社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
之前介绍过用json格式爬取微博评论,但是json格式爬取的页面有一个很大的问题,就是只能爬取前一百页,因此这里介绍用beautiful soup库来爬取微博评论,这种方法对评论页数没有限制。
今天在这里介绍一下如何用beautifulsoup爬取某条微博下的评论
在这里我们介绍几个重要的对网页爬取和数据清洗有帮助的库:
requests库
Beautiful Soup库re库
requests库是爬虫的一个基础库:
r = request.get(url) : 可以获得该url链接的信息;
r.econding : 通过对头部的读取得出其编码
r.apparent_encodind : 该页面的实际编码
r.raise_for_status() : 访问该页面是否成功,若不成功则返回异常,因此一般该语句在try-except中出现
r.text : 返回该url的信息
里面的每个操作都已经介绍过了,请同学们自行理解~
def getXMLText(url):
headers = {
'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
'Cookie': '' #这里要自己用f12获取自己登陆的微博cookie
}
try:
r = requests.get(url , headers = headers)
r.raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
Beautiful Soup库俗称美丽汤,主要作用是将html的信息煲一锅汤,然后对信息进行处理:
soup = BeautifulSoup(html,“html.parser”) : 将信息放入soup中~
div = soup.find_all(‘div’,attrs={“class”:“item”}) : 将class 等于 item 的全部div生成一个列表返回到div中
第二个函数如果要获取别的信息只要对信息的需求进行修改就可以了~
re库是正则表达式库,其实和直接的爬虫没有特别大的关系,但是在爬取页面的过程中经常会使用到~
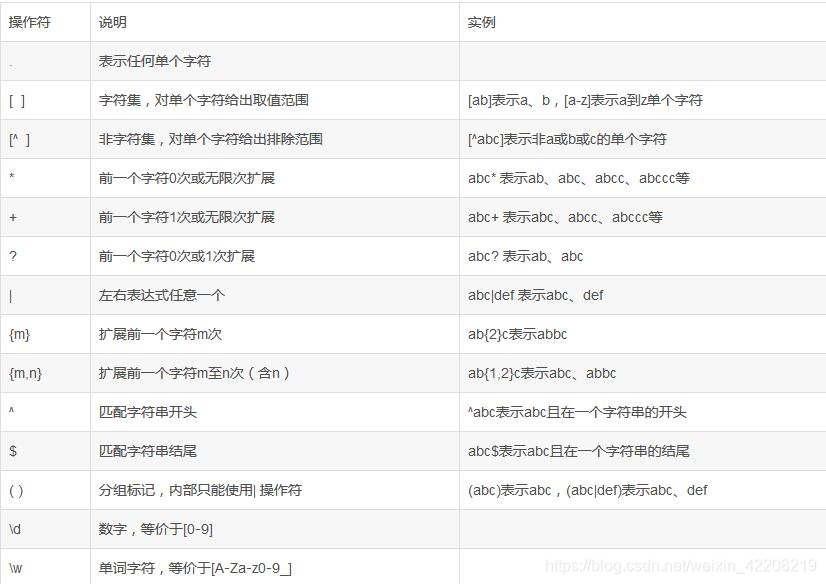
 然后我们就开始进行评论的爬取了,这里注意一个重要的链接:
然后我们就开始进行评论的爬取了,这里注意一个重要的链接:
https://weibo.cn/comment/C6oEHf5Ie?uid=xxxxx&page=0
这里C…e是该条微博的id,uid哪里的xxxxx是和用户相关的一个id,0代表其页数,以当前微博为例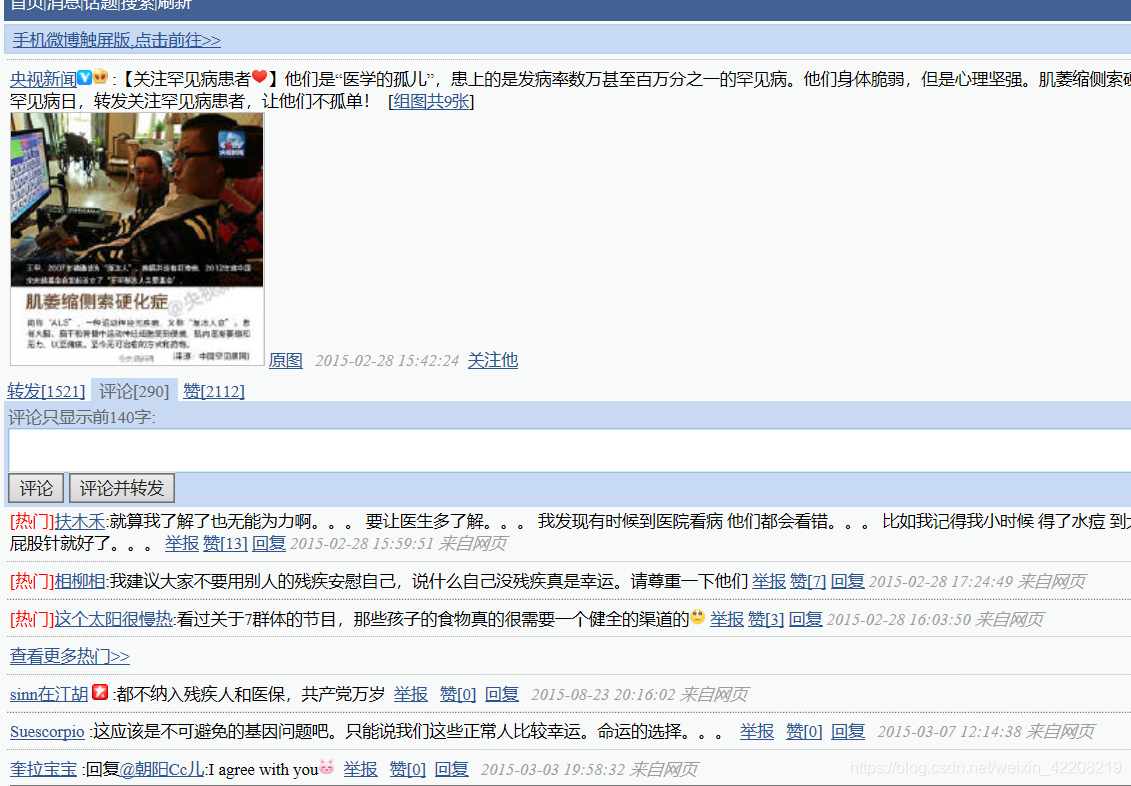
这里有最终的页数,这种爬取微博的方式不会限制只能爬取前100页。
查看页面的源代码,并将其格式化,可以找到其中某条评论的格式: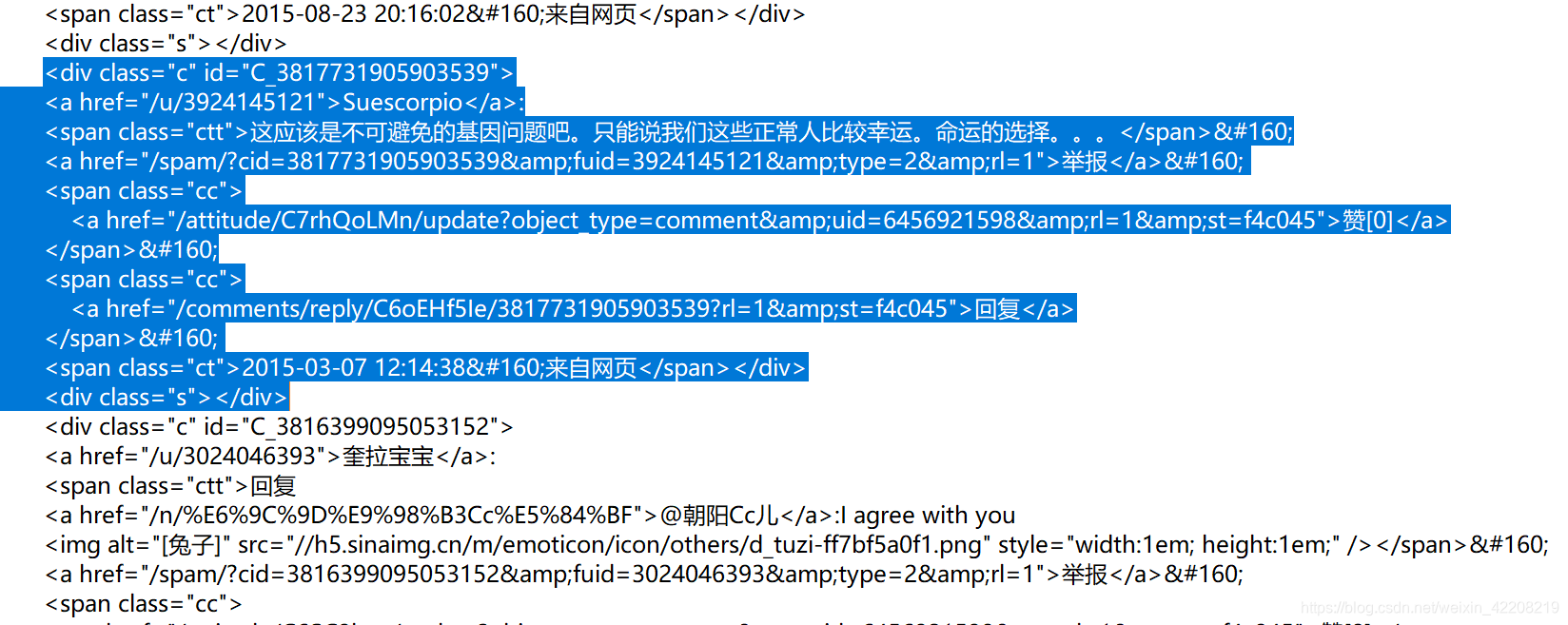
如图,根据蓝底标注的地方的格式,可以利用beautiful soup中的find_all函数对所要爬取的内容进行定位,然后利用re正则表达式库对数据进行选取。
这里注意要得到发评论人的性别与地区,就要在得到其微博id后进入:
https://weibo.cn/+id 页面,对当前人的信息进行爬取,所爬取的结果放入list列表中,最后写入目标文件。
下面附上用beautiful soup及re库爬取微博评论的代码:
getXMLText(url):代码前面有;
getInfo(ID):利用爬取到的id,得到当前微博用户的基本信息,因为爬取到的微博有的id格式不同,因此需要进行处理。通过该函数,可以得到用户的真实id,性别,地区,生日。有需要可以改变其功能~
def getInfo(ID):
# 得到真实id
if "/u" in ID:
id = ID.replace("/u/", "")
else:
id = ID.replace("/", "")
url = "https://weibo.cn/" + str(id)
xml = getXMLText(url)
soup = BeautifulSoup(xml, "xml")
id = re.compile(r"d{10}").search(str(soup))[0]
# 找到用户地址性别年龄
infourl = "https://weibo.cn/" + str(id) + "/info" # 爬取地区和性别
infohtml = getXMLText(infourl)
soup = BeautifulSoup(infohtml, "xml")
c = soup.find_all("div", attrs={"class": "c"})
sex = "未知"
addr = "未知"
birthday = "未知"
try:
for m in range(len(c)):
if "性别" in str(c[m]):
cc = c[m]
if "生日" in str(cc):
birthday = re.findall(r"[生日].*?[<]", str(cc))[0].replace("生日:", "").replace("<", "")
sex = re.findall(r"[性别].*?[<]", str(cc))[0].replace("性别:", "").replace("<", "")
addr = re.findall(r"[地区].*?[<]", str(cc))[0].replace("地区:", "").replace("<", "").split(" ")[0]
break;
if re.search(r"dddd-dd-dd$", str(birthday)):
print(birthday)
if re.findall(r"dddd", str(birthday))[0] != "0001":
birthday = 2019 - eval(re.findall(r"dddd", str(birthday))[0])
print(sex)
print(addr)
print(birthday)
return id,sex, addr, birthday
except:
return id,"未知","未知","未知"
getList(list,xml):爬取微博评论,id,评论内的表情,评论的时间,并调用getInfo(ID)函数得到用户的个人信息,并将结果放入list中~
def getList(list,xml):
soup = BeautifulSoup(xml,"xml")
div0 = soup.find_all("div",attrs={"class" : "c"})
div = []
for i in range(len(div0)):
if 'id="C' in str(div0[i]):
div.append(div0[i])
for i in range(len(div)):
try:
print(div[i])
time = re.compile(r'<span class="ct".*?</span>').search(str(div[i]))[0].replace('<span class="ct">','').replace('</span>', '').replace("来自网页","")
pat = re.compile(r'<a href=".*?">')
ID = pat.search(str(div[i]))[0].replace('<a href="',"").replace('">',"")
username = re.compile(r'<a href=".*?</a>').search(str(div[i]))[0].replace('<a href="',"").replace('">',"").replace(ID,"").replace("</a>","")
#个人信息
id,sex,addr,birthday = getInfo(ID)
#评论
ttext = re.compile(r'<span class="ctt.*?</span>').search(str(div[i]))[0]
#like = re.compile(r"赞.*?</a>").search(str(div[i]))[0].replace("赞[","").replace("]</a>","")
print(ttext)
if "回复" in ttext:
text = re.compile(r'</a>.*</span>').search(str(ttext))[0].replace("</a>:","").replace("</span>","")
else:
text = ttext.replace('<span class="ctt">','').replace('</span>','')
if "</a>" in text:
span_a = re.compile(r'<a.*?/a>').search(str(text))
for m in range(len(span_a)):
text = text.replace(span_a[m],"")
print(text)
biaoqing = re.findall(r"[[].*?[]]", text)
if text:
list.append([id,username,sex,addr,birthday,text,time,biaoqing])
except:
continue
getExcel(list):对list列表里的信息处理,将其写入文件中~
def getExcel(list):
excel = xlwt.Workbook(encoding="utf-8")
sheet = excel.add_sheet("sheet1")
sheet.write(0, 0, "id")
sheet.write(0, 1, "用户名")
sheet.write(0, 2, "性别")
sheet.write(0, 3, "地区")
sheet.write(0, 4, "生日")
sheet.write(0, 5, "评论")
sheet.write(0, 6, "时间")
sheet.write(0, 7, "表情")
for i in range(len(list)):
t = list[i]
sheet.write(i + 1, 0, t[0])
sheet.write(i + 1, 1, t[1])
sheet.write(i + 1, 2, t[2])
sheet.write(i + 1, 3, t[3])
sheet.write(i + 1, 4, t[4])
sheet.write(i + 1, 5, t[5])
sheet.write(i + 1, 6, t[6])
m = t[7]
num = 7
enjoy = []
for j in range(len(m)):
if m[j] not in enjoy:
enjoy.append(m[j])
sheet.write(i + 1, num, m[j])
num += 1
else:continue
excel.save('xxx.xls')
主函数:调用各个函数实现爬取微博评论。
def main():
i = 0
list = []
while i < 300:
url = 'https://weibo.cn/comment/GxwPfhEks??&uid=1900552512&&page={}'.format(i+1)
xml = getXMLText(url)
getList(list,xml)
print(url)
i += 1
print("已爬取"+str(len(list)))
time.sleep(5)
if i%5 == 0:
time.sleep(10)
getExcel(list)
if __name__ =="__main__":
main()
以上就是全部的代码,可以自己运行看一下~
下面是之前发的博客~有需要的可以自己看。
python爬虫——json格式爬取微博评论及评论人信息(含代码)
以上就是关于用beautiful soup库爬取微博评论的全部内容啦~
之后还会介绍xpath的方法~
另外,欢迎关注我的个人公众号:zoe会发光呀~
虽然已经太久不更新(-:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
