社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
之前一直遇到kafka数据读取重复的问题,但都通过一些方式去避免了,今天专门去探究了下原因。出现这个问题,一般都是设置kafkaoffset自动提交的时候发生的。原因在于数据处理时间大于max.poll.interval.ms(默认300s),导致offset自动提交失败,以致offset没有提交。重新读取数据的时候又会读取到kafka之前消费但没有提交offset的数据,从而导致读取到重复数据。具体错误如下:
[WARN]2018-08-07 16:31:51,502 method:org.apache.kafka.clients.consumer.internals.ConsumerCoordinator. maybeAutoCommitOffsetsSync (ConsumerCoordinator.java:664)
[Consumer clientId=consumer-1, groupId=first] Synchronous auto-commit of offsets {autoCommit3-0=OffsetAndMetadata{offset=44 , metadata=''}, autoCommit3-1=OffsetAndMetadata{offset=60, metadata=''}} failed: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
仔细想想不应该啊,自动提交offset和数据处理时间难道还有关系?为此,我专门阅读了kafka的某些源码。我们使用的Kafka的api,
调用的是KafkaConsumer的poll方法:
给方法调用了pollOnce方法:

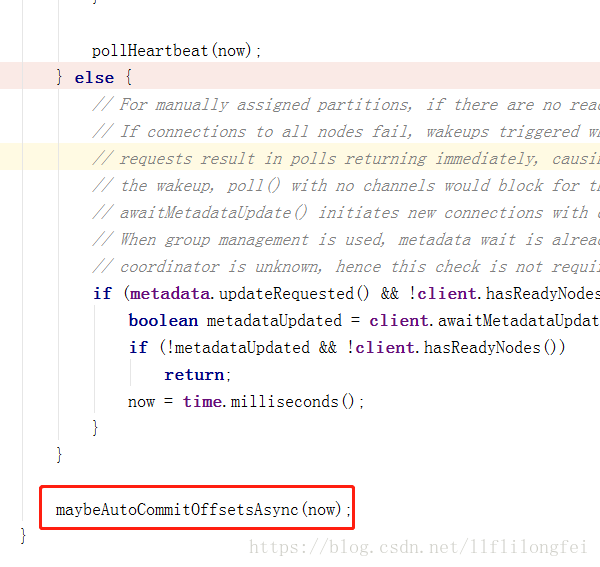
该方法的最后调用了自动offset同步的方法:
关键就在这个方法,这个方法只有在poll的时候才会调用,如果,数据处理时间操过poll的最大时间,就会导致本文开始的错误,而不能提交offset.
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!