社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
通过Redis-cli命令行界面访问到Redis服务器,然后使用info命令获取所有与Redis服务相关的信息,其中比较重要的2部分性能指标是memory和stats。
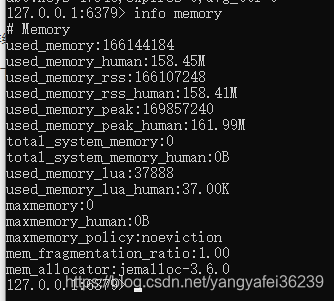
上图中used_memory 字段数据表示的是:由Redis分配器分配的内存总量,以字节(byte)为单位。 其中used_memory_human上的数据和used_memory是一样的值,它以M为单位显示,仅为了方便阅读。
used_memory是Redis使用的内存总量,它包含了实际缓存占用的内存和Redis自身运行所占用的内存(如元数据、lua)。它是由Redis使用内存分配器分配的内存,所以这个数据并没有把内存碎片浪费掉的内存给统计进去。
其他字段代表的含义,都以字节为单位:
因内存交换引起的性能问题
内存使用率是Redis服务最关键的一部分。如果一个Redis实例的内存使用率超过可用最大内存 (used_memory > 可用最大内存),那么操作系统开始进行内存与swap空间交换,把内存中旧的或不再使用的内容写入硬盘上(硬盘上的这块空间叫Swap分区),以便腾出新的物理内存给新页或活动页(page)使用。
在硬盘上进行读写操作要比在内存上进行读写操作,时间上慢了近5个数量级,内存是0.1μs单位、而硬盘是10ms。如果Redis进程上发生内存交换,那么Redis和依赖Redis上数据的应用会受到严重的性能影响。 通过查看used_memory指标可知道Redis正在使用的内存情况,如果used_memory>可用最大内存,那就说明Redis实例正在进行内存交换或者已经内存交换完毕。管理员根据这个情况,执行相对应的应急措施。
跟踪内存使用率
若是在使用Redis期间没有开启rdb快照或aof持久化策略,那么缓存数据在Redis崩溃时就有丢失的危险。因为当Redis内存使用率超过可用内存的95%时,部分数据开始在内存与swap空间来回交换,这时就可能有丢失数据的危险。
当开启并触发快照功能时,Redis会fork一个子进程把当前内存中的数据完全复制一份写入到硬盘上。因此若是当前使用内存超过可用内存的45%时触发快照功能,那么此时进行的内存交换会变的非常危险(可能会丢失数据)。 倘若在这个时候实例上有大量频繁的更新操作,问题会变得更加严重。
通过减少Redis的内存占用率,来避免这样的问题,或者使用下面的技巧来避免内存交换发生:
在info信息里的total_commands_processed字段显示了Redis服务处理命令的总数,其命令都是从一个或多个Redis客户端请求过来的。Redis每时每刻都在处理从客户端请求过来的命令,它可以是Redis提供的140种命令的任意一个。 total_commands_processed字段的值是递增的,比如Redis服务分别处理了client_x请求过来的2个命令和client_y请求过来的3个命令,那么命令处理总数(total_commands_processed)就会加上5。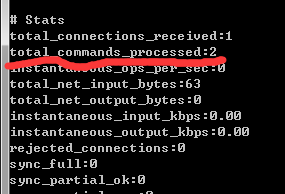
分析命令处理总数,诊断响应延迟。
在Redis实例中,跟踪命令处理总数是解决响应延迟问题最关键的部分,因为Redis是个单线程模型,客户端过来的命令是按照顺序执行的。比较常见的延迟是带宽,通过千兆网卡的延迟大约有200μs。倘若明显看到命令的响应时间变慢,延迟高于200μs,那可能是Redis命令队列里等待处理的命令数量比较多。 如上所述,延迟时间增加导致响应时间变慢可能是由于一个或多个慢命令引起的,这时可以看到每秒命令处理数在明显下降,甚至于后面的命令完全被阻塞,导致Redis性能降低。要分析解决这个性能问题,需要跟踪命令处理数的数量和延迟时间。
比如可以写个脚本,定期记录total_commands_processed的值。当客户端明显发现响应时间过慢时,可以通过记录的total_commands_processed历史数据值来判断命理处理总数是上升趋势还是下降趋势,以便排查问题。
使用命令处理总数解决延迟时间增加。
通过与记录的历史数据比较得知,命令处理总数确实是处于上升或下降状态,那么可能是有2个原因引起的:
Redis的延迟数据是无法从info信息中获取的。倘若想要查看延迟时间,可以用 Redis-cli工具加–latency参数运行,如:
Redis-cli --latency -h 127.0.0.1 -p 6379
其host和port是Redis实例的ip及端口。由于当前服务器不同的运行情况,延迟时间可能有所误差,通常1G网卡的延迟时间是200μs。
以毫秒为单位测量Redis的响应延迟时间,楼主本机的延迟是180μs:
跟踪Redis延迟性能
Redis之所以这么流行的主要原因之一就是低延迟特性带来的高性能,所以说解决延迟问题是提高Redis性能最直接的办法。拿1G带宽来说,若是延迟时间远高于200μs,那明显是出现了性能问题。 虽然在服务器上会有一些慢的IO操作,但Redis是单核接受所有客户端的请求,所有请求是按良好的顺序排队执行。因此若是一个客户端发过来的命令是个慢操作,那么其他所有请求必须等待它完成后才能继续执行。
1. 使用延迟命令提高性能
一旦确定延迟时间是个性能问题后,这里有几个办法可以用来分析解决性能问题。

2. 监控客户端的连接
因为Redis是单线程模型(只能使用单核),来处理所有客户端的请求, 但由于客户端连接数的增长,处理请求的线程资源开始降低分配给单个客户端连接的处理时间,这时每个客户端需要花费更多的时间去等待Redis共享服务的响应。这种情况下监控客户端连接数是非常重要的,因为客户端创建连接数的数量可能超出预期的数量,也可能是客户端端没有有效的释放连接。在Redis-cli工具中输入info clients可以查看到当前实例的所有客户端连接信息。如下图,第一个字段(connected_clients)显示当前实例客户端连接的总数: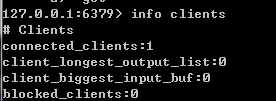
Redis默认允许客户端连接的最大数量是10000。若是看到连接数超过5000以上,那可能会影响Redis的性能。倘若一些或大部分客户端发送大量的命令过来,这个数字会低的多。
3.限制客户端连接数
自Redis2.6以后,允许使用者在配置文件(Redis.conf)maxclients属性上修改客户端连接的最大数,也可以通过在Redis-cli工具上输入config set maxclients 去设置最大连接数。根据连接数负载的情况,这个数字应该设置为预期连接数峰值的110%到150之间,若是连接数超出这个数字后,Redis会拒绝并立刻关闭新来的连接。
4.加强内存管理
较少的内存会引起Redis延迟时间增加。如果Redis占用内存超出系统可用内存,操作系统会把Redis进程的一部分数据,从物理内存交换到硬盘上,内存交换会明显的增加延迟时间。关于怎么监控和减少内存使用,可查看used_memory介绍章节。
info信息中的mem_fragmentation_ratio给出了内存碎片率的数据指标,它是由操系统分配的内存除以Redis分配的内存得出:
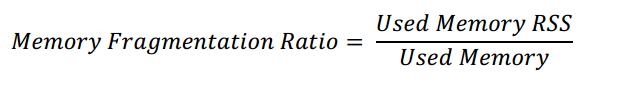
used_memory和used_memory_rss数字都包含的内存分配有:
used_memory_rss的rss是Resident Set Size的缩写,表示该进程所占物理内存的大小,是操作系统分配给Redis实例的内存大小。除了用户定义的数据和内部开销以外,used_memory_rss指标还包含了内存碎片的开销,内存碎片是由操作系统低效的分配/回收物理内存导致的。
理解资源性能
跟踪内存碎片率对理解Redis实例的资源性能是非常重要的。内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低,也说明redis没有发生内存交换。但如果内存碎片率超过1.5,那就说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。若是内存碎片率低于1的话,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。内存交换会引起非常明显的响应延迟,可查看used_memory介绍章节。
用内存碎片率预测性能问题
倘若内存碎片率超过了1.5,那可能是操作系统或Redis实例中内存管理变差的表现。下面有3种方法解决内存管理变差的问题,并提高Redis性能:
重启Redis服务器:如果内存碎片率超过1.5,重启Redis服务器可以让额外产生的内存碎片失效并重新作为新内存来使用,使操作系统恢复高效的内存管理。
限制内存交换: 如果内存碎片率低于1,Redis实例可能会把部分数据交换到硬盘上。内存交换会严重影响Redis的性能,所以应该增加可用物理内存或减少实Redis内存占用。 可查看used_memory章节的优化建议。
修改内存分配器:
Redis支持glibc’s malloc、jemalloc11、tcmalloc几种不同的内存分配器,每个分配器在内存分配和碎片上都有不同的实现。不建议普通管理员修改Redis默认内存分配器,因为这需要完全理解这几种内存分配器的差异,也要重新编译Redis。这个方法更多的是让其了解Redis内存分配器所做的工作,当然也是改善内存碎片问题的一种办法。
参考连接:https://www.cnblogs.com/mushroom/p/4738170.html
目前缓存的解决方案一般有两种:
在单独使用Ehcache或Redis时,可能会出现以下几个问题:
在遭遇问题1、2 时,很多人自然而然会想到使用 Redis 来缓存数据,因此就难以避免的导致了问题3的发生。当发生问题 3 时,又有很多人想到 Redis 的集群,通过集群来降低缓存服务的压力,特别是带宽压力。
但其实,这个时候的 Redis 上的数据量并不一定大,仅仅是数据的吞吐量大而已。
简要说明:
ehcache是内存缓存,在本地jvm内存中,十分高效,但是如果缓存数据都存在jvm中,内存是不够用的,于是使用到了redis数据库缓存,redis是键值对数据库,也比较高效,如果仅用redis做缓存,则存在频繁的网络IO读写,因为一般的会将redis部署在一个单独的服务器上,或者是集群部署。所以我们结合两者的特性,优先使用ehcache缓存,当ehcache中没有数据时,再向redis中取,redis中取到数据后,并把数据再次存到ehcache缓存中。总体的设计就是讲ehcache的失效时间设置比较短,将redis缓存失效时间设置的比较长,这样就可以充分发挥两者的特性了。
二级缓存机制: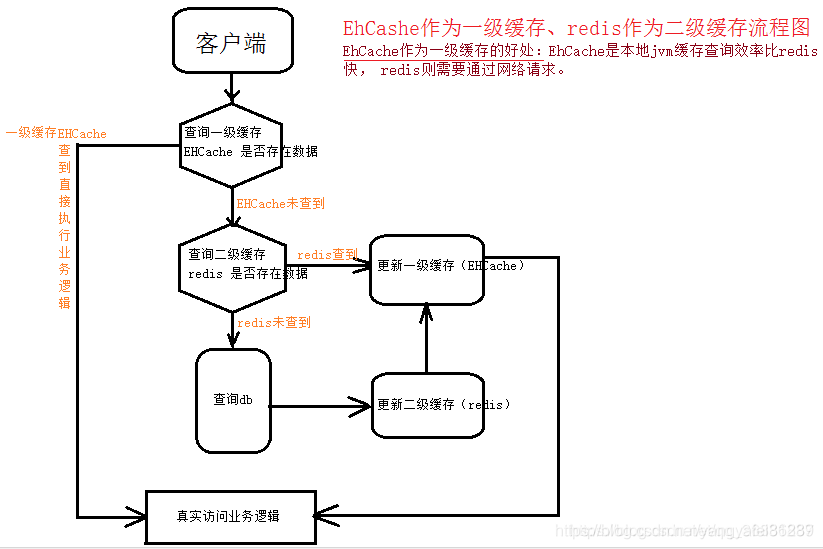
<!--开启 cache 缓存 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!-- ehcache缓存 -->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
</dependency>
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd">
<!--
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="java.io.tmpdir/Tmp_EhCache"/>
<!--defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。-->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大数目
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
overflowToDisk:是否保存到磁盘,当系统当机时
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
maxElementsOnDisk:硬盘最大缓存个数。
diskPersistent:是否缓存虚拟机重启期数,默认false
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
-->
<defaultCache maxElementsInMemory="1000" eternal="true"
timeToIdleSeconds="120" timeToLiveSeconds="120" overflowToDisk="true"
diskSpoolBufferSizeMB="30" maxElementsOnDisk="10000000"
diskPersistent="true" diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
<!-- demo缓存 -->
<cache name="userCache" maxElementsInMemory="1000" eternal="false"
timeToIdleSeconds="120" timeToLiveSeconds="300" overflowToDisk="true"
diskSpoolBufferSizeMB="30" maxElementsOnDisk="10000000" diskPersistent="false"
diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU">
<cacheEventListenerFactory
class="net.sf.ehcache.distribution.RMICacheReplicatorFactory"/>
<!-- 用于在初始化缓存,以及自动设置 -->
<bootstrapCacheLoaderFactory
class="net.sf.ehcache.distribution.RMIBootstrapCacheLoaderFactory"/>
</cache>
</ehcache>
配置缓存的类型和加载配置文件的位置:
#ehcache配置
spring.cache.ehcache.config=classpath:ehcache.xml
spring.cache.type = ehcache
开启缓存开关并且初始化缓存管理器
启动主类上添加@EnableCaching注解
添加二级缓存Redis相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--使用redis依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
#redis配置
#Redis服务器地址
spring.redis.host=127.0.0.1
#Redis服务器连接端口
spring.redis.port=6379
#Redis服务器密码
spring.redis.password=
#Redis数据库索引(默认为0)
spring.redis.database=0
#连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=50
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=3000
#连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=20
#连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=2
#连接超时时间(毫秒)
spring.redis.timeout=3000
package com.test.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.ehcache.EhCacheCacheManager;
import org.springframework.stereotype.Component;
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager;
import net.sf.ehcache.Element;
@Component
public class EhCacheUtils {
// @Autowired
// private CacheManager cacheManager;
@Autowired
private EhCacheCacheManager ehCacheCacheManager;
// 添加本地缓存 (相同的key 会直接覆盖)
public void put(String cacheName, String key, Object value) {
Cache cache = ehCacheCacheManager.getCacheManager().getCache(cacheName);
Element element = new Element(key, value);
cache.put(element);
}
// 获取本地缓存
public Object get(String cacheName, String key) {
Cache cache = ehCacheCacheManager.getCacheManager().getCache(cacheName);
Element element = cache.get(key);
return element == null ? null : element.getObjectValue();
}
public void remove(String cacheName, String key) {
Cache cache = ehCacheCacheManager.getCacheManager().getCache(cacheName);
cache.remove(key);
}
}
package com.autoai.weatheraqiserver.weather.util;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
/**
* @Author:
* @Date: 2019/11/12 12:54
* @Description: redis操作工具类.(基于RedisTemplate)
*/
@Component
public class RedisUtil {
private static Logger LOGGER = LoggerFactory.getLogger(RedisUtil.class);
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* 读取缓存
*
* @param key
* @return
*/
public String get(final String key) {
return redisTemplate.opsForValue().get(key);
}
/**
* 写入缓存
*/
public boolean set(final String key, String value) {
boolean result = false;
try {
redisTemplate.opsForValue().set(key, value);
result = true;
} catch (Exception e) {
LOGGER.error("写入redis异常", e);
}
return result;
}
}
package com.test.service;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.alibaba.fastjson.JSONObject;
import com.itmayiedu.entity.Users;
import com.itmayiedu.mapper.UserMapper;
@Service
public class UserService {
@Autowired
private EhCacheUtils ehCacheUtils;
private static final String CACHENAME_USERCACHE = "userCache";
@Autowired
private RedisService redisService;
@Autowired
private UserMapper userMapper;
public Users getUser(Long id) {
// 根据规则获取key
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()
+ "-id:" + id;
// 1.先查找一级缓存(本地缓存),如果本地缓存有数据直接返回
Users ehUser = (Users) ehCacheUtils.get(CACHENAME_USERCACHE, key);
if (ehUser != null) {
System.out.println("使用key:" + key + ",查询一级缓存 ehCache 获取到ehUser:" + JSONObject.toJSONString(ehUser));
return ehUser;
}
// 2. 如果本地缓存没有该数据,直接查询二级缓存(redis)
String redisUserJson = redisService.getString(key);
if (!StringUtils.isEmpty(redisUserJson)) {
// 将json 转换为对象(如果二级缓存redis中有数据直接返回二级缓存)
JSONObject jsonObject = new JSONObject();
Users user = jsonObject.parseObject(redisUserJson, Users.class);
// 更新一级缓存
ehCacheUtils.put(CACHENAME_USERCACHE, key, user);
System.out.println("使用key:" + key + ",查询二级缓存 redis 获取到ehUser:" + JSONObject.toJSONString(user));
return user;
}
// 3. 如果二级缓存redis中也没有数据,查询数据库
Users user = userMapper.getUser(id);
if (user == null) {
return null;
}
// 问题:如何保证二级缓存和一级缓存的失效失效一致? 一级缓存的有效时间减去二级缓存代码执行时间。
// 更新二级缓存
String userJson = JSONObject.toJSONString(user);
redisService.setString(key, userJson);
// 更新和一级缓存
ehCacheUtils.put(CACHENAME_USERCACHE, key, user);
System.out.println("使用key:" + key + ",一级缓存和二级都没有数据,直接查询db" + userJson);
return user;
}
}
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
