社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
学习python的最初原因就是写爬虫,最近一直在写爬虫。感觉写爬虫的时候主要问题就是四个:页面分析,网站登录,反反爬虫,多线程并发。四个问题难度依次递增。刚开始的时候觉得页面分析挺没有头绪的,但是写过几次之后就有了套路,对页面中的自己感兴趣的内容的抓取也变得得心应手了。其次就是网站登录,这是写爬虫一定会遇到的问题,因为有些网站需要用户登录之后才可以查看,所以需要去分析网站的登录机制。难点在于,虽然用python写用户登录的步骤都是大同小异的,但是,因为每个网站的登录机制都是不一样的,登录的时候post的参数也是不一样的,分析部分有点难度。并且有些网站在post参数的时候,会在浏览器这边先用js给参数进行加密,如果不知道参数的加密方式那就麻烦了。反反爬虫和多线程并发都是当爬虫需要爬取的数据量很大的时候需要面对的问题。
之前写了知乎的网站登录,昨天开始又尝试写新浪的网站登录,打算最近把几个网站的登录都写写,多练练手。
首先是使用Chrome浏览器对发送的请求进行抓包:
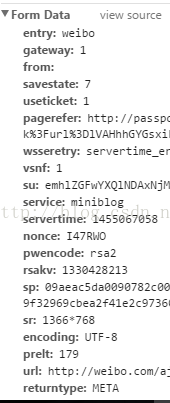
这是在密码输入错误的情况下抓取的情况:
分析之后发现post的表单参数有
其中servertime,nonce,rsakv是从prelogin.php请求的返回数据中获取到的
su是经过加密之后的用户名,一次base64加密
sp是经过加密之后的密码,rsa加密方式加密过后的密码
su和sp的分析是通过网上看别人的文章看到的,自己想还没有那个能力
剩余的参数都是固定值,直接写死就好
知道参数构成之后,对生成参数,提交
登录成功之后返回的数据是类似于:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK" />
<title>ÐÂÀËͨÐÐÖ¤</title>
<script charset="utf-8" src="http://i.sso.sina.com.cn/js/ssologin.js"></script>
</head>
<body>
ÕýÔڵǼ ...
<script>
try{sinaSSOController.setCrossDomainUrlList({"retcode":0,"arrURL":["http://crosdom.weicaifu.com/sso/crosdom?action=login&savestate=1486607880","http://passport.97973.com/sso/crossdomain?action=login&savestate=1486607880","http://passport.weibo.cn/sso/crossdomain?action=login&savestate=1"]});}
catch(e){
var msg = e.message;
var img = new Image();
var type = 1;
img.src = 'http://login.sina.com.cn/sso/debuglog?msg=' + msg +'&type=' + type;
}try{sinaSSOController.crossDomainAction('login',function(){location.replace('http://passport.weibo.com/wbsso/login?ssosavestate=1486607880&url=http%3A%2F%2Fweibo.com%2Fajaxlogin.php%3Fframelogin%3D1%26callback%3Dparent.sinaSSOController.feedBackUrlCallBack&ticket=ST-NTg1MjY3NTQzOA==-1455071880-ja-778ADEC6A0A90C1D06828059C554BED6&retcode=0');});}
catch(e){
var msg = e.message;
var img = new Image();
var type = 2;
img.src = 'http://login.sina.com.cn/sso/debuglog?msg=' + msg +'&type=' + type;
}
</script>
</body>
</html>
{location.replace('http://passport.weibo.com/wbsso/login?ssosavestate=1486607880&url=http%3A%2F%2Fweibo.com%2Fajaxlogin.php%3Fframelogin%3D1%26callback%3Dparent.sinaSSOController.feedBackUrlCallBack&ticket=ST-NTg1MjY3NTQzOA==-1455071880-ja-778ADEC6A0A90C1D06828059C554BED6&retcode=0')<html><head><script language='javascript'>parent.sinaSSOController.feedBackUrlCallBack({"result":true,"userinfo":{"uniqueid":"5812345438","userid":null,"displayname":null,"userdomain":"?wvr=5&lf=reg"},"redirect":"http://weibo.com/nguide/interest"});</script></head><body></body></html>
附上完整代码:
#-*-coding:utf-8-*-
import requests
from bs4 import BeautifulSoup
import time
import json
import os
import base64
import urllib
import hashlib
import re
import rsa
import binascii
head = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content-Type':'application/x-www-form-urlencoded',
'Accept-Language':'zh-CN,zh;q=0.8',
'Accept-Encoding':'gzip, deflate',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests':'1',
'Origin':'http://weibo.com',
"Referer":"http://weibo.com/",
'User-Agent':'Mozilla/5.0(Windows NT 6.1;WOW64;Trident/7.0;rv:11.0)like Gecko',
'Host':'login.sina.com.cn'}
data = {
"entry":"weibo",
"gateway":"1",
"savestate":"7",
"useticket":"1",
"pagerefer":"https://www.baidu.com/link?url=3YSdEuAbjIWO9udn3LjIow1nWKq68fuNgSft3DzFvJu&wd=&eqid=91465358014ef6870000000356b9ac4e",
"vsnf":"1",
"su":"",
"service":"miniblog",
"servicetime":"",
"nonce":"",
"pwencode":"rsa2",
"rsakv":"",
"sp":"",
"sr":"1366*768",
"encoding":"UTF-8",
"prelt":"76",
"url":"http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack",
"returntype":"META"
}
if __name__ == '__main__':
email = "xxxxxxx@xx.xx"
password = "xxxxxxx"
pre_url = "http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=emhlZGFwYXQlNDAxNjMuY29t&rsakt=mod&client=ssologi"
s = requests.session()
res=s.get(pre_url)
res = res.text.encode('utf-8').split('(')[-1].split(')')[0]
pre_json = json.loads(res)
print pre_json
servertime = pre_json['servertime']
nonce = pre_json['nonce']
rsakv = pre_json['rsakv']
pubkey = pre_json['pubkey']
#urllib.quote()是进行url编码
#su是经过一次base64加密之后的账号
su = base64.encodestring(urllib.quote(email))[:-1]
print "su:%s" % su
#rsa2计算sp
rsaPubkey = int(pubkey,16)
key = rsa.PublicKey(rsaPubkey,65537)
message = str(servertime) + 't' + str(nonce) + 'n' + str(password)
sp = rsa.encrypt(message,key)
sp = binascii.b2a_hex(sp)
print "sp:%s" % sp
data['servertime'] = servertime
data['nonce'] = nonce
data['rsakv'] = rsakv
data['su'] = su
data['sp'] = sp
#
post_url = "http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)&wsseretry=servertime_error"
res = s.post(post_url,data = data)
print res.text
p = re.compile('location.replace('(.*?)')')
final_url = p.search(res.text.encode('utf-8')).group(1)
res = s.get(final_url)
print res.text
res = res.text.encode('utf-8').split('(')[-1].split(')')[0]
user_json = json.loads(res)
uniqueid = user_json['userinfo']['uniqueid'].encode('utf-8')
print user_json['userinfo']['uniqueid']
main_url = "http://weibo.com/u/%s/home" % uniqueid
res = s.get(main_url)
print '登录成功'如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!