社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在网易云课堂上看的教学视频,现在来巩固一下知识:

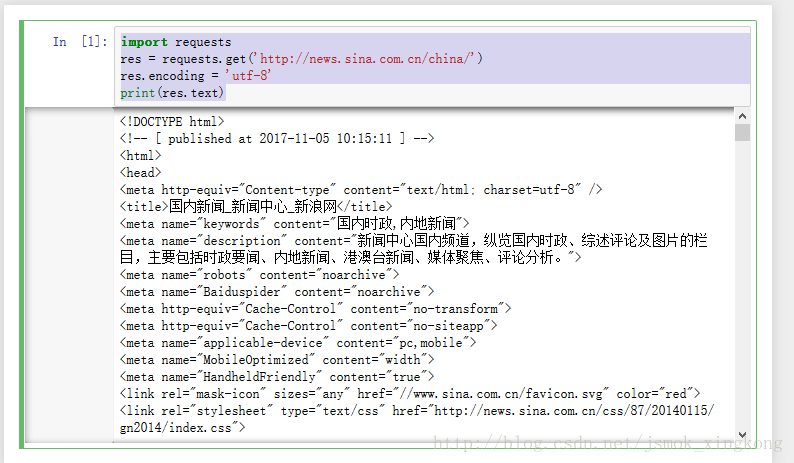
import requests #跟java的导包差不多,python叫导入库
res = requests.get('http://news.sina.com.cn/china/')#爬取网页内容
res.encoding = 'utf-8' #将得到的网页内容转码,避免乱码
print(res.text) #将网页内容以text形式输出
2.简单学习BeautifulSoup
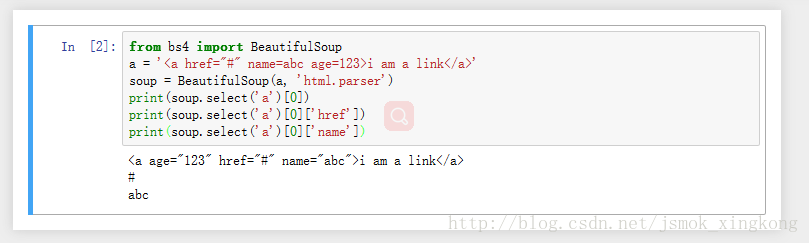
from bs4 import BeautifulSoup
a = '<a href="#" name=abc age=123>i am a link</a>'
soup = BeautifulSoup(a, 'html.parser') #html.parser为语法剖析器
print(soup.select('a')[0]) #得到a标签里的内容
print(soup.select('a')[0]['href']) #得到a标签里href的内容
print(soup.select('a')[0]['name']) #得到a标签里age的内容
3.正式抓取新浪新闻网页:
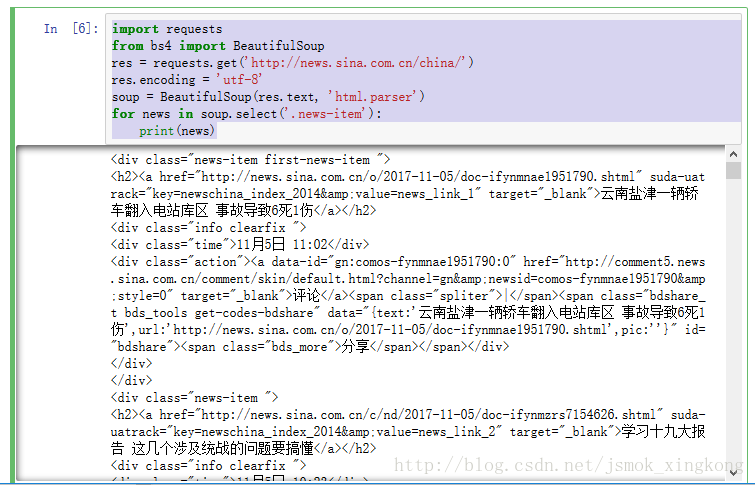
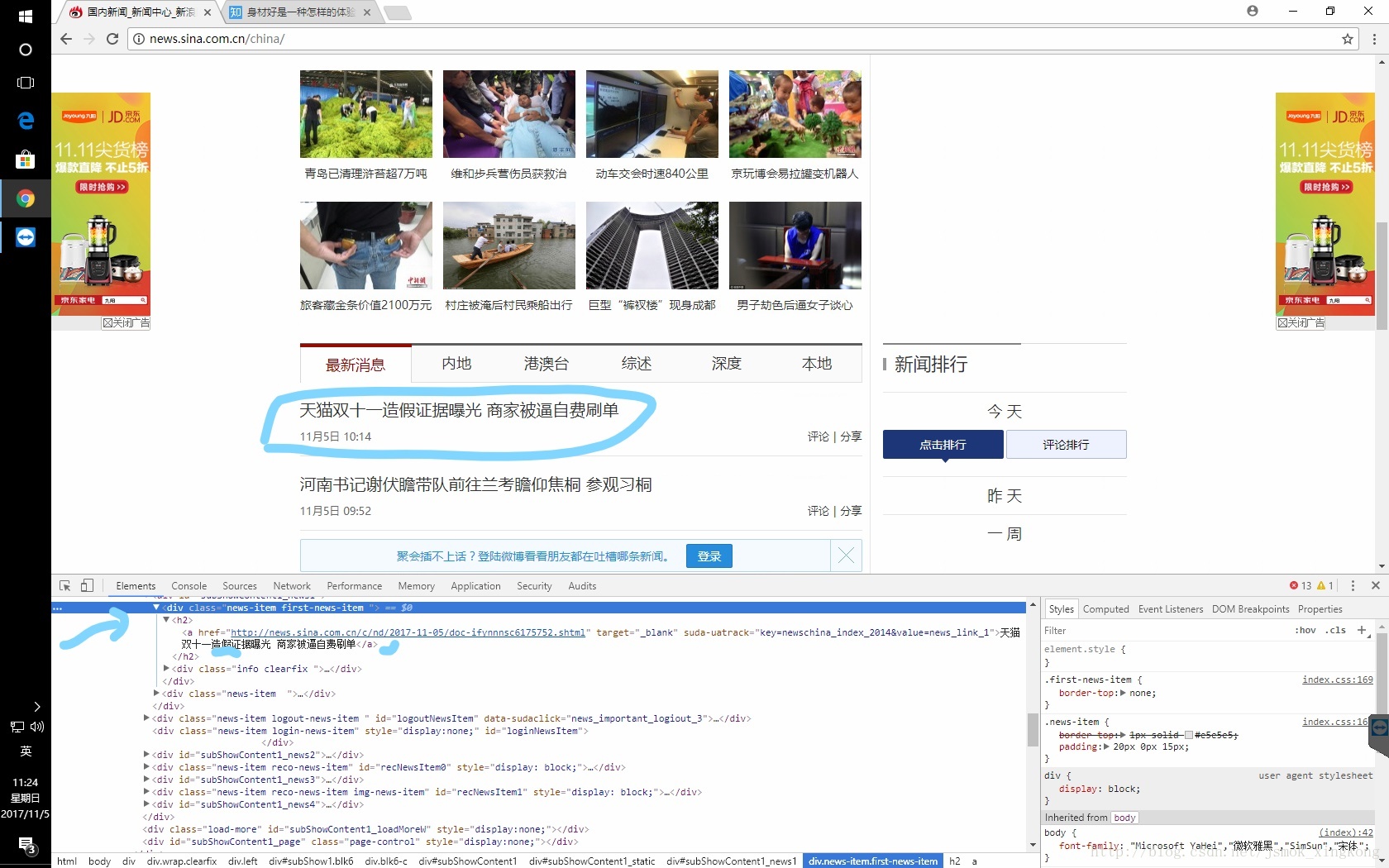 可以看出新闻标题,时间, 链接都放在了.news-item下
可以看出新闻标题,时间, 链接都放在了.news-item下import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
for news in soup.select('.news-item'): #.news-item是一个class,如果是id的话可以改为'#news-item'
print(news)
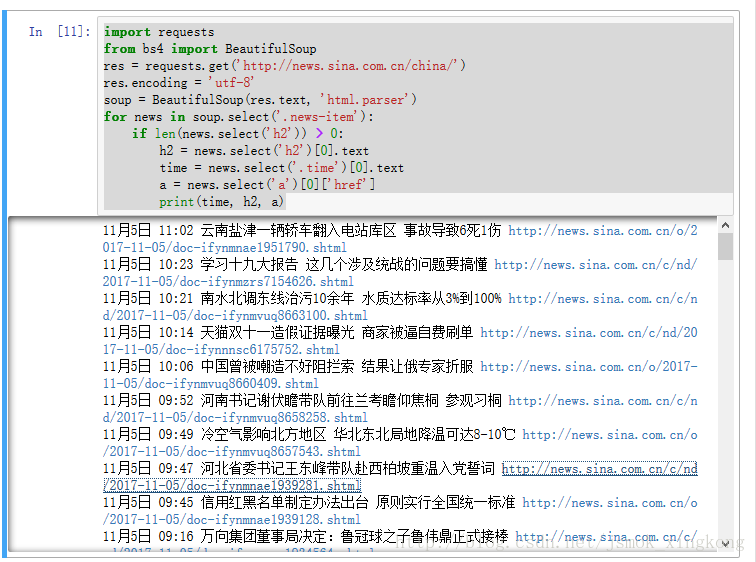
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
for news in soup.select('.news-item'):
if len(news.select('h2')) > 0:
h2 = news.select('h2')[0].text #得到h2标签里的文字
time = news.select('.time')[0].text
a = news.select('a')[0]['href'] #得到a标签里的链接
print(time, h2, a) #打印抓取的内容
爬取新浪网页先写到这里,等以后学新的知识在写剩下的内容
现在是福利时间,这个是我在知乎上看到的一个python爬虫程序:50⾏python爬⾍代码, 带你正确打开知乎新世界!
新学了python,就想拿这个练练手,里面有源程序,只不过我改的更简洁了一点代码量少了一半以上,哈哈
改正后的代码 Ps:如果如果想运行的必须把知乎原本的代码下载下来,最好还是把源码分析(知乎上有)看一遍,再来看我这个,里面有文件夹的结构可以不用自己建,然后把下面这段代码替代原来的代码。注意是python3
from selenium import webdriver
#import time
import urllib.request
from bs4 import BeautifulSoup
def main():
# ********* Open chrome driver and type the website that you want to view ***********************
driver = webdriver.Firefox() # 打开浏览器
# 列出来你想要下载图片的网站
# driver.get("https://www.zhihu.com/question/35931586") # 你的日常搭配是什么样子?
# driver.get("https://www.zhihu.com/question/19671417") # 拍照时怎样摆姿势好看?
# driver.get("https://www.zhihu.com/question/26037846") # 什么脸型的女生好看?
# **************** Prettify the html file and store raw data file *****************************************
result_raw = driver.page_source # 这是原网页 HTML 信息
result_soup = BeautifulSoup(result_raw, 'html.parser')
count = 0
with open("./output/rawfile/img_meta.txt", 'w',) as img_meta: #打开文件必须是先存在
for rich in result_soup.select('noscript'):
img_url = rich.select('img')[0]['src'] #得到下载图片的连接
line = str(count) + "t" + img_url + "n"
img_meta.write(line) #可以学也可以不写
urllib.request.urlretrieve(img_url, "./output/image/" + str(count) + ".jpg") # 一个一个下载图片,这个urllib具体用法还不知道
count += 1
img_meta.close()
print("Store meta data and images successfully!!!")
if __name__ == '__main__':
main()
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!