社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在爬虫中,使用能读懂html的工具,才能提取到想要的数据。
本文介绍BeautifulSoup如何解析数据。
BeautifulSoup不是Python标准库,需要单独安装。
在cmd输入一行代码运行:pip install BeautifulSoup4。(Mac电脑需要输入pip3 install BeautifulSoup4)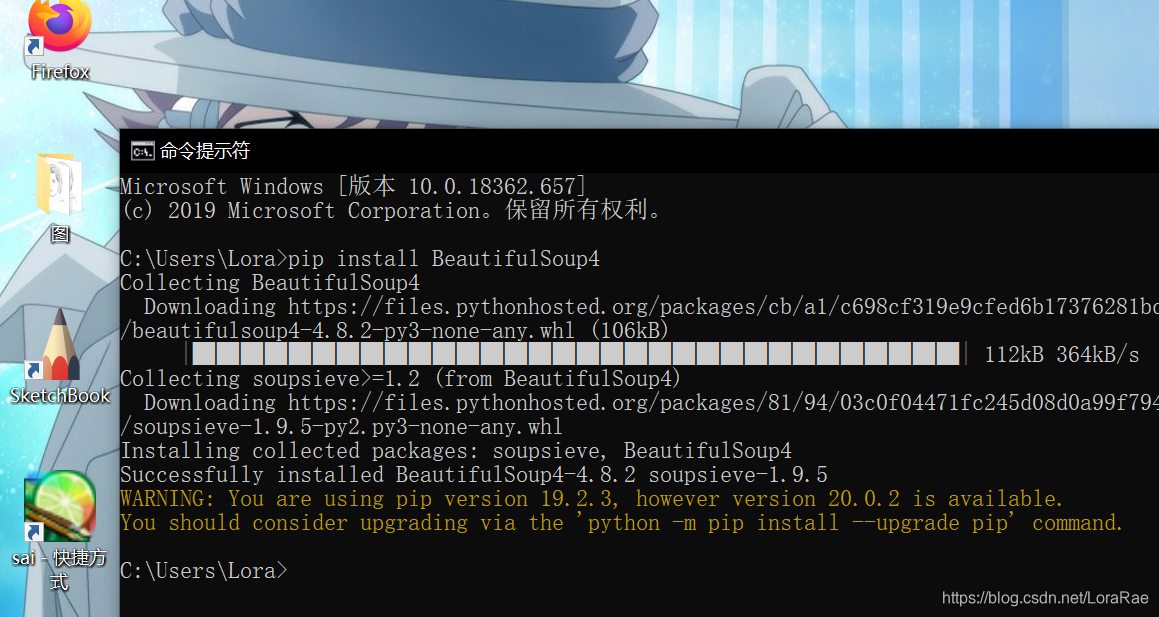
安装成功。
BeautifulSoup解析数据的用法很简单:
bs对象=BeautifulSoup(要解析的文本,‘解析器’)
括号中,要输入两个参数,第0个参数是要被解析的文本,注意,它必须是字符串。
括号中的第1个参数用来标识解析器,要用一个Python内置库:html.parser。(不是唯一的解析器,但是比较简单的)
具体的用法:
根据requests.get(),可以先获取到一个Response对象,并确认获取成功:
import requests #调用requests库
res = requests.get('填入一个URL')
#获取网页源代码,得到的res是response对象
print(res.status_code) #检查请求是否正确响应
html = res.text #把res的内容以字符串的形式返回
print(html)#打印html加入BeautifulSoup解析数据:
import requests
from bs4 import BeautifulSoup
#引入BS库
res = requests.get('那个URL')
html = res.text
soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象第2行是引入BeautifulSoup库。
最后一行中的第0个参数,必须是字符串类型;括号中的第1个参数是解析器。
以上就是解析数据的用法。
总结:
使用BeautifulSoup去解析数据:
from bs4 import BeautifulSoup
soup = BeautifulSoup(字符串,'html.parser')觉得有用的话就给文章点个赞吧~谢谢大家的支持 ~
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
