社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Hadoop-3.0.3,Zookeeper-3.4.13和HBase-2.1.0。| Hostname | IP |
|---|---|
| master | 10.0.86.245 |
| ceph1 | 10.0.86.246 |
| ceph2 | 10.0.86.221 |
| ceph3 | 10.0.86.253 |
master结点中Thrift-0.11.0链接:https://github.com/SparksFly8/Tools
Ubuntu安装Thrift依赖:
apt-get install automake bison flex g++ git libboost1.55 libevent-dev libssl-dev libtool make pkg-config
CentOS-7.5安装Thrift依赖:
yum install automake bison flex g++ git libboost1.55 libevent-dev libssl-dev libtool make pkg-config
解压并编译thrift,我是解压到/usr/local/中。
tar -zxvf thrift-0.11.0.tar.gz
cd thrift-0.11.0
./configure --with-cpp --with-boost --with-python --without-csharp --with-java --without-erlang --without-perl --with-php --without-php_extension --without-ruby --without-haskell --without-go
make
make install
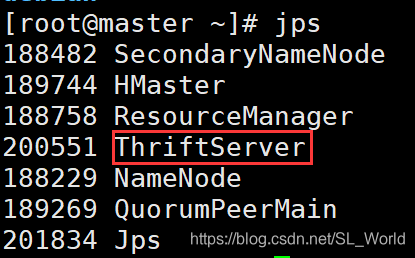
在master结点中Hbase安装目录下的/usr/local/hbase/bin目录启动thrift服务
[root@master bin]# ./hbase-daemon.sh start thrift
启动成功master状态如下:
我已将下面提到的所有方法分别整理成函数,并加入自己的需求在数据获取方面进行改善,欲看完整代码请见我的GitHub.
①分别下载两个安装包:thrift和hbase-thrift。
②在..site-packageshbase下替换两个文件,Hbase.py和ttypes.py。
F:Envvirtual3.6Libsite-packageshbase # 我自己本地放置包的路径
③运行如下示例代码:连接HBase:
from thrift.transport import TSocket,TTransport
from thrift.protocol import TBinaryProtocol
from hbase import Hbase
# thrift默认端口是9090
socket = TSocket.TSocket('10.0.86.245',9090) # 10.0.86.245是master结点ip
socket.setTimeout(5000)
transport = TTransport.TBufferedTransport(socket)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
socket.open()
print(client.getTableNames()) # 获取当前所有的表名

运行结果对比HBase中数据表正确:
说明:以下案例均建立在上述成功连接HBase的基础上运行。
1.建表
【函数】:createTable(tableName, columnFamilies)
【参数】:tableName-表名; columnFamilies-列簇(列表)
【案例】:
from hbase.ttypes import ColumnDescriptor
# 定义列族
col1 = ColumnDescriptor(name='c1')
col2 = ColumnDescriptor(name='c2')
# 创建表
client.createTable('table',[col1, col2])
print(client.getTableNames()) # 获取当前所有的表名,返回一个包含所有表名的列表
等价于HBase Shell命令:
$ create 'table','c1','c2'
执行结果:
['table']
2.删除整表或删除某行数据
①删除整表
【函数】:deleteTable(tableName)
【参数】:tableName-表名
【案例】:
client.disableTable('table') # 删除表前需要先设置该表不可用
client.deleteTable('table')
print(client.getTableNames()) # 获取当前所有的表名,返回一个包含所有表名的列表
等价于HBase Shell命令:
$ disable 'table'
$ drop 'table'
执行结果:
[]
②删除指定表的某行数据
【函数】:deleteAllRow(tableName, row)
【参数】:tableName-表名;row-行键
【案例】:
client.deleteAllRow('table', '0001') # 删除第0001行所有数据
3.向某行某列插入/更新数据
【函数】:mutateRow(tableName, row, mutations)
【参数】:tableName-表名;row-行键;mutations-变化(列表);
【案例】:
def insertRow(client, tableName, rowName, colFamily, columnName, value):
mutations = [Mutation(column='{0}:{1}'.format(colFamily, columnName), value=str(value))]
client.mutateRow(tableName, rowName, mutations)
print('在{0}表{1}列簇{2}列插入{3}数据成功.'.format(tableName, colFamily, columnName, value))
insertRow(client, 'table', '0001', 'c1', 'hobby2', 'watch movies')
print(client.get('table','0001','c1')[0].value)
等价于HBase Shell命令:
$ put 'table','0001','c1:hobby2','watch movies'
执行结果:
在table表c1列簇hobby2列插入watch movies数据成功.
4.读取指定列簇指定列数据
【函数1】:get(tableName, row, column)
【函数2】:getVer(tableName, row, column, numVersions)
【参数】:tableName-表名;row-行键;numVersions-版本号;
column-指定列簇的列名(或仅填列簇名也ok);
【案例】:
# 若该行下指定列簇有多个列,则返回的是个包含多个列值的列表,可用索引来指明是哪一列
print(client.get('table','0001','c1')[index].value)
print(client.getVer('table','0001','c1',1))[index].value)
# 获取固定列簇固定列的值,即仅包含一个值的列表,需用索引0来获取。
print(client.get('table','0001','c1:hobby2')[0].value)
print(client.getVer('table','0001','c1:hobby2',1))[0].value)
等价于HBase Shell命令:
$ get 'table','0001','c1'
$ get 'table','0001','c1:hobby2'
执行结果:
watch movies
5.遍历指定行所有数据
【函数1】:getRow(tableName, row)
【函数2】:getRowWithColumns(tableName, row, columns)
【参数】:tableName-表名;row-行键;column-一个指定列簇指定列名的列表(若仅填列簇名就返回该列簇下所有列值);
【案例】:
results = client.getRow('table','0001')
for result in results:
print(result.columns.get('c1:hobby2').value)
results = client.getRowWithColumns('table','0001',['c1']))
for result in results:
print(result.columns.get('c1:hobby2').value)
results = client.getRowWithColumns('table','0001',['c1:hobby2'])
for result in results:
print(result.columns.get('c1:hobby2').value)
等价于HBase Shell命令:
$ get 'table','0001'
$ get 'table','0001','c1'
$ get 'table','0001','c1:hobby2'
执行结果:
watch movies
【额外补充】:以下是我根据getRow和getRowWithColumns两个函数,经过数据清洗成常用字典形式,并过滤冒号,返回仅含有列名对应列值的字典。其中对于以下三种情况分别进行了处理:
①获取HBase指定表指定行的所有数据,以字典形式作为返回值。
②获取HBase指定表指定行指定列簇的所有数据,以字典形式作为返回值。
③获取HBase指定表指定行指定列簇指定列的数据,以字符串形式作为返回值。
'''
功能:获取HBase指定表的某一行数据。
:param client 连接HBase的客户端实例
:param tableName 表名
:param rowName 行键名
:param colFamily 列簇名
:param columns 一个包含指定列名的列表
:return RowDict 一个包含列名和列值的字典(若直接返回指定列值,则返回的是字符串)
'''
def getRow(client, tableName, rowName, colFamily=None, columns=None):
# 1.如果列簇和列名两个都为空,则直接取出当前行所有值,并转换成字典形式作为返回值
if colFamily is None and columns is None:
results = client.getRow(tableName, rowName)
RowDict = {}
for result in results:
for key, TCell_value in result.columns.items():
# 由于key值是'列簇:列名'形式,所以需要通过split函数以':'把列名分割出来
each_col = key.split(':')[1]
RowDict[each_col] = TCell_value.value # 取出TCell元组中的value值
return RowDict
# 2.如果仅是列名为空,则直接取出当前列簇所有值,并转换成字典形式作为返回值
elif columns is None:
results = client.getRowWithColumns(tableName, rowName, [colFamily])
RowDict = {}
for result in results:
for key, TCell_value in result.columns.items():
# 由于key值是'列簇:列名'形式,所以需要通过split函数以':'把列名分割出来
each_col = key.split(':')[1]
RowDict[each_col] = TCell_value.value # 取出TCell元组中的value值
return RowDict
# 3.如果列簇和列名都不为空,则直接取出当前列的值
elif colFamily is not None and columns is not None:
results = client.getRow(tableName, rowName)
for result in results:
value = result.columns.get('{0}:{1}'.format(colFamily, columns)).value
return value
else:
raise Exception('关键参数缺失,请重新检查参数!')
print(getRow(client, 'table', '0001'))
print(getRow(client, 'table', '0001', 'c1'))
print(getRow(client, 'table', '0001', 'c1', 'hobby2'))
执行结果:
# 第一个结果
{'age': '25', 'hobby1': 'reading', 'hobby2': 'watch movies', 'name': 'Tom', 'age': '30', 'hobby11': 'reading books'}
# 第二个结果
{'age': '25', 'hobby1': 'reading', 'hobby2': 'watch movies', 'name': 'Tom'}
# 第三个结果
watch movies
6.扫描并获取多行数据
【函数1】:scannerOpen(tableName, startRow, columns)
【功能】:从startRow行扫描到该表最后一行。
【函数2】:scannerOpenWithStop(tableName, startRow, stopRow, columns)
【功能】:从startRow行扫描到该表stopRow的前一行。
【参数】:tableName-表名;startRow-起始行键;stopRow-截止行键;column-一个指定列簇指定列名的列表(若仅填列簇名就返回该列簇下所有列值);
【案例】:
# 从20180900行扫描到最后一行
scannerId = client.scannerOpen('2018AAAI_Papers', '20180900', ['paper_info:title','paper_info:keywords'])
# 根据scannerId和rowsCnt(扫描的行数,可自己定义,若超出表的范围则扫描到表的最后一行)得到结果
results = client.scannerGetList(scannerId, rowsCnt)
# 从20180900行扫描到20180904行
scannerId = client.scannerOpenWithStop('2018AAAI_Papers', '20180900', '20180904', ['paper_info:title','paper_info:keywords'])
# 根据scannerId和rowsCnt(扫描的行数,可自己定义,若超出表的范围则扫描到表的最后一行)得到结果
results = client.scannerGetList(scannerId, rowsCnt)
【额外补充】:以下是我根据scannerOpen和scannerOpenWithStop两个函数,经过数据清洗成常用字典形式,并过滤冒号,返回一个包含每行行键对应该行列值信息字典的字典。若传入行键或列名有误,则返回空列表。最终整合成scannerGetSelect方法。
def scannerGetSelect(client, tableName, columns, startRow, stopRow=None, rowsCnt=2000):
'''
依次扫描HBase指定表的每行数据(根据起始行,扫描到表的最后一行或指定行的前一行)
:param client: 连接HBase的客户端实例
:param tableName: 表名
:param columns: 一个包含(一个或多个列簇下对应列名的)列表
:param startRow: 起始扫描行
:param stopRow: 停止扫描行(默认为空)
:param rowsCnt: 需要扫描的行数
:return MutilRowsDict: 返回一个包含多行数据的字典,以每行行键定位是哪一行
'''
# 如果stopRow为空,则使用scannerOpen方法扫描到表最后一行
if stopRow is None:
scannerId = client.scannerOpen(tableName, startRow, columns)
# 如果stopRow不为空,则使用scannerOpenWithStop方法扫描到表的stopRow行
else:
scannerId = client.scannerOpenWithStop(tableName, startRow, stopRow, columns)
results = client.scannerGetList(scannerId, rowsCnt)
# 如果查询结果不为空,则传入行键值或列值参数正确
if results:
MutilRowsDict = {}
for result in results:
RowDict = {}
for key, TCell_value in result.columns.items():
# 获取该行行键
rowKey = result.row
# 由于key值是'列簇:列名'形式,所以需要通过split函数以':'把列名分割出来
each_col = key.split(':')[1]
RowDict[each_col] = TCell_value.value # 取出TCell元组中的value值
# 把当前含有多个列值信息的行的字典和改行行键存储在MutilRowsDict中
MutilRowsDict[rowKey] = RowDict
return MutilRowsDict
# 如果查询结果为空,则传入行键值或列值参数错误,返回空列表
else:
return []
执行结果如下图:
# -*- coding: utf-8 -*-
__author__ = 'shiliang'
__date__ = '2019/3/1 23:48'
import math
from thrift.transport import TSocket,TTransport
from thrift.protocol import TBinaryProtocol
from hbase.ttypes import ColumnDescriptor
from hbase import Hbase
from hbase.ttypes import Mutation
def connectHBase():
'''
连接远程HBase
:return: 连接HBase的客户端实例
'''
# thrift默认端口是9090
socket = TSocket.TSocket('10.0.86.245',9090) # 10.0.86.245是master结点ip
socket.setTimeout(5000)
transport = TTransport.TBufferedTransport(socket)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = Hbase.Client(protocol)
socket.open()
return client
def ListTables(client):
'''
列出所有表
'''
print(client.getTableNames())
def createTable(client, tableName, *colFamilys):
'''
创建新表
:param client: 连接HBase的客户端实例
:param tableName: 表名
:param *colFamilys: 任意个数的列簇名
'''
colFamilyList = []
# 根据可变参数定义列族
for colFamily in colFamilys:
col = ColumnDescriptor(name=str(colFamily))
colFamilyList.append(col)
# 创建表
client.createTable(tableName,colFamilyList)
print('建表成功!')
def deleteTable(client, tableName):
'''
删除表
'''
if client.isTableEnabled(tableName):
client.disableTable(tableName) # 删除表前需要先设置该表不可用
client.deleteTable(tableName)
print('删除表{}成功!'.format(tableName))
def deleteAllRow(client, tableName, rowKey):
'''
删除指定表某一行数据
:param client: 连接HBase的客户端实例
:param tableName: 表名
:param rowKey: 行键
'''
if getRow(client, tableName, rowKey):
client.deleteAllRow(tableName, rowKey)
print('删除{0}表{1}行成功!'.format(tableName, rowKey))
else:
print('错误提示:未找到{0}表{1}行数据!'.format(tableName, rowKey))
def insertRow(client, tableName, rowName, colFamily, columnName, value):
'''
在指定表指定行指定列簇插入/更新列值
'''
mutations = [Mutation(column='{0}:{1}'.format(colFamily, columnName), value=str(value))]
client.mutateRow(tableName, rowName, mutations)
print('在{0}表{1}列簇{2}列插入{3}数据成功.'.format(tableName, colFamily, columnName, value))
def getRow(client, tableName, rowName, colFamily=None, columns=None):
'''
功能:获取HBase指定表的某一行数据。
:param client 连接HBase的客户端实例
:param tableName 表名
:param rowName 行键名
:param colFamily 列簇名
:param columns 一个包含指定列名的列表
:return RowDict 一个包含列名和列值的字典(若直接返回指定列值,则返回的是字符串)
'''
# 1.如果列簇和列名两个都为空,则直接取出当前行所有值,并转换成字典形式作为返回值
RowDict = {}
if colFamily is None and columns is None:
results = client.getRow(tableName, rowName)
for result in results:
for key, TCell_value in result.columns.items():
# 由于key值是'列簇:列名'形式,所以需要通过split函数以':'把列名分割出来
each_col = key.split(':')[1]
RowDict[each_col] = TCell_value.value # 取出TCell元组中的value值
return RowDict
# 2.如果仅是列名为空,则直接取出当前列簇所有值,并转换成字典形式作为返回值
elif columns is None:
results = client.getRowWithColumns(tableName, rowName, [colFamily])
for result in results:
for key, TCell_value in result.columns.items():
# 由于key值是'列簇:列名'形式,所以需要通过split函数以':'把列名分割出来
each_col = key.split(':')[1]
RowDict[each_col] = TCell_value.value # 取出TCell元组中的value值
return RowDict
# 3.如果列簇和列名都不为空,则直接取出当前列的值
elif colFamily is not None and columns is not None:
results = client.getRow(tableName, rowName)
for result in results:
value = result.columns.get('{0}:{1}'.format(colFamily, columns
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/SL_World/article/details/88071357
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
