社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
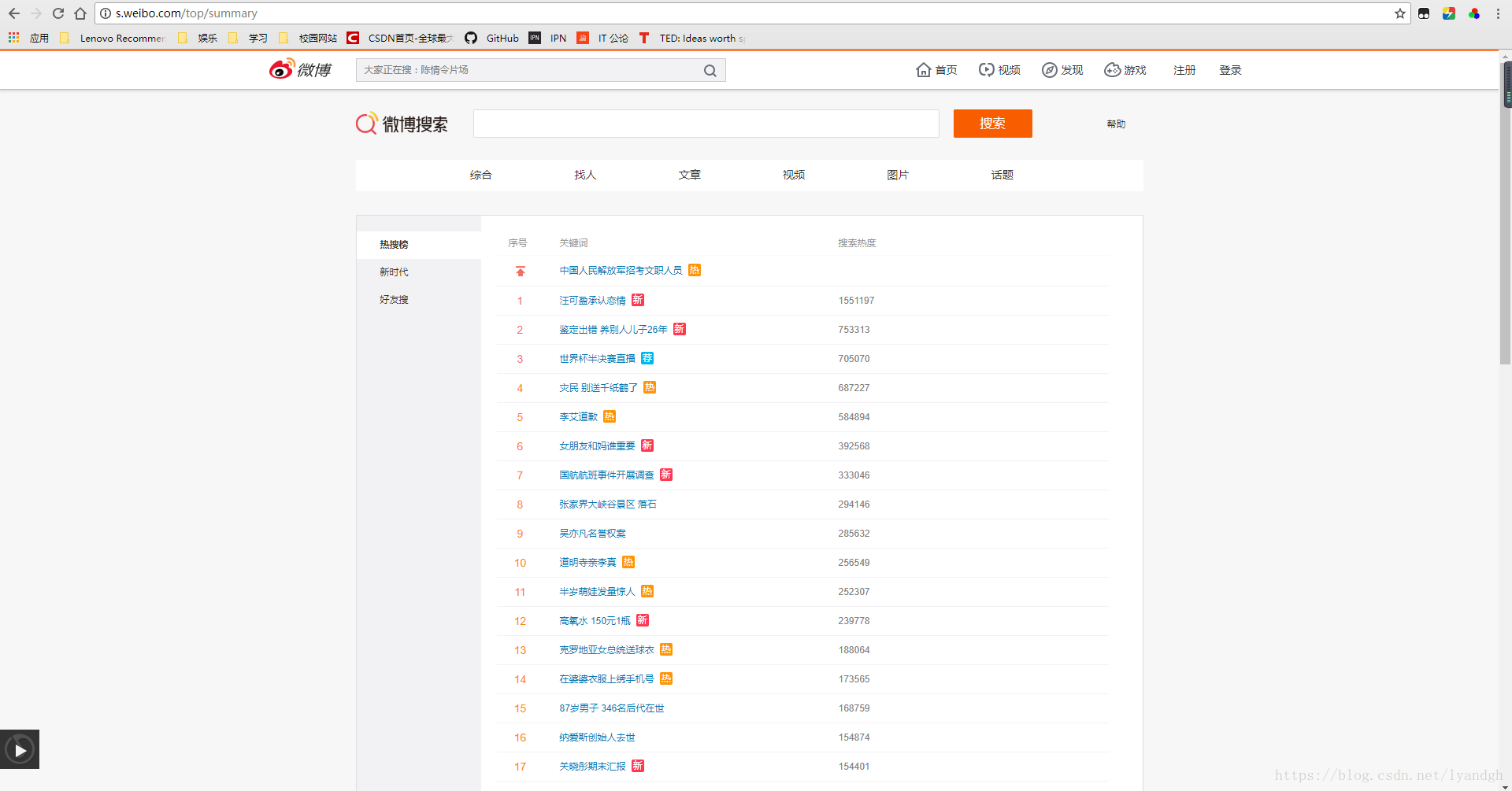
新浪微博的热搜榜网址是http://s.weibo.com/top/summary,总共有50条,如图所示
我们如何爬取这50条热搜呢?今天写一个简单的方法供感兴趣的朋友们参考!
引用库:
引用方法如下:
如果没有下载的需要自行下载,下载根据python版本而异,方法就不赘述了。
获取网页源码:
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
data = {
'cate':'realtimehot'
}
try:
r = requests.get('http://s.weibo.com/top/summary?',params=data,headers=headers)
print(r.url)
if r.status_code == 200:
html = r.text
except:
html = ""User-Agent根据自己浏览器的控制台去查看一下就行,源码保存在html中。
lxml解析:
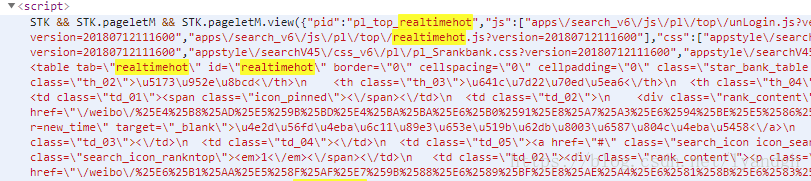
这里主要用到lxml中的etree包,其中xpath方法可以获取到包括script这样的节点。我们查看这个热搜榜网页的源码,可以发现详细的列表内容并没有写在静态页面中,而是写在script中,如图
也就是说,我们需要解析到script中的这段代码,从中提取有用的信息
这里我用两种方法来解析,一种是BeautifulSoup,另一种是lxml。代码如下
def parseMethod(id,html):
if id == 'bs':
soup = BeautifulSoup(html,'lxml')
sc = soup.find_all('script')[14].string
start = sc.find("(")
substr = sc[start+1:-1]
text = json.loads(substr)#str转dict
rxml = text["html"]#打印dict的key值,包含pid,js,css,html
soupnew = BeautifulSoup(rxml,'lxml')
tr = soupnew.find_all('tr',attrs={'action-type':'hover'})
elif id == 'lxml':
selector = etree.HTML(html)
tt = selector.xpath('//script/text()')
htm = tt[8]
start = htm.find("(")
substr = htm[start+1:-1]
text = json.loads(substr)#str转dict
rxml = text["html"]#打印dict的key值,包含pid,js,css,html
et = etree.HTML(rxml)
tr = et.xpath(u'//tr[@action-type="hover"]')
else:
pass
return tr根据传入的id选择不同的解析方式,两种方法都不难,应该很容易看懂,简单描述就是:
- 先获取含有realtimehot的script(到源码中去数第几个,在bs中是第16个,lxml中是10个,因为xpath选了text(),有<script></script>的空标签的就过滤掉了,因此只有10个)
- 对script的字符串进行索引,找到“(”的位置,然后提取()内的子串
- 用json.loads()把字符串解析为字典,共有pid,js,css,html四个键
- 提取key为html的value值,然后再用bs或者lxml解析一次
- 提取<tr action-type="hover">标签存入list
写入txt:
def lxmldata(tr):
for t in tr:
id = eval(t.find(u".//td[@class='td_01']").find(u".//em").text)
title = t.find(u".//p[@class='star_name']").find(u".//a").text
num = eval(t.find(u".//p[@class='star_num']").find(u".//span").text)
yield {
'index' : id,
'title' : title,
'num' : num
}
def bsdata(tr):
for t in tr:
id = eval(t.find('em').string)
title = t.find(class_='star_name').find('a').string
num = eval(t.find(class_='star_num').string)
yield {
'index' : id,
'title' : title,
'num' : num
}
def output(id,tr):
with open("weibohotnews.txt","w",encoding='utf-8') as f:
if id == 'bs':
for i in bsdata(tr):
f.write(str(dict(i))+'n')
elif id == 'lxml':
for i in lxmldata(tr):
f.write(str(dict(i))+'n')
else:
pass同样根据id来选择解析方式,两种方法也都很清楚,去不同的位置获取需要的值就OK。
最后写一个main函数,调用以上方法,如下
def main():
url = 'http://s.weibo.com/top/summary?'
method = 'lxml'
html = input(url)
tr = parseMethod(method,html)
output(method,tr)
main()结果:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!