社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
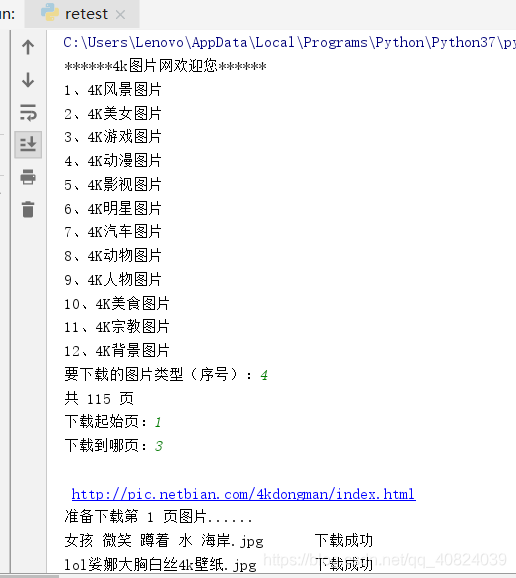
1.可选择图片类型、下载那几页。

2.源代码
"""
功能:批量下载网站图片
时间:2019-5-18 16:14:01
作者:倚窗听雨
"""
import urllib.request
import re
import os
headers = {
"User-Agent":"yjs_id=0c19bb42793fd5c3c8c228f50173ca19; Hm_lvt_14b14198b6e26157b7eba06b390ab763=1529398363; __cfduid=de4421757fb00c0120063c1dbd0308e511558166501; ctrl_time=1; Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1558166930; zkhanecookieclassrecord=%2C66%2C; PHPSESSID=6bee044771973aba4aa5b989f1a3722d; zkhanmlusername=qq_%B7%E7%BE%ED%B2%D0%D4%C6186; zkhanmluserid=1380421; zkhanmlgroupid=1; zkhanmlrnd=4g6arf9678I6URIitCJ2; zkhanmlauth=1b4f3205834ec05575588adc84c0eb52; zkhandownid24031=1; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1558167143; security_session_verify=eb4cb5687c224e77089c64935fa16df8",
}
ur = "http://pic.netbian.com"
url_list = []
#获取各类型图片url
def picture(url):
res = urllib.request.Request(url,data=None,headers=headers)
html = urllib.request.urlopen(res).read().decode('gb2312')
pic = re.findall(r'<div class="classify clearfix.+</div>',html)
start = 0
text = pic[0]
for i in re.findall(r'<a ',pic[0]):
a = re.search(r'<a ',text)
end_a = re.search(r'</a>',text)
href = url+text[a.start():end_a.end()].split('"')[1]
title = text[a.start():end_a.end()].split('"')[3]
d = {'href':href,'title':title}
url_list.append(d)
text = text[end_a.end():]
#获取图片链接
def get_pic(url):
res = urllib.request.Request(url,headers=headers)
html = urllib.request.urlopen(res).read().decode('gbk')
page = re.search(r'class="slh".+[s].+',html).group().split('</a')[0].split('>')[-1]
print('共',page,'页')
start_page = int(input('下载起始页:'))
end_page = int(input('下载到哪页:'))
total = 0
for p in range(start_page,end_page+1):
if p ==1:
url2 = url + 'index'+'.html'
else:
url2 = url + 'index_'+str(p)+'.html'
print('n',url2)
res2 = urllib.request.Request(url2, headers=headers)
html2 = urllib.request.urlopen(res2).read().decode('gbk')
texts =re.findall(r'<ul class="clearfix".+[s]*.+',html2)
t = texts[0]
print('准备下载第',p,'页图片......')
#获取当前页的图片并下载
for i in re.findall(r'<li>',t):
start_li = re.search(r'<li>',t)
end_li = re.search(r'</li>',t)
href = ur+t[start_li.start():end_li.end()].split('"')[1]
name = t[start_li.start():end_li.end()].split('b>')[-2][:-2]
total += download(href,name)
t = t[end_li.end():]
print('n下载完成,共下载{}张图片'.format(total))
#下载图片
def download(url,name):
res = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(res).read().decode('gbk')
down_url = re.search(r'<a href="" id="img">.+',html).group()
down_url = ur + re.split('"',down_url)[5]
try:
data = urllib.request.urlopen(down_url,timeout=10).read()
except Exception as e:
print(e,'跳过此图片:'+name+'.jpg')
return 0
t = -1
#img目录不存在自动创建
if not os.path.exists('img'):
os.makedirs('img')
#该文件不存在时才下载(存储位置可自行修改,现在存在当前目录的img目录下)
if not os.path.exists('img\'+name+'.jpg'):
with open('img\'+name+'.jpg','wb')as f:
f.write(data)
print(name+'.jpg'+"tt下载成功")
t = 1
else:
print(name + '.jpg' + "tt已存在")
t = 0
return t
#主程序
def main():
picture("http://pic.netbian.com")
print('4k图片网欢迎您'.center(20,'*'))
for i,v in enumerate(url_list):
print("{}、{}".format(i+1,v['title']))
while True:
try:
t = int(input('要下载的图片类型(序号):'))
if t not in range(1,13):
raise IndexError
break
except ValueError:
print('请输入正确的序号!')
except IndexError:
print('请输入正确的序号!')
get_pic(url_list[t-1]['href'])
if __name__ == '__main__':
main()
存储位置可自行修改,现在存在当前目录的img目录下
声明:初次学习爬虫,还有诸多不足,大神勿喷。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
