社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
怎么样才能爬得更快一点呢?

在 python爬虫入门实战!爬取博客文章标题和链接! 上一篇文章我们已经学会基本用法了。最近我又学到一新技能,让它爬的更快一些。
python3 、 正则表达式库 re 、多线程库 multiprocessing 、和第三方库 requests 。 安装这里就不再叙述啦。
引入库。
import requests
import re
from multiprocessing.dummy import Pool
什么是多线程?先从单线程说起。比如,我在写这篇文章,写完后我去听歌,对于写文章和听歌来说,是单线程,是一个接着一个。我也可以一边写文章一边听歌,这就成了多线程,是同时进行的。
上一篇文章中,我们是一页一页的爬。现在我们把他改成三页三页的爬。
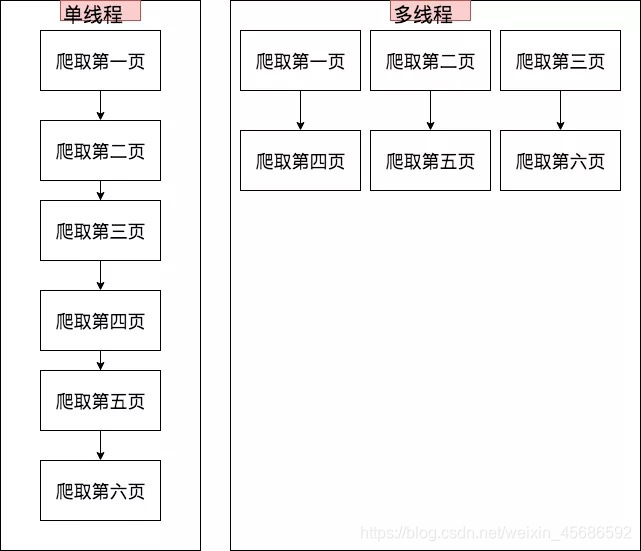
一起看看python是如何使用多线程的。
# 创建三个线程
pool = Pool(3);
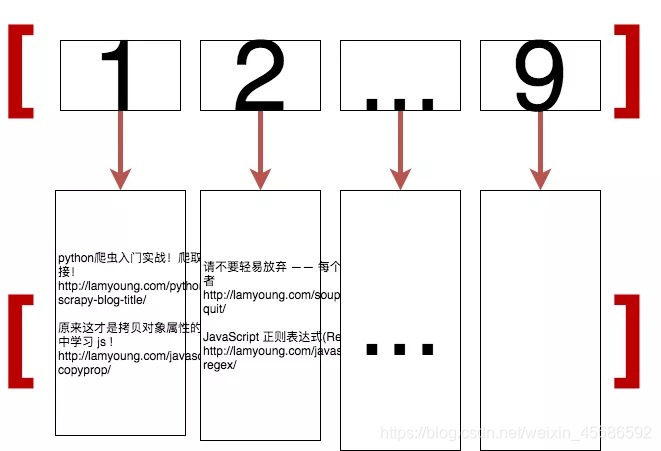
# 爬取的页码放在一个列表里 [1,2,3,...,9]
orign_num = [x for x in range(1,10)];
# 通过映射返回结果列表
result = pool.map(scrapy,orign_num);
pool.map 是使用了映射,把 orign_num 里的每一个数值传给 scrapy ,并返回到对应的结果里。
再一起看看,爬取一页的代码。看不懂的话,一定要回到上一篇的分析哦。
regex = r"<a href="(.*)">[s]*?<h2 class="post-title">[s]*(.*)[s]*</h2>[sS]*?</a>"
def scrapy(index):
page_url = '';
if index>1:
page_url=f'page{index}/'
url=f'http://lamyoung.com/{page_url}';
html=requests.get(url);
if html.status_code == 200:
html_bytes=html.content;
html_str=html_bytes.decode();
all_items=re.findall(regex,html_str);
write_content=''
for item in all_items:
write_content=f'{write_content}n{item[1]}nhttp://lamyoung.com{item[0]}n'
return write_content
else:
return ''
最后把结果存起来。
write_content = '';
for c in result:
write_content+=c;
with open('lamyoung_title_multi_out.txt','w',encoding='utf-8') as f:
f.write(write_content)
我们这次多线程用到的是 multiprocessing.dummy 里的 Pool 。利用map 映射出每一页的爬虫结果。
以上就是我最新学到的东西。如有错误,欢迎斧正!后续有更好的内容一定会第一时间分享给大家,点个关注不迷路。
我是白玉无冰,游戏开发小赤佬,也玩python和shell
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
