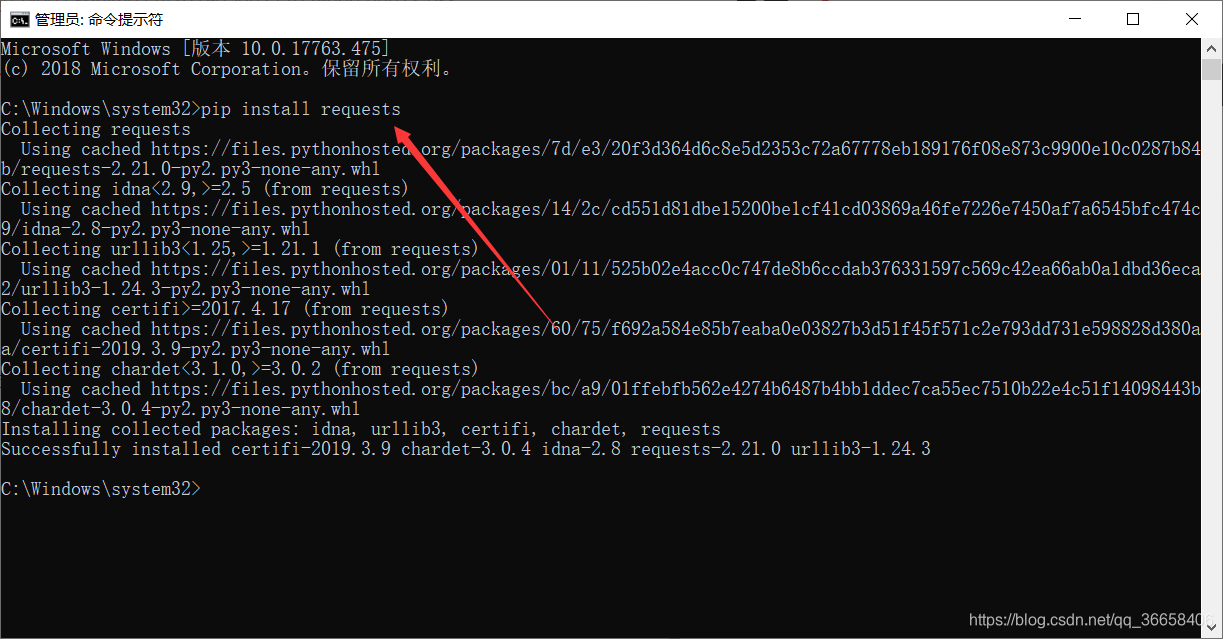
pip install requests
pip install pyquery
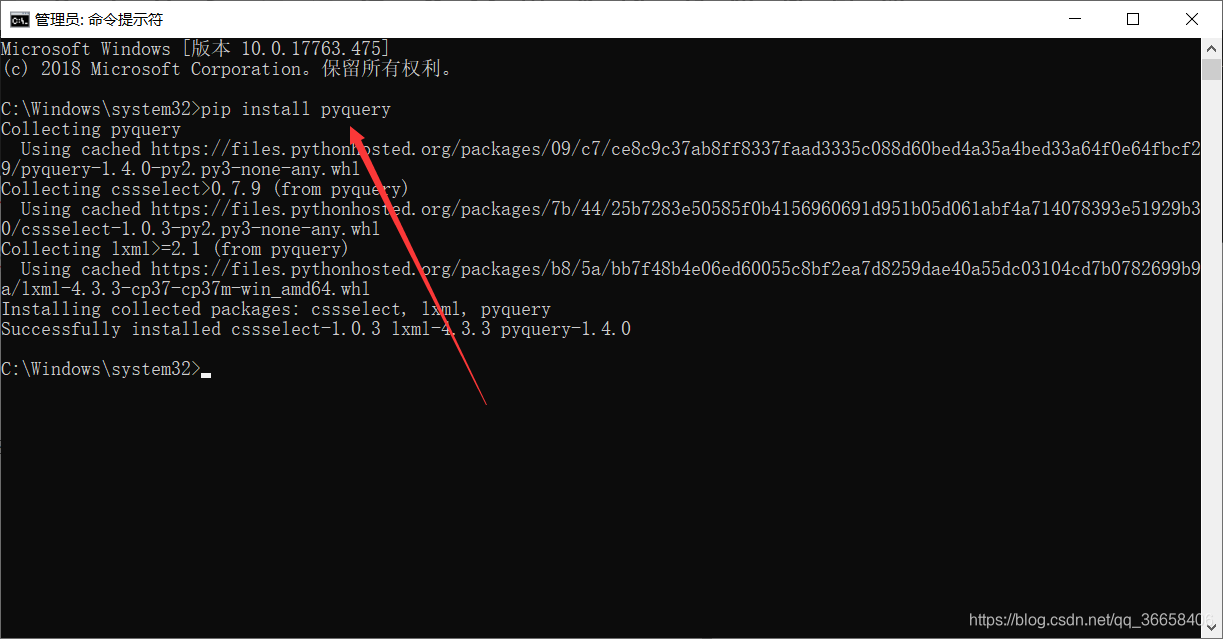
其中,os库为Python3内置库,不需要安装,至此,准备工作完成。
打开pycharm>file>settings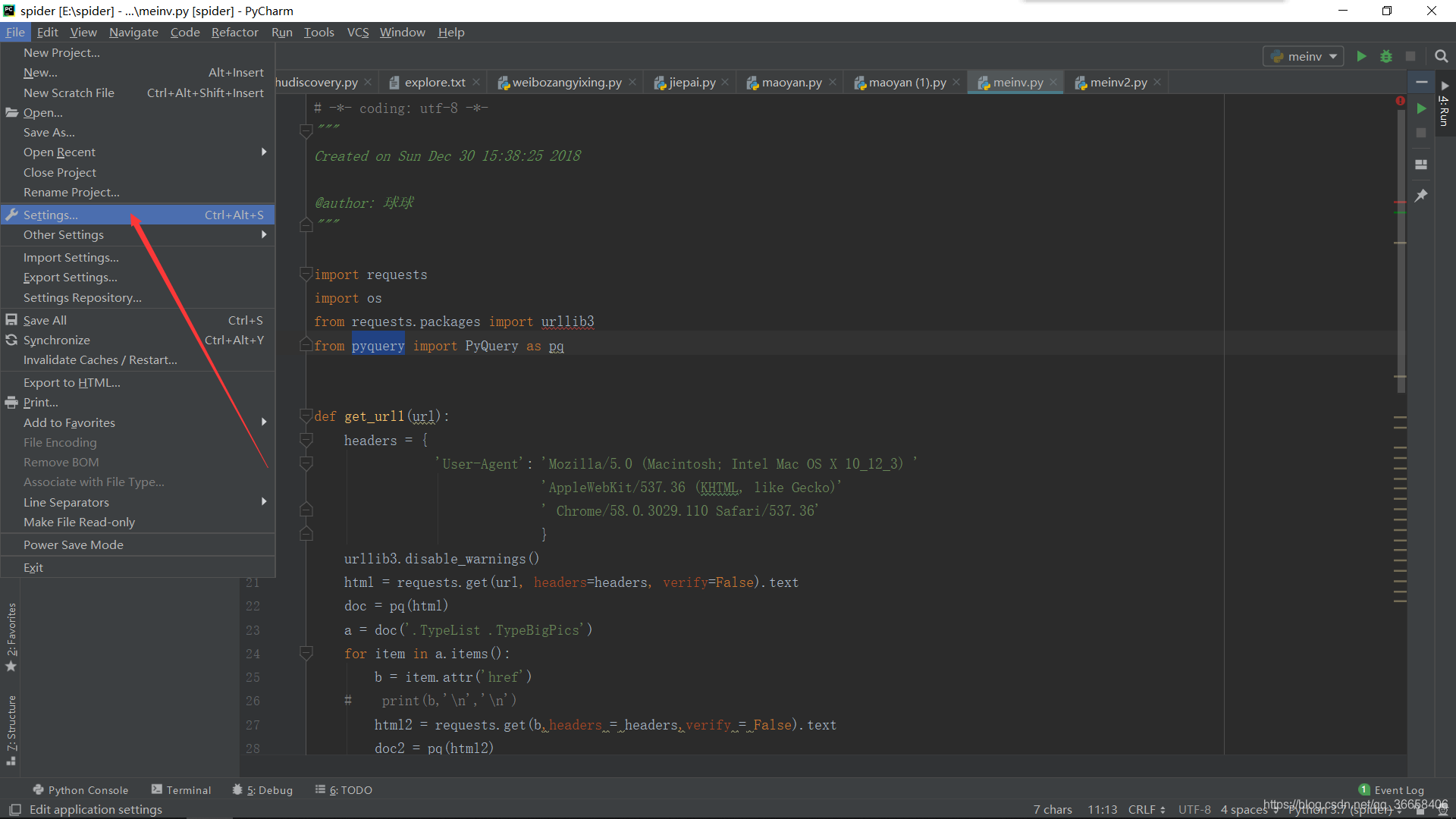
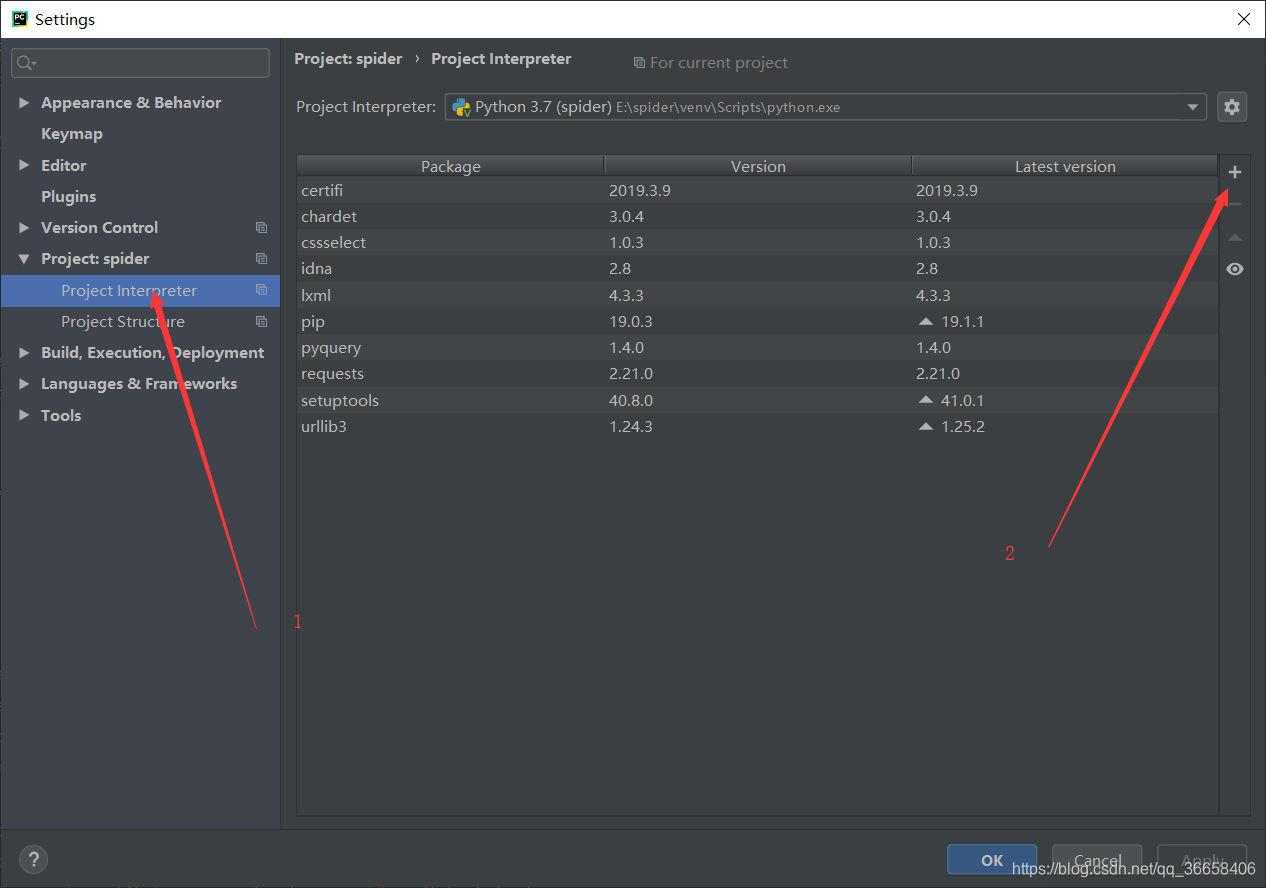
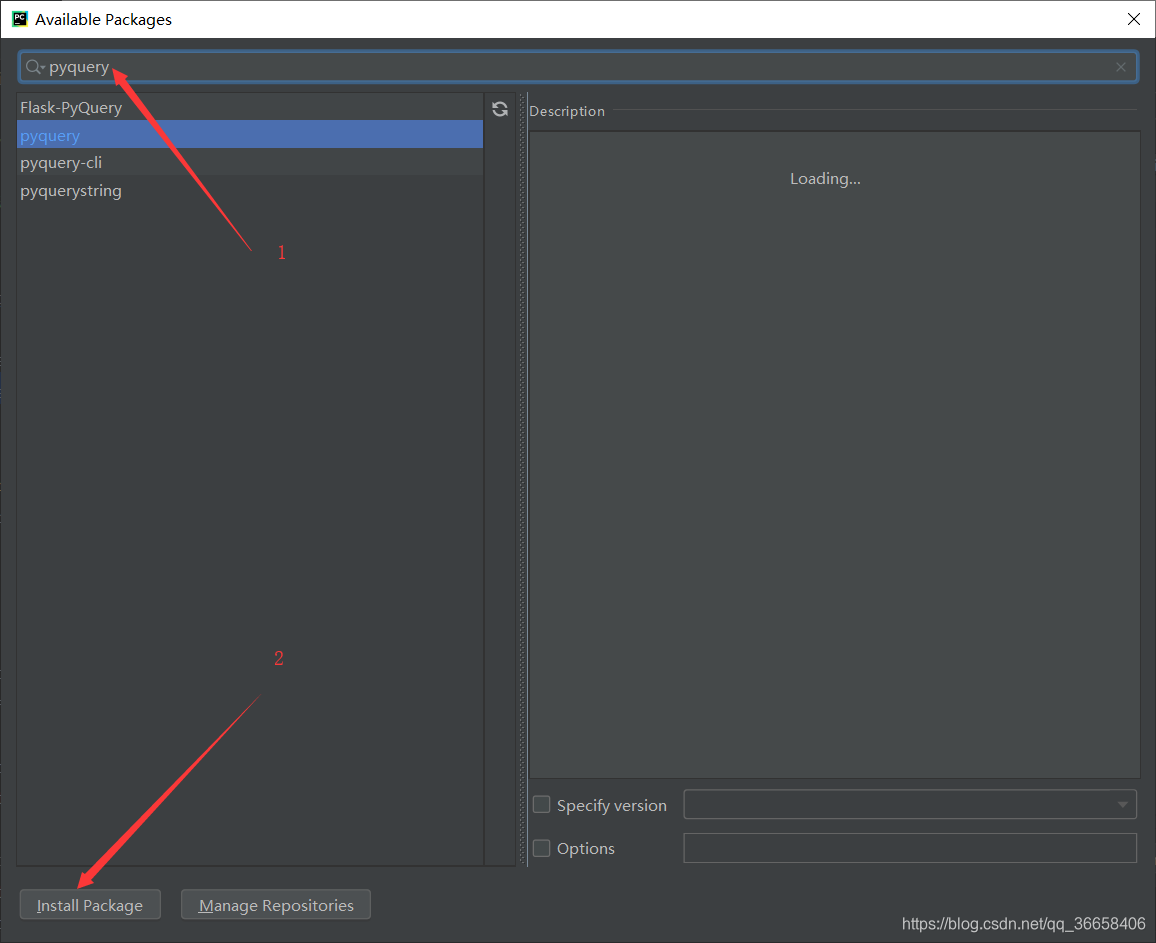
将所需库安装即可,至此,准备工作完成。
首先先确定目标:优美图库国内类别http://www.umei.cc/p/gaoqing/cn/
然后,观察规律:
第一页URL为http://www.umei.cc/p/gaoqing/cn
点下一页URL为http://www.umei.cc/p/gaoqing/cn/2.htm
再点下一页URL为http://www.umei.cc/p/gaoqing/cn/3.htm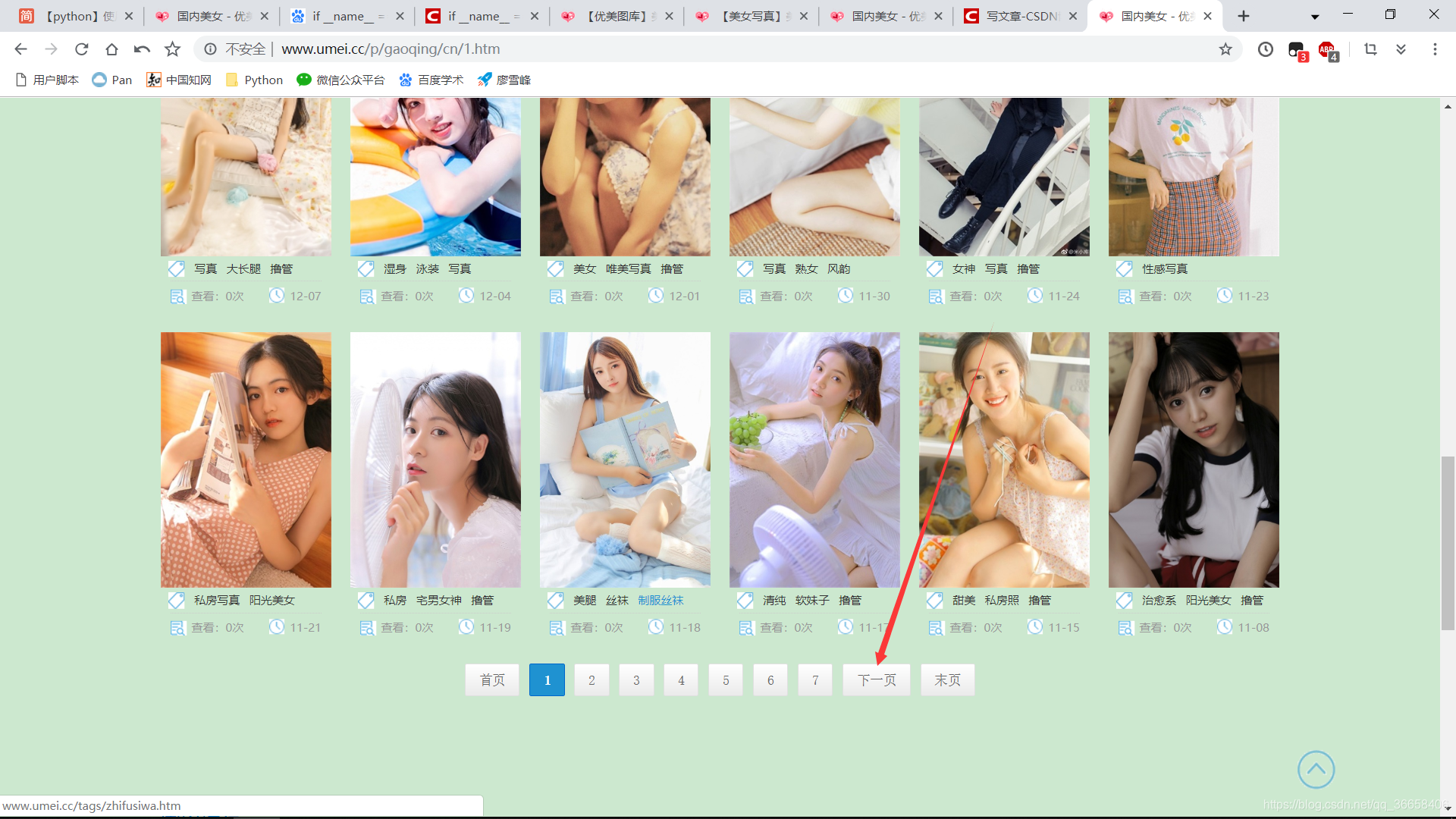
。。。。。。
然后再点击第一页发现网址变成了http://www.umei.cc/p/gaoqing/cn/1.htm
所以,我们就得到了屠龙技。代码如下:
# 控制代码运行过程,在文件作为脚本时才会被执行,而import到其他脚本中是不会被执行的
if __name__ == '__main__':
z = 1
url = 'http://www.umei.cc/p/gaoqing/cn/' # 初始目标URL
for i in range(z, z+1): # z+1可以换成z+n (n=1,2,3......)
url1 = url+str(i)+'.htm'
print(url1)
get_url1(url1) # 调用get_url1函数获取图片
然后我们还有找规律,我们点开第一页第一套图
为了简便,我们就爬取每页各个套图里的第一张图片,当然也可以爬取更多的图。我们可以发现各个套图里的第一张图片URL根本没有规律,所以,我们这是就要借助pyquery网页解析库啦。
我用的是谷歌浏览器,打开开发者工具,根据图片找到套图里第一张图片的链接,可以多找几张,你会发现他们好像有规律,我们只要搞到红框框里的链接就好啦。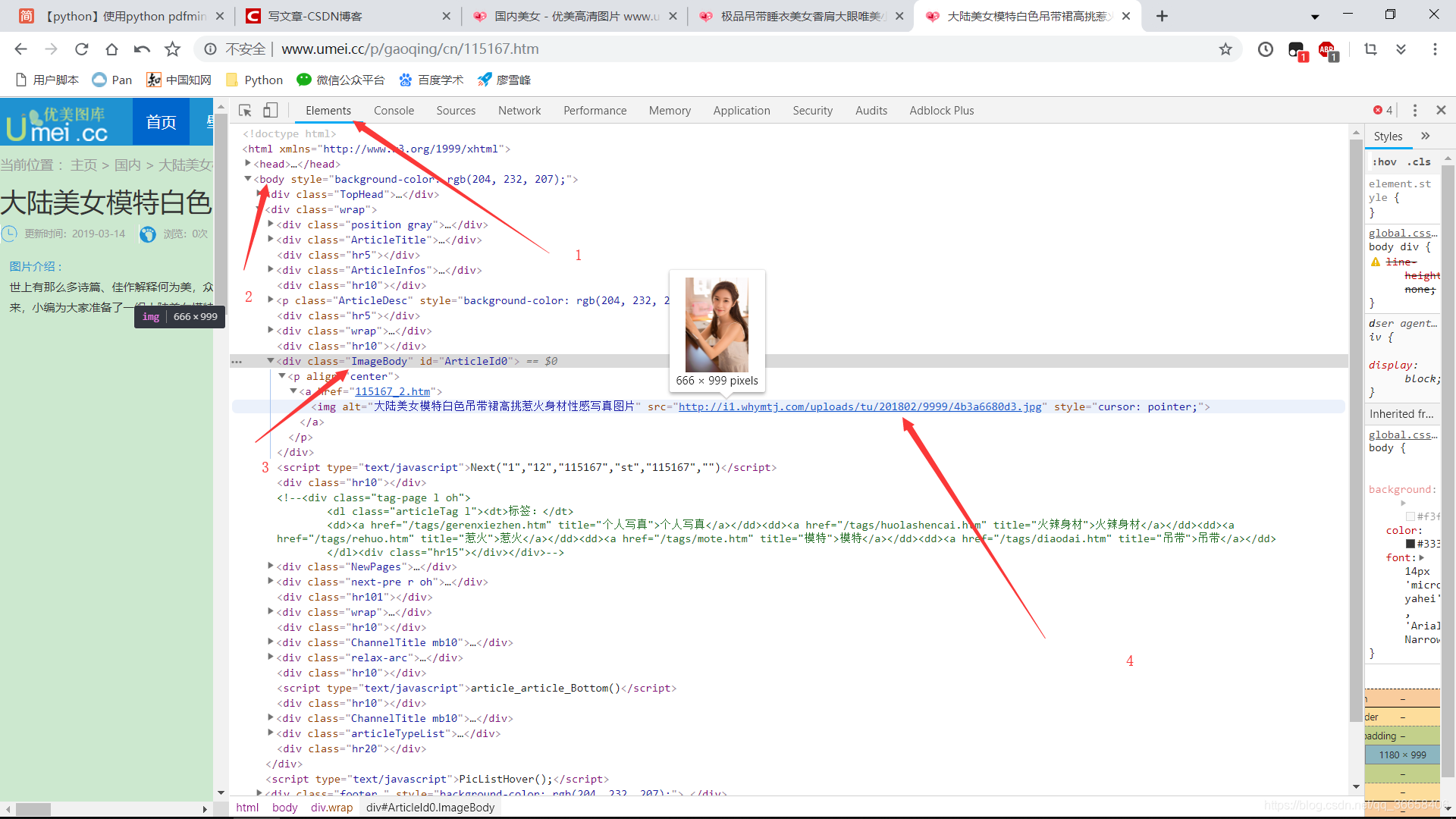
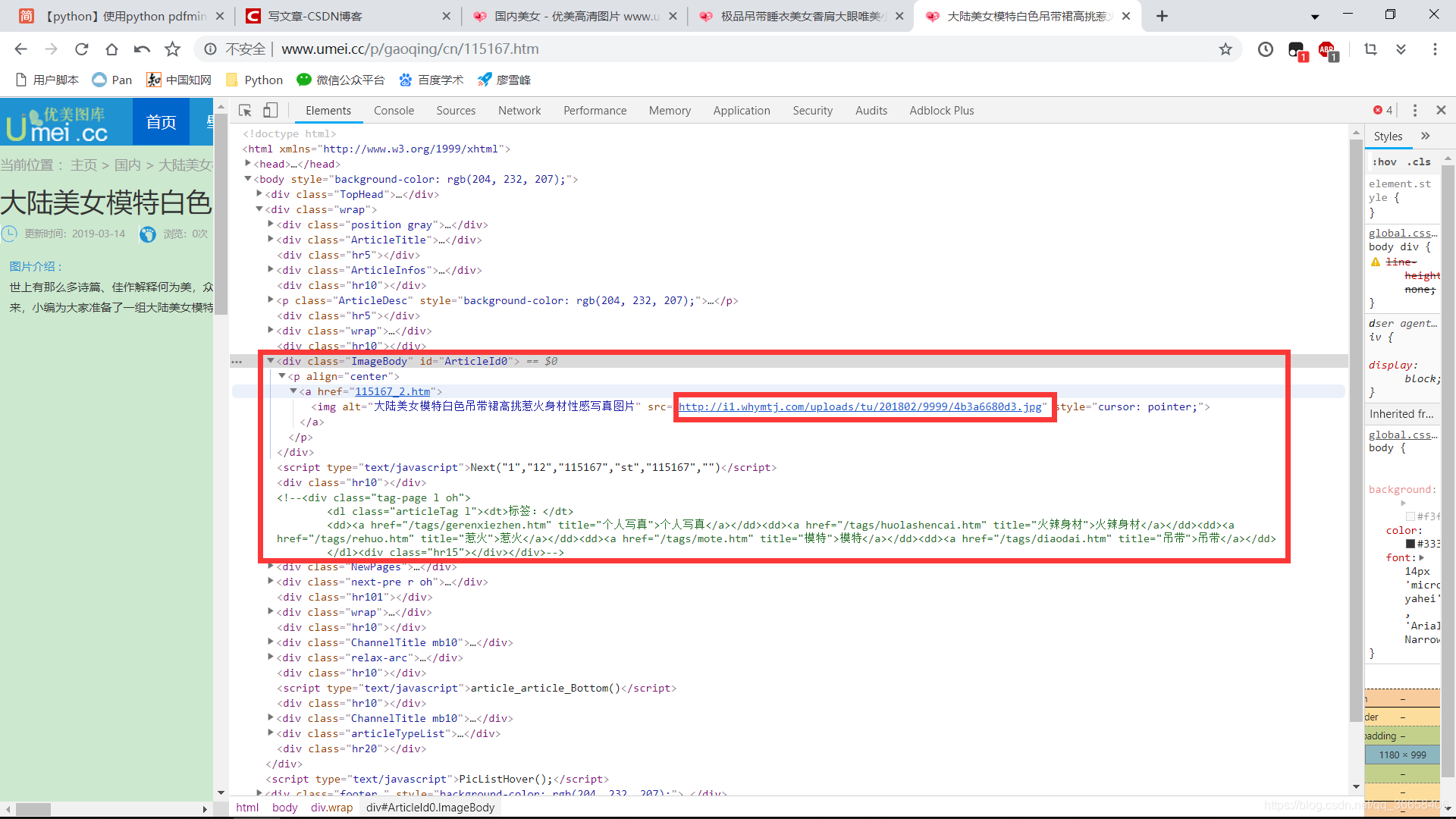
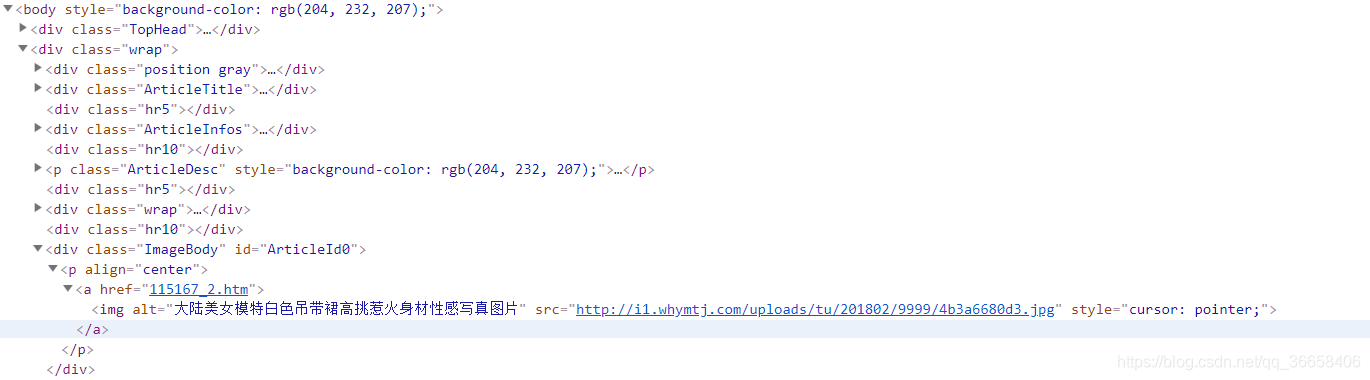
所以函数get_url1代码如下
def get_url1(url):
# 模拟浏览器,不用改,几乎固定
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/58.0.3029.110 Safari/537.36'
}
urllib3.disable_warnings() # 预警作用
html = requests.get(url, headers=headers, verify=False).text # 获得elements里的所有代码
doc = pq(html) # 解析代码
a = doc('.TypeList .TypeBigPics')
for item in a.items():
b = item.attr('href') # 获得herf里的所有代码
# print(b,'n','n')
html2 = requests.get(b,headers = headers,verify = False).text
doc2 = pq(html2)
c = doc2('.ImageBody img') # 获得ImageBody img里的代码
for item2 in c.items():
d = item2.attr('src') # 获得src里的链接
print(d)
# 保存文件
root = "D://pics22223//" # 根目录
path=root+d.split('/')[-1]
# 根目录加上url中以反斜杠分割的最后一部分,即可以以图片原来的名字存储在本地
try:
if not os.path.exists(root): # 判断当前根目录是否存在
os.mkdir(root) # 创建根目录
if not os.path.exists(path): # 判断文件是否存在
r=requests.get(d)
with open(path,'wb')as f:
f.write(r.content)
f.close()
print("文件保存成功",'n','n')
else:
print("文件已存在")
except:
print("爬取失败")
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 30 15:38:25 2018
@author: 球球
"""
import requests
import os
from requests.packages import urllib3
from pyquery import PyQuery as pq
def get_url1(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) '
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/58.0.3029.110 Safari/537.36'
}
urllib3.disable_warnings()
html = requests.get(url, headers=headers, verify=False).text
doc = pq(html)
a = doc('.TypeList .TypeBigPics')
for item in a.items():
b = item.attr('href')
# print(b,'n','n')
html2 = requests.get(b,headers = headers,verify = False).text
doc2 = pq(html2)
c = doc2('.ImageBody img')
for item2 in c.items():
d = item2.attr('src')
print(d)
root = "D://pics22223//" # 根目录
path=root+d.split('/')[-1]
# 根目录加上url中以反斜杠分割的最后一部分,即可以以图片原来的名字存储在本地
try:
if not os.path.exists(root): # 判断当前根目录是否存在
os.mkdir(root) # 创建根目录
if not os.path.exists(path): # 判断文件是否存在
r=requests.get(d)
with open(path,'wb')as f:
f.write(r.content)
f.close()
print("文件保存成功",'n','n')
else:
print("文件已存在")
except:
print("爬取失败")
if __name__ == '__main__':
z = 1
url = 'http://www.umei.cc/p/gaoqing/cn/'
for i in range(z, z+1):
url1 = url+str(i)+'.htm'
print(url1)
get_url1(url1)
有问题请加群:774515086
望海潮
秦观
纤云弄巧,飞星传恨,银汉迢迢暗度。金风玉露一相逢,便胜却人间无数。
柔情似水,佳期如梦,忍顾鹊桥归路。两情若是久长时,又岂在朝朝暮暮。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
