社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
A、分析:
申明:本人以学习为目的,分享技术代码,禁止用于商业用途和网站攻击,出现问题与本人无关。
这两天在研究12306的订票网站,本想着自己写个小程序来实现买票的,也当熟悉python语法了,在实现过程中遇到了两个难点,又赶上12306刷验证码频率太高,刷不出来,正好搞点小程序来实践下。先来说下12306遇到的难点:
1.验证码识别,深度学习算法可以实现95%左右的成功率,当然了算法这块后续在研究,现在在看大神的作品来找灵感,自己先手动输入像素来登陆验证。
2.动态js包抓取,调用的接口https://kyfw.12306.cn/otn/dynamicJs/qwErtul,后面qwErtul这个是动态生成的,也就是动态的qwErtul(一次失效)去抓取一个js包,这块估计是调用方式不对,这个预计好搞定。
好啦,来说说抓取妹子图图片,本着学习的目的,并无其他商业目的。
a)主页一共189页
b)每页最大24张缩略图
c)每个图片点击,个人写真图片30左右不等
d)想抓的数量是189*24*30,当然了这里还考虑很细节:比如最后一页不够24张缩略图的情况
e)开多线程来抓取,最大开到64个线程,后来图片刷不出来了,就给了8线程,每隔一秒保存一张
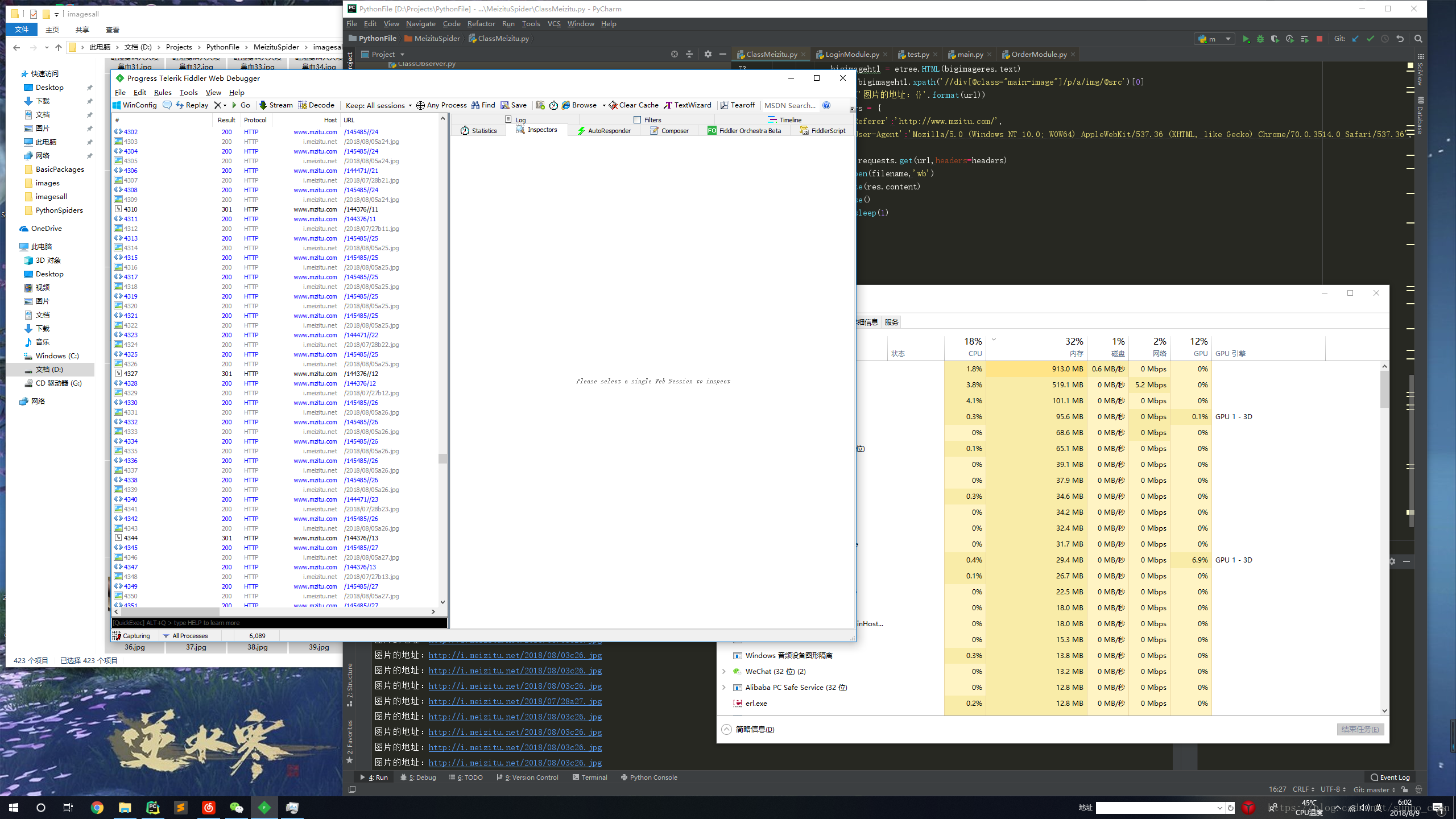
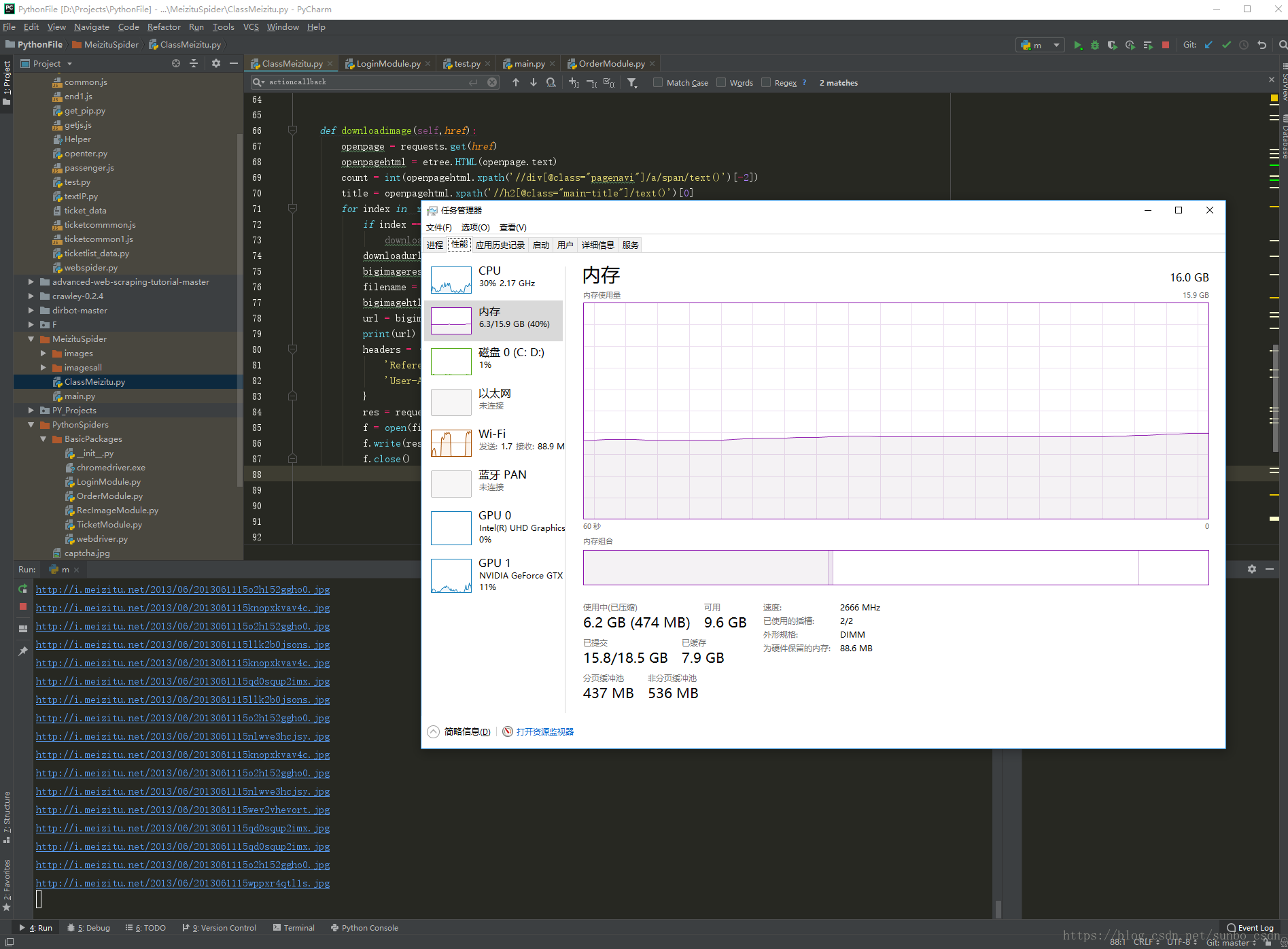
f)当然了,分享源代码后,可根据个人的机器性能,自己在本地跑,观察CPU,内存,磁盘的动态也是很cool的
B、代码
import requests,time,threading,datetime
from lxml import etree
import traceback
class Meizitu(object):
#主页连接
index_url = 'http://www.mzitu.com/'
# url集合
imagelist = []
def __init__(self):
pass
#开启线程
def threadStart(self):
for i in range(0,8):
print('启动线程'+str(i))
t = threading.Thread(target=self.actioncallback)
t.start()
#回调
def actioncallback(self):
print('执行任务')
if len(self.imagelist) > 0 :
for url in self.imagelist:
try:
print('池子里还有:{}个'.format(len(self.imagelist)))
self.GetUrlList(url)
self.imagelist.remove(url)
except BaseException:
print('异常了')
def loadurllist(self):
index_res = requests.get(self.index_url)
html = etree.HTML(index_res.text)
# 连接列表
hreflist = html.xpath('//div[@class="postlist"]//li/a/@href')
# 获取id元素
pagecount = int(html.xpath('//a[@class="page-numbers"]/@href')[-1][-4:-1])
print(pagecount)
for i in range(1,pagecount):
if i is 1:
index_url = 'http://www.mzitu.com/'
pass
else:
index_url = 'http://www.mzitu.com/page/{}/'.format(i)
print('新加入到池子主页地址:{}'.format(index_url))
self.imagelist.append(index_url)
print('添加后数量:{}'.format(len(self.imagelist)))
#获取下载连接
def GetUrlList(self,pageurl):
index_res = requests.get(pageurl)
html = etree.HTML(index_res.text)
#连接列表
hreflist = html.xpath('//div[@class="postlist"]//li/a/@href')
for href in hreflist:
self.downloadimage(href)
def downloadimage(self,href):
openpage = requests.get(href)
openpagehtml = etree.HTML(openpage.text)
count = int(openpagehtml.xpath('//div[@class="pagenavi"]/a/span/text()')[-2])
title = openpagehtml.xpath('//h2[@class="main-title"]/text()')[0]
for index in range(1,count):
if index == 1:
downloadurl = href
downloadurl = href + "//" + str(index)
bigimageres = requests.get(downloadurl)
filename = 'imagesall/{}{}.jpg'.format(title, str(index))
bigimagehtl = etree.HTML(bigimageres.text)
url = bigimagehtl.xpath('//div[@class="main-image"]/p/a/img/@src')[0]
print('图片的地址:{}'.format(url))
headers = {
'Referer':'http://www.mzitu.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3514.0 Safari/537.36',
}
res = requests.get(url,headers=headers)
f = open(filename,'wb')
f.write(res.content)
f.close()
time.sleep(1)
#模块测试入口
if __name__ == '__main__':
meizitu = Meizitu()
meizitu.loadurllist()
print(meizitu.imagelist)
meizitu.threadStart()C、本地效果图
D、总结
1.time.sleep等待一秒有点耗时,可以给小点,我开过64线程,不延迟的,导致图片刷不出来
2.熟练基本语法和python工具的使用
3.抓取页面基本功能实现没问题,正则表达式需要进一步熟悉,html解析实现方式需要各种第三方库都熟练使用
4.调用requests.get接口时候忘记了传递headers,接收到的content为空,调试这块花了挺长时间,细节上需要提升
5.多线程的使用需要花些时间来研究
6.后续花些时间来写一个免费公网ip的代理池,这样以后爬数据的时候能提升效率,实现分布式爬虫,多个机器同时跑
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!