社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本人得到公司交代的任务爬取https://www.hltv.org/matches这个网站的logo图标。
初次学习接触python爬虫,如有错误!欢迎指出。
我借鉴于https://blog.csdn.net/IllegalName/article/details/77366508#commentsedit这篇文章做出的。
如有侵权,联系我立马删除。
第一次写博客,请各位大神见谅!
Python3常用的爬虫第三方插件有requests,urllib.request等。这里主要介绍使用requests抓取网页上的图片,该方法只针对静态网页,不考虑js动态加载的网页。
预备知识:
requests模块的基本了解,包括get,post等方法和status_code,history等属性。
熟练使用BeautifulSoup(美丽汤)进行文本定位、筛选,常用方法有find_all,select等。
基本的文件流操作,如文件夹是否存在的判断,新建文件夹等。
requests的write下载图片操作
操作开始:
这里以HLTV(https://www.hltv.org/matches)为例,抓取网页上的战队logo图标。
抓图的基本流程就是:
requests发送网页请求 --> 使用get获取response --> 利用BeautifulSoup对response进行文本筛选,抓取图片链接 ---> 新建一个图片存放的文件夹 ---> urlretrieve下载图片到文件夹
按F12分析网页结构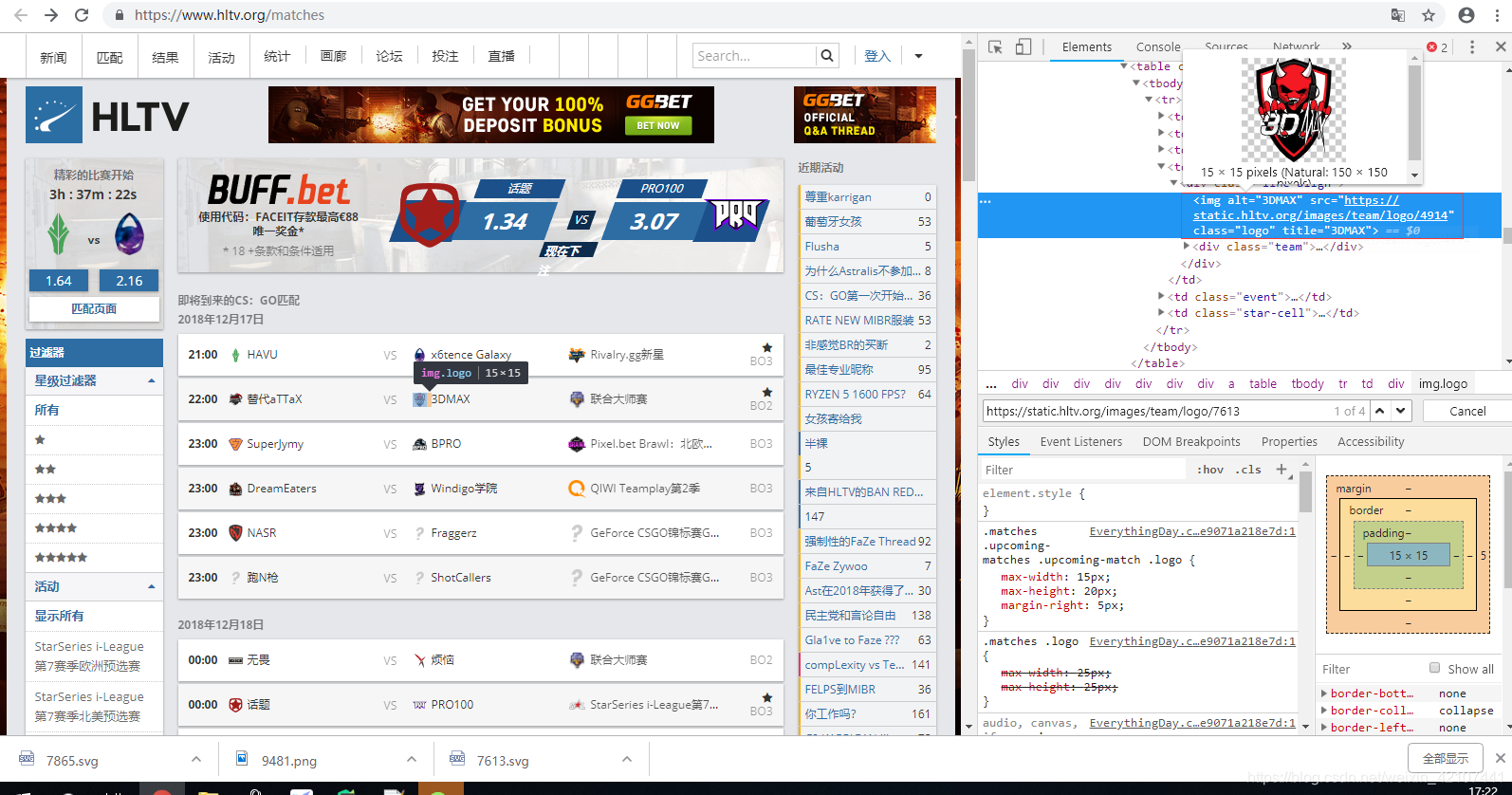
图片定位到的文本信息类似于上图红框所示:
<img alt="3DMAX" src="https://static.hltv.org/images/team/logo/4914" class="logo" title="3DMAX">
我们只关心图片链接信息(标红部分),其他的信息都要过滤掉。
下面上具体代码
import requests
from bs4 import BeautifulSoup
import os
import time
url = 'https://www.hltv.org/matches'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'} #谷歌浏览器避免访问受限的请求头
response = requests.get(url, headers=headers) # 使用headers避免访问受限
soup = BeautifulSoup(response.content, 'html.parser')
items = soup.find_all('img')
folder_path = './photo/'
if os.path.exists(folder_path) == False: # 判断文件夹是否已经存在
os.makedirs(folder_path) # 创建文件夹
for index, item in enumerate(items):
s = 'https' #定义筛选条件
b = '.png' #定义图片后缀
if item:
html = item.get('src')
result = s in html
if result:
abc = b in html
if abc:
html = requests.get(item.get('src')) # get函数获取图片链接地址,requests发送访问请求
img_name = folder_path + str(index + 1) + '.png' #如果源文件为png则保存为png图片文件
with open(img_name, 'wb') as file: # 以byte形式将图片数据写入
file.write(html.content)
file.flush()
file.close() # 关闭文件
print('第%d张图片下载完成' % (index + 1))
time.sleep(1) # 自定义延时
else:
html = requests.get(item.get('src')) # get函数获取图片链接地址,requests发送访问请求
img_name = folder_path + str(index + 1) + '.svg' #如果源文件没有图片类型则保存为svg图片文件
with open(img_name, 'wb') as file: # 以byte形式将图片数据写入
file.write(html.content)
file.flush()
file.close() # 关闭文件
print('第%d张图片下载完成' % (index + 1))
time.sleep(1) # 自定义延时
else:
print("爬取失败")
print('抓取已完成')
效果图:
爬取失败是因为我添加了判断条件剔除掉不需要的图片文件。
有错误或者有更好的方式欢迎指出相互讨论相互学习~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
