社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
随便开一个网站。(我这里就不截图了,每个网站都大同小异)
按之前博文写的方法,右键检查调出源程序。
网页头中定义了编码、选项卡之类的内容。点击三角符号折叠。
里面的< style>元素可以定义一些样式。
(style属性可以用来定义网页文本的样式,比如字体大小、颜色、间距、对齐方式等等)
然后看网页体,点击三角符号折叠
网页体有三大部分,< div id=“header”>元素的部分,< div id=“article”>元素的部分,和< div id=“footer”>元素的部分。
分别是:顶部的标题、中间的内容、以及底部。
首个< div>元素是网页的顶部标题:id=“header”
然后是< div id=“article”>元素,它对应的是中间的正文部分。
底部对应< div id=“footer”>。
细看中间正文部分。
< div id=“article”>元素分为两部分,它包含着两个< div>元素,分别对应着网页中间的左边栏和正文部分。
其实将鼠标放在相应的代码位置,左侧网页相应部分就会被标亮。慢慢自己摸索,就很快知道哪块对应哪块。
如图 甚至可以把网页改了。试着让首页后面再加一个页字,成功改动。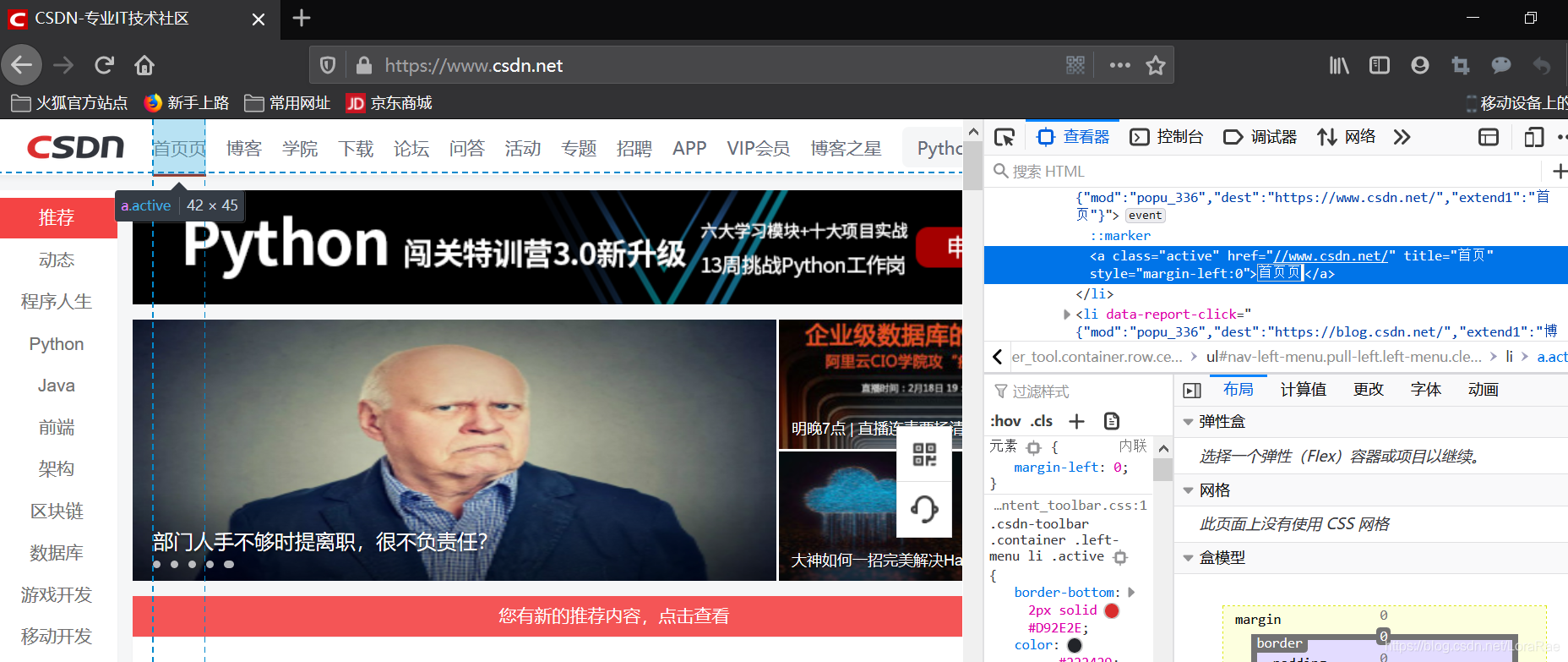
当然这样的修改只是本地修改,而服务器上的源文件是修改不了的,所以,这些改动仅供自娱自乐。
(后期会持续更新~ 欢迎点赞关注~)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
