社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
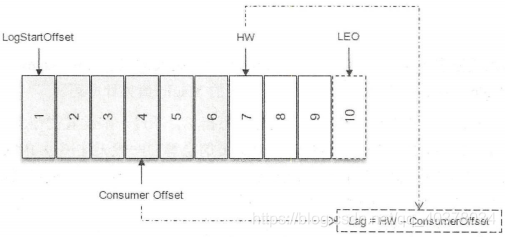
在没有引入事务的情况下,对于每个分区而言,它的Lag等于HW-ConsumerOffset(当前的消费位移)的值
在引入事务的情况下,如果消费者客户端的isolation.level参数配置为read_uncommitted(默认),那么Log的计算方式不受影响;如果这个参数配置为read_committed,那么就要引入LSO来进行计算了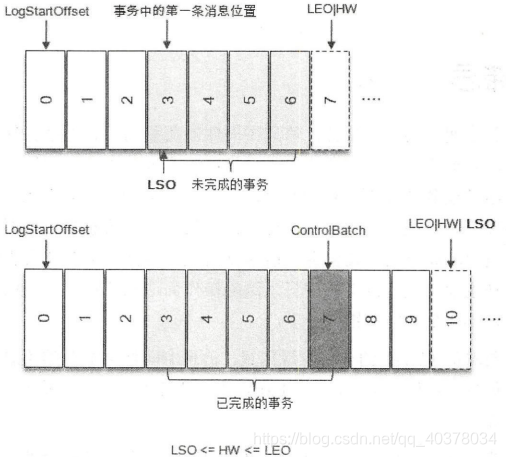
LSO是LastStableOffset的缩写,对于未完成的事务而言,LSO的值等于事务中第一条消息的位置,对已完成的事务而言,它的值同HW相同,LSO<=HW<=LEO
对于分区中有未完成的事务,并且消费者客户端的isolation.level参数配置为read_uncommitted的情况,它对应的Lag等于LSO-ConsumerOffset
主从分离与否没有绝对的优劣,它仅仅是一种架构设计,各自有适用的场景
第一点:Redis和MySQL都支持主从读写分离,这和它们的使用场景有关。对于那种读操作很多而写操作相对不频繁的负载类型而言,采用读写分离是非常不错的方案——我们可以添加很多follower横向扩展,提升读操作性能。反观Kafka,它的主要场景还是在消息引擎而不是以数据存储的方式对外提供读服务,通常涉及频繁地生产消息和消费消息,这不属于典型的读多写少场景,因此读写分离方案在这个场景下并不太适合
第二点:Kafka副本机制使用的是异步消息拉取,因此存在leader和follower之间的不一致性。如果要采用读写分离,必然要处理leader和follower之间的数据不一致问题
第三点:主写从读可以均摊一定的负载却不能做到完全的负载均衡,比如对于数据写压力很大而读压力很小的情况,从节点只能分摊很少的负载压力,而绝大多数压力还是在主节点上。而在Kafka中却可以达到很大程度上的负载均衡,而且这种均衡是在主写主读的架构上实现的
如上图所示,在Kafka集群中有3个分区,每个分区有3个副本,正好均匀地分布在3个broker上,灰色阴影的代表leader副本,非灰色阴影的代表follower副本,虚线表示follower副本从leader副本上拉取消息。当生产者写入消息的时候都写入leader副本,对于上图而言,每个broker都有消息从生产者流入;当消费者读取消息的时候也是从leader副本中读取的,每个broker都有消息流出到消费者。每个broker上的读写负载都是一样的,Kafka可以通过主写主读实现主写从读实现不了的负载均衡,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度
参考:https://www.zhihu.com/question/327925275/answer/705690755
1)、Broker参数
1)存储信息相关的:
只要设置log.dirs即可,在线上生产环境中一定要为log.dirs配置多个路径,多个路径使用逗号分隔
2)ZooKeeper相关的:
zookeeper.connect
多个Kafka集群使用同一套ZooKeeper集群时,可以使用ZooKeeper的chroot。如果有两套使用的Kafka集群,分别叫它们kafka1和kafka2,这两套集群的zookeeper.connect参数可以这样指定:zk1:2181,zk2:2181,zk3:2181/kafka1和zk1:2181,zk2:2181,zk3:2181/kafka2。chroot只需要写一次,而且是加到最后的
3)Topic管理相关的:
auto.create.topics.enable推荐设置为false
unclean.leader.election.enable如果设置为true就意味着当leader下线时候可以从非ISR集合中选举出新的leader,这样有可能造成数据的丢失,推荐设置为false
auto.leader.rebalance.enable设置为true时,设置它的值为true表示允许Kafka定期地对一些Topic分区进行Leader重选举(需要满足一定条件),生产环境推荐设置为false
4)数据保留相关的:
2)、Topic参数
Topic级别参数会覆盖全局broker参数的值
retention.ms:规定了该Topic消息被保存的时长。默认是7天,即该Topic只保存最近7天的消息。一旦设置了这个值,它会覆盖掉broker端的全局参数值Topic级别参数的设置有两种方式:
在创建时设置:
保留近一年的数据,最大消息大小为5MB
[root@localhost bin]# ./kafka-topics.sh --zookeeper localhost:2181 --create --topic topic-create --partitions 1 --replication-factor 1 --co
nfig retention.ms=31536000000 --config max.message.bytes=5242880
修改Topic时设置:
[root@localhost bin]# ./kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name topic-create --alter --add-config ma
x.message.bytes=10000
3)、JVM参数
在启动Kafka Broker之前,先设置上这两个环境变量:
[root@localhost bin]# export KAFKA_HEAP_OPTS="--Xms6g --Xmx6g"
[root@localhost bin]# export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=3
5 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true"
[root@localhost bin]# ./kafka-server-start.sh ../config/server.properties
4)、操作系统参数
分区策略是决定生产者将消息发送到哪个分区的算法
如果要自定义分区策略,需要实现org.apache.kafka.clients.producer.Partitioner接口,然后显示地配置生产者端的参数partitioner.class为该实现类的全限定名
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
public void close();
}
partition()方法用来计算分区号,返回值为int类型。partition()方法中的参数分别表示主题、键、序列化后的键、值、序列化后的值,以及集群的元数据信息。close()方法在关闭分区器的时候用来回收一些资源
1)、默认生产者分区策略
Java客户端默认生产者分区策略的实现类为org.apache.kafka.clients.producer.internals.DefaultPartitioner
这里需要说明一下如果生产者在发送消息的时候指定了partition就直接发送到该分区,与分区策略无关
默认策略为:如果没有指定partition但是指定了key,就按照key的hash值选择分区;如果partition和key都没有指定就使用轮询策略。而且如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null并且有可用分区时,那么计算得到的分区号仅为可用分区中的任意一个。具体实现代码如下:
public class DefaultPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
public void configure(Map<String, ?> configs) {}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
public void close() {}
}
从上面的分析我们知道默认生产者分区策略其实就是轮询策略与按消息键保序策略相结合
轮询策略: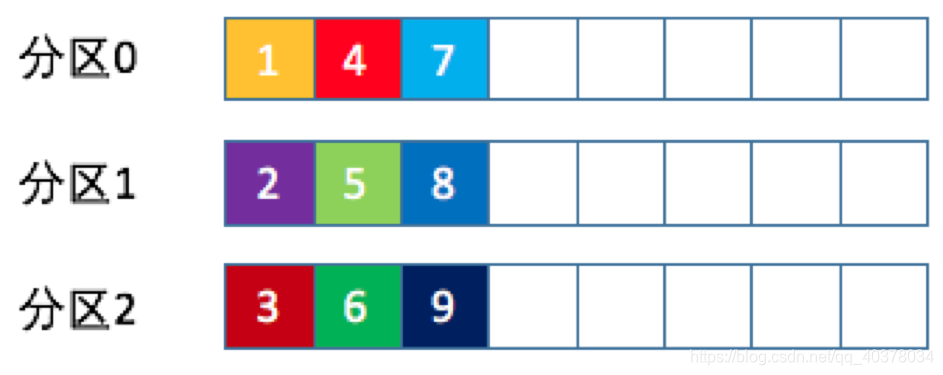
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上
按消息键保序策略: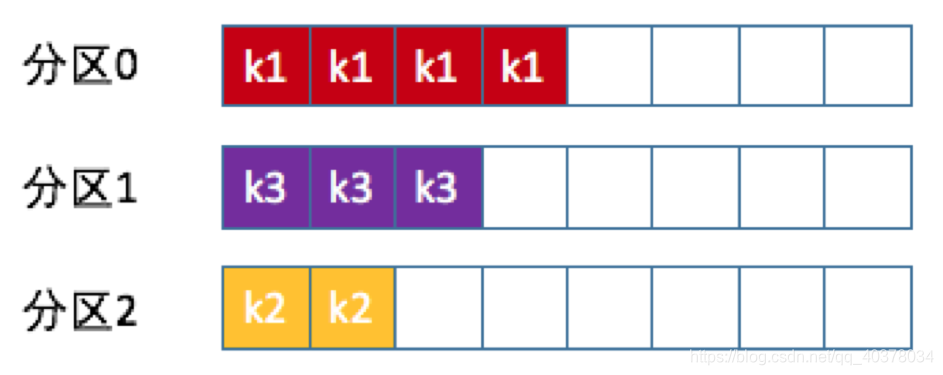 Kafka允许为每条消息定义消息键,简称为key。一旦消息被定义了key,那么就可以保证同一个key的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故整个策略被称为按消息键保序策略
Kafka允许为每条消息定义消息键,简称为key。一旦消息被定义了key,那么就可以保证同一个key的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故整个策略被称为按消息键保序策略
2)、随机策略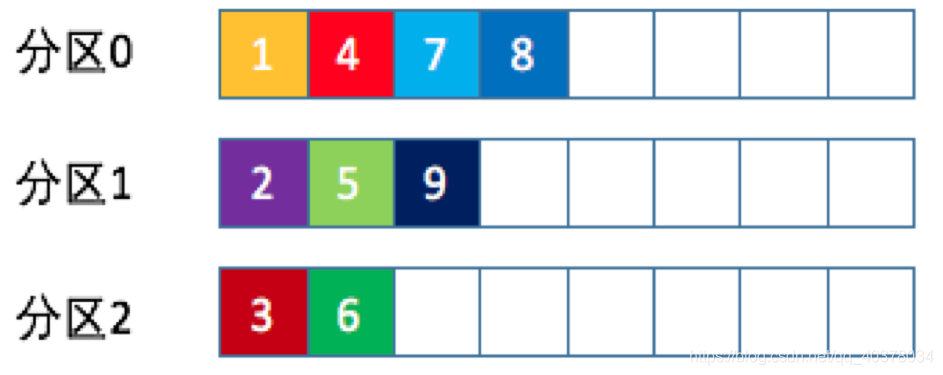 如果要实现随机策略版的partition方法,代码如下:
如果要实现随机策略版的partition方法,代码如下:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数
总结:
Kafka和RabbitMQ的学习告一段落了,推荐一些相关的学习资料,首先推荐两本好书:《深入理解Kafka核心设计与实践原理》和《RabbitMQ实战指南》,这两本是同一个人写的(作者CSDN博客 ),书中对Kafka和RabbitMQ的相关知识点介绍很详细。但是缺少与Spring整合相关的内容,关于Spring整合这部分,RabbitMQ的话推荐一下慕课网的《RabbitMQ消息中间件技术精讲》,这门课程里面对于Spring、SpringBoot、SpringCloud整合RabbitMQ都做了详细地讲解,至于Spring整合Kafka这方面的资料相对较少,推荐一篇技术博客,是我找到的关于Spring-Kafka方面相对介绍的比较详细的资料了,或者可以查看官方文档,此外,最近也在学习极客时间的《Kafka核心技术与实战》课程,学习到新的知识会在这篇博客中继续作补充,欢迎一起交流Kafka和RabbitMQ的相关知识
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
