社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Kafka将消息持久化到磁盘中的Log中,为了控制日志文件的大小就需要对消息进行清理操作。每个Log对应一个分区副本,Log可以分为多个日志分段,便于日志的清理操作。
在了解日志清理机制之前,请先了解日志存储方式
Kafka有两种日志清理策略:
log.cleanup.policy设置为delete(默认值)key进行整合,对于有相同的key的消息,只保留最后一个版本。log.cleanup.policy设置为compact,log.cleaner.enable设置为true(默认值)如果需要同时启动日志删除和日志压缩策略,可以将log.cleanup.policy设置为delete,compact。
Kafka日志管理器中有专门的任务负责周期性地检测、删除不符合条件的日志分段文件,该周期可通过参数log.rentention.check.interval.ms来配置,默认值为300000(5分钟)。
日志删除策略有3种:基于时间的删除策略、基于日志大小的删除策略、基于日志起始偏移量的删除策略。
日志删除任务会定期检查日志文件中是否有保留时间超出retentionMs的日志分段。retentionMs可以通过Broker端server.properties文件中的参数log.retention.hours、log.retention.minutes、log.retention.ms来配置,优先级依次递增。默认情况下只配置了log.retention.hours: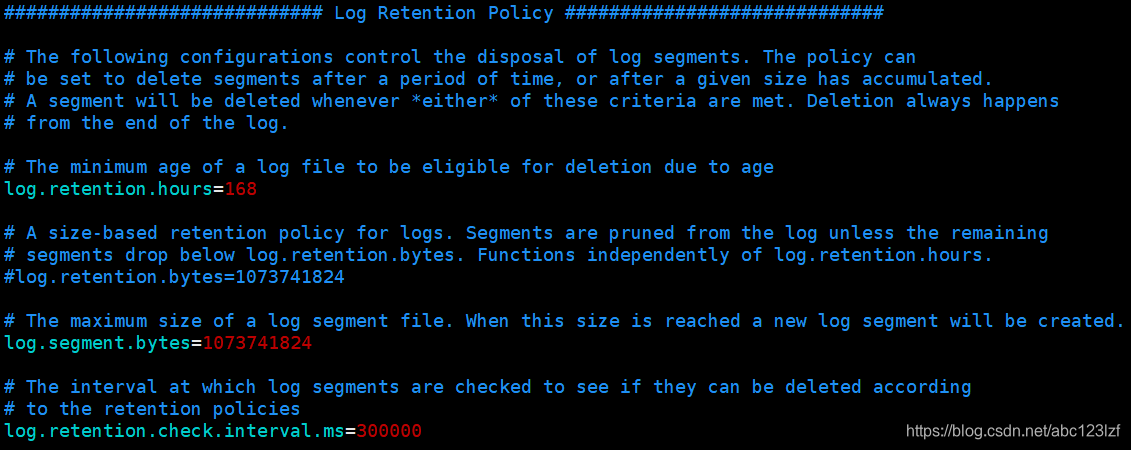
所以说,默认的retentionMs为168小时,即日志分段最多保存7天。
那么,Kafka是根据哪个时间来判断这个日志分段是否过期呢?
首先,它并不是只根据日志分段的最近修改时间(lastModifiedTime)来计算,而是根据日志分段中的最大时间戳(largestTimeStamp)计算的,因为最近修改时间常常会被更新。获取最大时间戳需要查询该日志分段所对应的时间戳索引文件(.timeindex文件)中最后一条索引项,若该索引项的时间戳大于0就取该值计算,否则还是取lastModifiedTime。
执行日志分段的删除任务时,会首先从Log对象中维护的日志分段的跳跃表中移除需要删除的日志分段,然后将日志分段所对应的文件和索引文件添加.deleted后缀。最后转交给名称为delete-file任务来删除以.deleted为后缀的文件,执行延迟时间可通过参数file.delete.delay.ms控制,默认为1分钟。
该策略会依次检查每个日志中的日志分段是否超出指定的大小(retentionSize),对超出指定大小的日志分段采取删除策略。retentionSize可通过Broker端参数log.retention.bytes来配置,单位为字节,默认值为-1,表示无穷大,该参数配置的是Log中所有日志文件的总大小,并非单个日志分段的大小。单个日志分段文件的大小限制可通过log.segment.bytes来限制,默认为1073741824,即1GB。
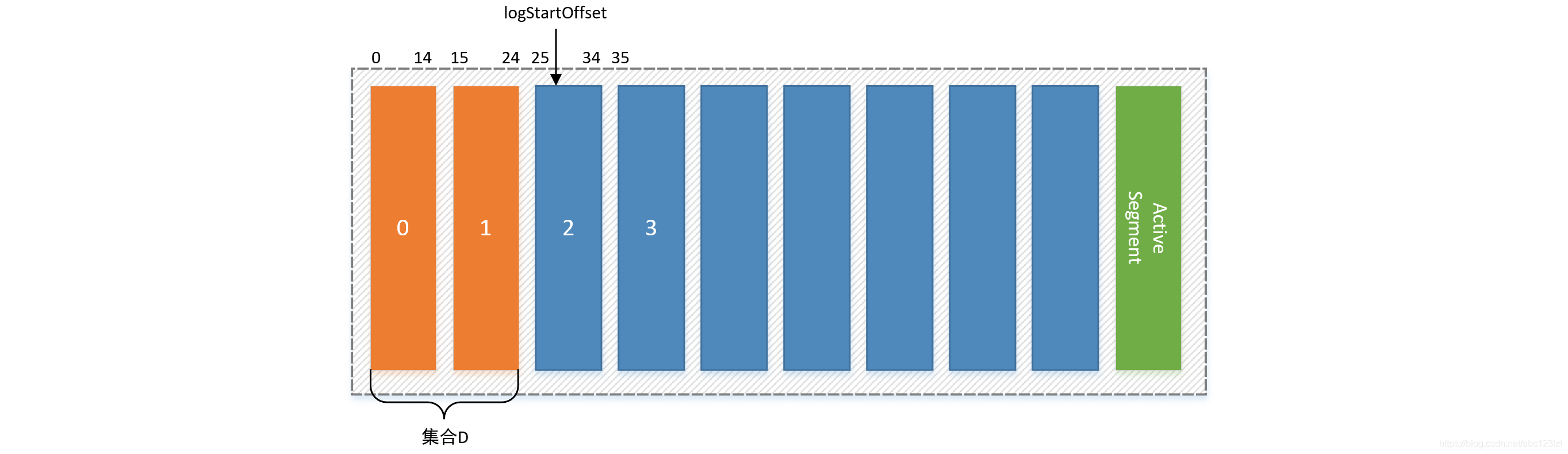
大多数情况下,日志的起始偏移量logStartOffset()等于第一个日志分段的baseOffset()。baseOffset的值也可以通过kafka-delete-records.sh脚本发起DeleteRecordsRequest请求手动修改。
该删除策略具体是删除某日志分段的下一个日志分段的baseOffset小于等于logStartOffset的部分。例如:日志起始分段, 日志分段0的起始偏移量,日志分段1的起始偏移量,日志分段2的起始偏移量 ,日志分段3的起始偏移量待删除的日志分段集合为 ,删除步骤如下:
Kafka中的日志压缩(Log Compaction)会保留具有相同key(不为null的前提下),不同value的消息集合中最新的一条消息,其余的将其删除。注意这里的日志压缩和消息压缩是两回事,消息压缩是采用gzip、LZ4等压缩算法压缩消息内容。如果用户需要删除整个key,可以添加一个墓碑消息,即value为null,但是key不为null(key的值等于需要删除的key)的消息。
日志压缩在执行前后会保证每条消息的偏移量不会发生改变,在执行期间会生成新的日志分段文件,消息的物理位置会发生变化,但由于偏移量没有改变所以偏移量不一定是连续的,但是并不会影响查询。
Kafka日志存储路径下有一个cleaner-offset-checkpoint文件,该文件记录了清理检查点,也就是每个分区中已被清理的偏移量。清理检查点将Log划分为两个部分:已经清理过的clean部分和未经清理的dirty部分。clean部分的消息偏移量不一定是连续的,而dirty部分消息偏移量是连续且逐一递增的。消费者必须读取dirty部分的消息才能保证能够读到所有的消息。需要注意活跃的日志分段(当前正在读写的日志分段)不会参与到日志压缩。
日志清理工作由Broker中专门的线程负责处理,该线程数量默认为1,可通过参数log.cleaner.thread指定。这个线程优先选择dirty部分比例最高的日志进行处理,这个比例具体的计算方式是:dirty比例等于dirty部分所占用字节数除以clean和dirty部分所占用字节数。为了防止日志清理操作过于频繁,可通过参数log.cleaner.min.cleanable.ratio来定义这个阈值(默认为0.5)。
选择好日志文件后,接下来就是根据该日志文件进行清理操作了。日志清理线程会使用一个SkimpyOffsetMap哈希表来构造key与offset的映射关系,具体在执行清理操作时会遍历两遍日志文件,第一遍把消息的每个key的哈希值(通过MD5来计算哈希,使用线性探测法解决哈希冲突)和最后出现的offset存储在SkimpyOffsetMap中,第二遍检查消息是否符合保留条件,对不符合的消息进行删除。SkimpyOffsetMap的负载因子可通过log.cleaner.io.buffer.load.factor调整,默认为0.9。
对于墓碑消息,日志清理线程会保留墓碑消息一段时间,这个条件是当前墓碑消息所在的日志分段的最近修改时间 ,的计算方式是clean部分中最后一个日志分段的最近修改时间减去log.cleaner.delete.retention.ms(默认86400000,即24小时)。
清理完日志分段文件后,其日志分段会比原先的要小,为了防止过多的小文件产生,Kafka会将日志文件中offset从0至firstUncleanableOffset的所有日志分段进行分组,要求每组日志分段的占用空间之和不超过log.segment.bytes(默认1GB),并且对应的索引文件大小占用之和不超过log.index.interval.bytes(默认10M),同一个组的所有日志分段文件最后会整合为一个日志分段文件。此时日志压缩完成。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
