社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
Apache Kafka是一个分布式的流处理平台。它具有以下特点:
Kafka的基本数据单元被称为message(消息),为减少网络开销,提高效率,多个消息会被放入同一批次(Batch)中后再写入。
Kafka的消息通过Topics(主题)进行分类,一个主题可以被分为若干个Partitions(分区),一个分区就是一个提交日志(commit log)。消息以追加的方式写入分区,然后以先入先出的顺序读取。Kafka通过分区来实现数据的冗余和伸缩性,分区可以分布在不同的服务器上,这意味着一个Topic可以横跨多个服务器,以提供比单个服务器更强大的性能。
由于一个Topic包含多个分区,因此无法在整个Topic范围内保证消息的顺序性,但可以保证消息在单个分区内的顺序性。
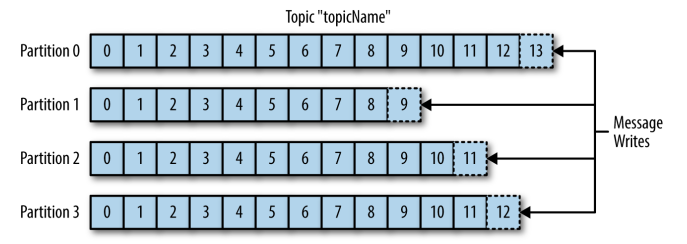
生产者负责创建消息。一般情况下,生产者在把消息均衡地分布到在主题的所有分区上,而并不关心消息会被写到哪个分区。如果我们想要把消息写到指定的分区,可以通过自定义分区器来实现。
消费者是消费者群组的一部分,消费者负责消费消息。消费者可以订阅一个或者多个主题,并按照消息生成的顺序来读取它们。消费者通过检查消息的偏移量(offset)来区分读取过的消息。偏移量是一个不断递增的数值,在创建消息时,Kafka会把它添加到其中,在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的偏移量保存在Zookeeper或Kafka上,如果消费者关闭或者重启,它还可以重新获取该偏移量,以保证读取状态不会丢失。
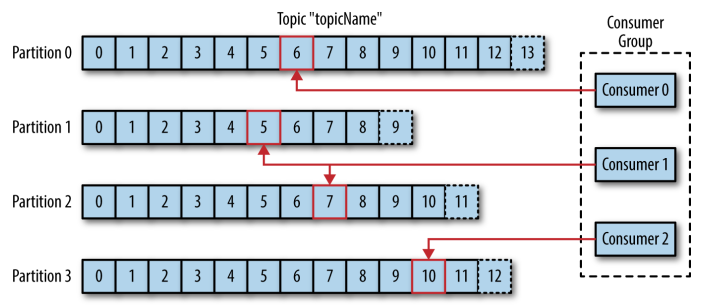
一个分区只能被同一个消费者群组里面的一个消费者读取,但可以被不同消费者群组中所组成的多个消费者共同读取。多个消费者群组中消费者共同读取同一个主题时,彼此之间互不影响。
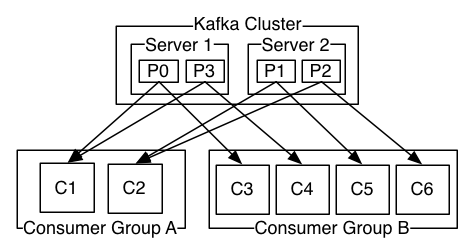
一个独立的Kafka服务器被称为Broker。Broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。Broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘的消息。
Broker是集群(Cluster)的组成部分。每一个集群都会选举出一个Broker作为集群控制器(Controller),集群控制器负责管理工作,包括将分区分配给Broker和监控Broker。
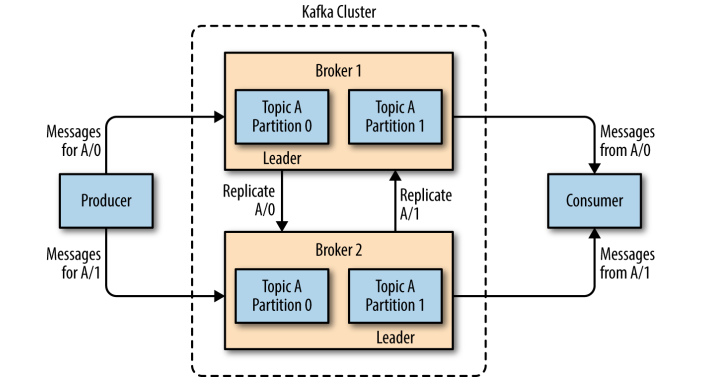
在集群中,一个分区(Partition)从属一个Broker,该Broker被称为分区的首领(Leader)。一个分区可以分配给多个Brokers,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果有一个Broker失效,其他Broker可以接管领导权。
Neha Narkhede, Gwen Shapira ,Todd Palino(著) , 薛命灯(译) . Kafka权威指南 . 人民邮电出版社 . 2017-12-26
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
