社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1.暴力模拟登陆
暴力模拟登陆:忽略web设计原理,忽略登陆需求,硬性的将cookie取出加载爬虫当中进行登录。
2.原理分析模拟登陆
原理分析模拟登陆: 根据网站源码和抓包请求,分析网站登录原理,用代码依照登录原理向服务器具体接口提交具体数据,实现模拟登录,技术含量最高,难度最大。
3.浏览器驱动模拟登陆
浏览器驱动模拟登陆:使用Python调用浏览器驱动,执行浏览器行为(发送数据,点击),进行模拟登陆,这种模拟登陆由于难度低,逐渐被一些项目认可,但是效率低。
(1)正常浏览器模拟登陆
(2)无头浏览器模拟登陆
1.cookie定义
(1)Cookie(曲奇,小饼干):是服务器下发给浏览器用于识别用户身份的校验值。
(2)Cookie是实现当前web身份识别的基础手段,具有一定的不安全性,因为:
①cookie下发,浏览器可以拒收
②cookie下发到浏览器本地,容易被重写伪装
2.查看cookie下发和提交
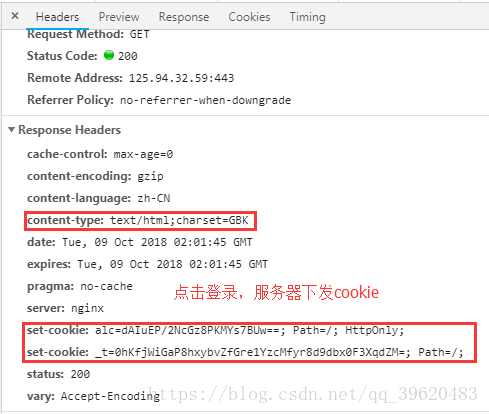
以京东登录为例我们来查看cookie的下发和提交
(1)cookie下发
Cookie的下发是在和http请求的response headers当中,且响应里提到了字符集是GBK
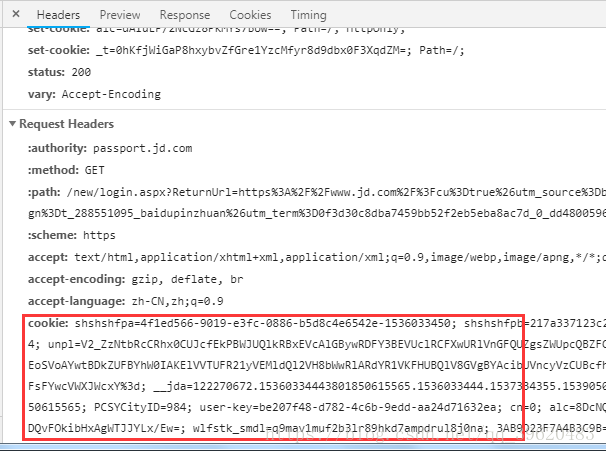
(2)cookie提交
Cookie的提交是携带在http request headers当中
3.cookie总结
有上面得到我们在写爬虫的时候
(1)需要关心cookie的下发,我们需要保存下发的cookie来维持自己的身份
(2)需要关心提交的cookie
(3)所有的Python爬虫模块默认都不携带cookie
1.urllib系列
Urllib系列保存cookie需要借助一个内置模块
Python2 : cookielib
Python3 : http.cookiejar
(1)不保存cookie
① 代码
# coding:utf-8
from urllib import request
url = "https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F%3Fcu%3Dtrue%26utm_source%3Dbaidu-pinzhuan%26utm_medium%3Dcpc%26utm_campaign%3Dt_288551095_baidupinzhuan%26utm_term%3D0f3d30c8dba7459bb52f2eb5eba8ac7d_0_dd4800596ab14fa5bac1401bf9aba6f8"
headers = {
"referer": "https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_dd4800596ab14fa5bac1401bf9aba6f8",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
# 构造登录请求
req = request.Request(url,headers=headers)
response = request.urlopen(req)
result = response.read().decode("gbk")
print(result)
② 结果
(2)保存cookie
① 代码
# coding:utf-8
from urllib import request
import http.cookiejar
url = "https://passport.jd.com/new/login.aspx?ReturnUrl=https%3A%2F%2Fwww.jd.com%2F%3Fcu%3Dtrue%26utm_source%3Dbaidu-pinzhuan%26utm_medium%3Dcpc%26utm_campaign%3Dt_288551095_baidupinzhuan%26utm_term%3D0f3d30c8dba7459bb52f2eb5eba8ac7d_0_dd4800596ab14fa5bac1401bf9aba6f8"
headers = {
"referer": "https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_dd4800596ab14fa5bac1401bf9aba6f8",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
# 构造登录请求
req = request.Request(url,headers=headers)
# 声明cookie容器,路径是cookie保存的路径
cookie = http.cookiejar.MozillaCookieJar("cookie.txt")
# 创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
# 构造自己的请求器
opener = request.build_opener(handler)
# 发起请求
response = opener.open(req)
# 保存cookie
cookie.save(ignore_discard=True,ignore_expires=True)
result = response.read().decode("gbk")
print(result)
② 结果
打开保存下来的cookie文件
2.requests系列
(1)Requests.session
① Requests是手写Python最受欢迎的模块,但是和urllib一样,他默认不保存cookie,
② 如果涉及到cookie就要用request.session方法来实现。
(2)Post模拟登陆分析
① 页面请求分析
以我爱我家为例,从登录页开始,在打开登录页前打开抓包工具
② 找对应url的包
③ 查看下发的cookie
确定请求成功,和发现请求登录页面(不是请求登录),服务器下发了cookie,那么这样很可能在我们请求登录的时候,服务器要检测cookie,所以我们要记录这里的cookie
④ 开始页面结构分析
▲ 提交的表单是不是在当前页,防止iframe标签
▲ 查看是否是常规的form表单提交
• 有没有action和method
• Action提交的位置,默认为当前url
• Method 提交的方式 默认为get
• 是否有submit按钮
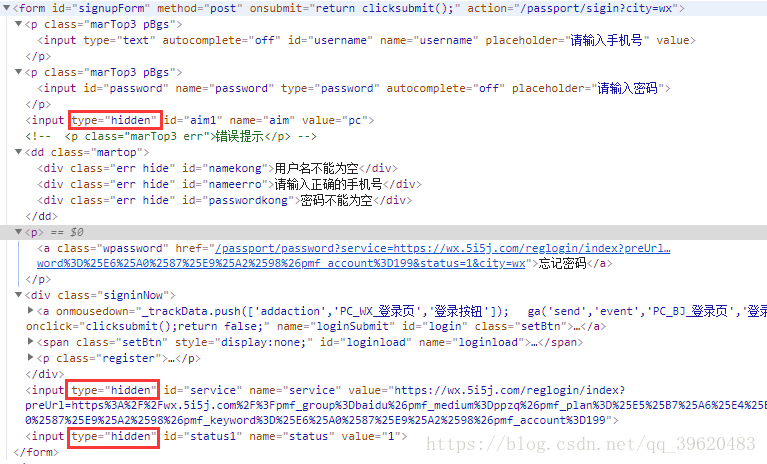
• 查看表单是否有hidden域
input的类型为hidden的时候,在HTML当中不会显示,但是可以提交
⑤ 分析总结
▲ 登录是一个post请求
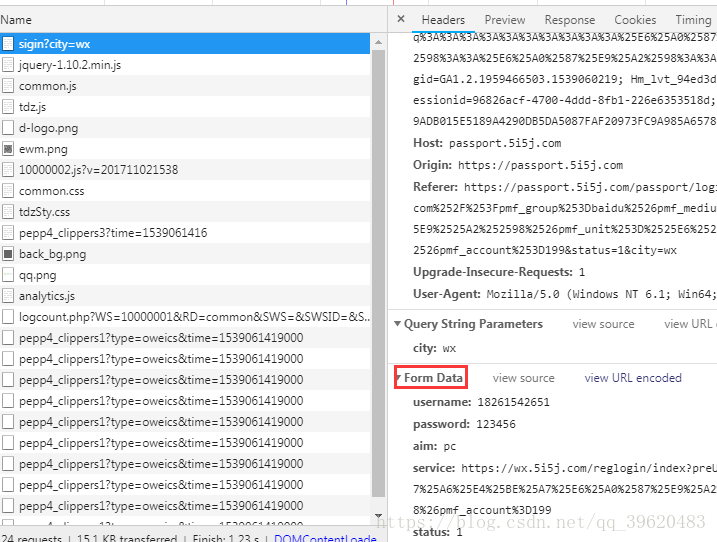
▲ 登录的数据传递给了/passport/sigin?city=wx,所以一会儿要抓这个包
▲ 我们请求登录的数据是:input传值是根据name传的
username、password、aim、service、status
⑥ 测试请求数据
返回状态为200,表示请求成功
form-data和刚才我们分析的form请求数据进行比对(用户名密码加3个参数),发现一致,那么可以爬取了。
(3)代码如下
① 获取cookie
• 代码
# coding:utf-8
import requests
# 请求登录页面,获取cookie
login_index_url = "https://passport.5i5j.com/passport/login?service=https%3A%2F%2Fwx.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fwx.5i5j.com%252F%253Fpmf_group%253Dbaidu%2526pmf_medium%253Dppzq%2526pmf_plan%253D%2525E5%2525B7%2525A6%2525E4%2525BE%2525A7%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_unit%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_keyword%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_account%253D199&status=1&city=wx"
login_index_headers = {
"Referer": "https://wx.5i5j.com/?pmf_group=baidu&pmf_medium=ppzq&pmf_plan=%E5%B7%A6%E4%BE%A7%E6%A0%87%E9%A2%98&pmf_unit=%E6%A0%87%E9%A2%98&pmf_keyword=%E6%A0%87%E9%A2%98&pmf_account=199",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
#为了保存cookie我们用requests.session进行请求
session = requests.session()
login_index_response = session.get(login_index_url,headers=login_index_headers)
result = login_index_response.content.decode()
cookies = login_index_response.cookies
for cookie in cookies:
print(cookie)
• 结果
② 获取form hidden的值
• 代码
# coding:utf-8
import requests
from lxml import etree
# 请求登录页面,获取cookie
login_index_url = "https://passport.5i5j.com/passport/login?service=https%3A%2F%2Fwx.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fwx.5i5j.com%252F%253Fpmf_group%253Dbaidu%2526pmf_medium%253Dppzq%2526pmf_plan%253D%2525E5%2525B7%2525A6%2525E4%2525BE%2525A7%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_unit%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_keyword%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_account%253D199&status=1&city=wx"
login_index_headers = {
"Referer": "https://wx.5i5j.com/?pmf_group=baidu&pmf_medium=ppzq&pmf_plan=%E5%B7%A6%E4%BE%A7%E6%A0%87%E9%A2%98&pmf_unit=%E6%A0%87%E9%A2%98&pmf_keyword=%E6%A0%87%E9%A2%98&pmf_account=199",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
# 为了保存cookie我们用requests.session进行请求
session = requests.session()
login_index_response = session.get(login_index_url,headers=login_index_headers)
result = login_index_response.content.decode()
html = etree.HTML(result)
# 取出aim的值
aim = html.xpath(r"//input[@id='aim1']")[0].attrib
aim = aim["value"]
# 取出service的值
service = html.xpath(r"//input[@id='service']")[0].attrib
service = service["value"]
# 取出status的值
status = html.xpath(r"//input[@id='status1']")[0].attrib
status = status["value"]
# 打印出三个值
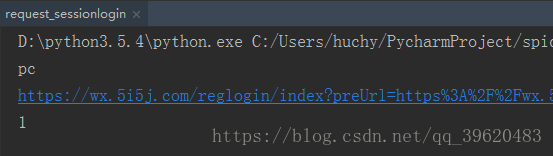
print(aim)
print(service)
print(status)
• 结果
③ 完整请求登录代码
# coding:utf-8
import requests
from lxml import etree
# 请求登录页面,获取cookie
login_index_url = "https://passport.5i5j.com/passport/login?service=https%3A%2F%2Fwx.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fwx.5i5j.com%252F%253Fpmf_group%253Dbaidu%2526pmf_medium%253Dppzq%2526pmf_plan%253D%2525E5%2525B7%2525A6%2525E4%2525BE%2525A7%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_unit%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_keyword%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_account%253D199&status=1&city=wx"
login_index_headers = {
"Referer": "https://wx.5i5j.com/?pmf_group=baidu&pmf_medium=ppzq&pmf_plan=%E5%B7%A6%E4%BE%A7%E6%A0%87%E9%A2%98&pmf_unit=%E6%A0%87%E9%A2%98&pmf_keyword=%E6%A0%87%E9%A2%98&pmf_account=199",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
#为了保存cookie我们用requests.session进行请求
session = requests.session()
login_index_response = session.get(login_index_url,headers=login_index_headers)
result = login_index_response.content.decode()
html = etree.HTML(result)
aim = html.xpath(r"//input[@id='aim1']")[0].attrib
aim = aim["value"]
service = html.xpath(r"//input[@id='service']")[0].attrib
service = service["value"]
status = html.xpath(r"//input[@id='status1']")[0].attrib
status = status["value"]
data = {
"username": "182xxxxxxxx",
"password": "xxxxxx",
"aim": aim,
"service": service,
"status":status
}
# 请求登录的url
login_url = "https://passport.5i5j.com/passport/sigin?city=wx"
login_headers = {
"https":"//passport.5i5j.com/passport/login?service=https%3A%2F%2Fwx.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fwx.5i5j.com%252F%253Fpmf_group%253Dbaidu%2526pmf_medium%253Dppzq%2526pmf_plan%253D%2525E5%2525B7%2525A6%2525E4%2525BE%2525A7%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_unit%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_keyword%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526pmf_account%253D199&status=1&city=wx",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
}
login_response = session.post(login_url,headers =login_headers,data = data )
login_result = login_response.content.decode()
print(login_result)
• 结果
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!