社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
##常见URL过滤方法
###1 直接查询比较
即假设要存储url A,在入库前首先查询url库中是否存在 A,如果存在,则url A 不入库,否则存入url库。这种方法准确性高,但是一旦数据量变大,占用的存储空间也变大,同时,由于要查库,数据一多,查询时间变长,存储效率下降。
###2 基于hash的存储
对于给定的url,通过建立的hash函数,来获得对应的hash值,并将该值存入库中。当在检查url是否存在库中时,只要将要检查的url,通过hash函数获取其hash值,然后查看库中是否存在该hash值,存在则丢弃,否则入库。这种方法在数据量变大时,占用的存储空间也会增大,查询时间也会加长。但是它可以将url进行压缩。对于很长的url,hash值可以相对很短。
以上方法中,为加快查询速度,一般可以选择 Redis作为查询库。
##布隆过滤器 Bloom Filter
基本思路(网上一大堆):
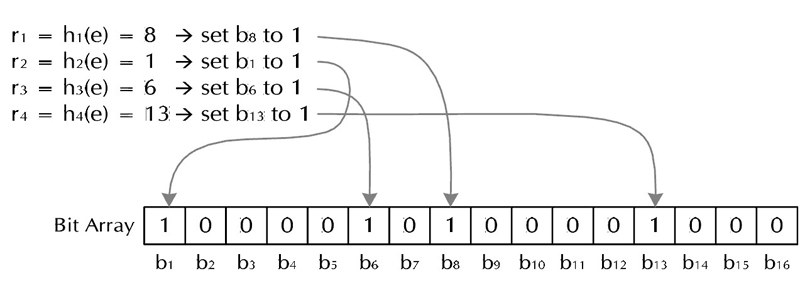
1, 设数据集合 ,含个元素,作为待操作的集合。
2, Bloom Filter用一个长度为的位向量表示的集合中的元素,位向量初始值全为0。
3, 个具有均匀分布特性的散列函数 .
4, 对于要加入的元素,首经过k个散列函数产生k个随机数,使向量的相应位置均置为1。集合中其他元素也通过类似的操作,将向量的若干位置为1。
5, 对于新要加入的元素的检查,首先将该元素经过上步中类似操作,获得k个随机数,然后查看向量的相应位置上的值,若全为1,则该元素已经在之前的集合中;若至少有一个0存在,表明,此元素不在之前的集合中,为新元素。
算法特点:
对于已经在集合中的元素,通过5中的查找方法,一定可以判定该元素在集合中。
对于不在集合中的元素,可能会被误判在集合中。
其整个流程可以参照以下伪代码:
classBloom:
""" Bloom Filter """
def __init__(self,m,k,hash_fun):
"""m, size of the vector
k, number of hash fnctions to compute
hash_fun, hash function to use
"""
self.m = m
self.vector =[0]*m # initialize the vectorself.k = k
self.hash_fun = hash_fun
self.data ={}
# data structure to store the data
self.false_positive =0
def insert(self,key,value):
""" insert the pair (key,value) in the database """
self.data[key]= value
for i in range(self.k):
self.vector[self.hash_fun(key+str(i))%self.m]=1
def contains(self,key):
""" check if key is cointained in the database
using the filter mechanism """
for i in range(self.k):
if self.vector[self.hash_fun(key+str(i))%self.m]==0:
return False
# the key doesn't existreturnTrue# the key can be in the data set
def get(self,key):
""" return the value associated with key """
if self.contains(key):
try:returnself.data[key]# actual lookup
except KeyError: self.false_positive +=1
参数计算:
在Bloom Filter表示方法中,对于一元素,某一位被置1的概率为,为0的概率为,散列函数执行k次,对于集合中所有元素,执行次数kn次,所以在运算结束时,某位仍为0 的概率为:
由于
有
因此误判概率为:
由以上式可知,m增大,P减小;对于给定的n和m,求最小的P值。
将上式取对数有:
对k求导:
令
有:
可以发现,在上式中等号的任意一边,后一个数取对数刚好是前一个数,所以等号左右两边结构相似。则有:
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!