社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
打开https://www.kugou.com/yy/rank/home/1-8888.html?from=rank只能显示前22名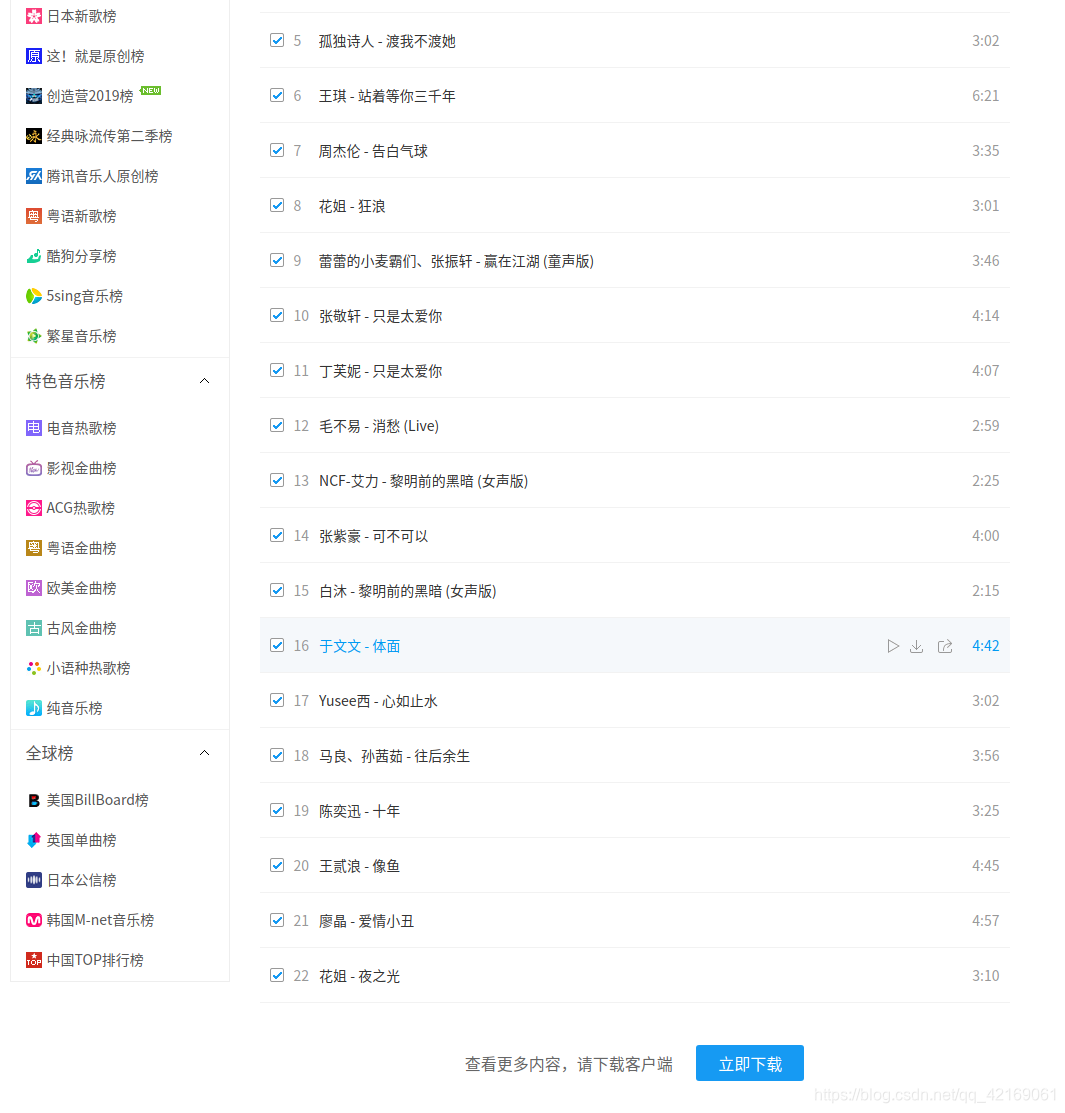
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
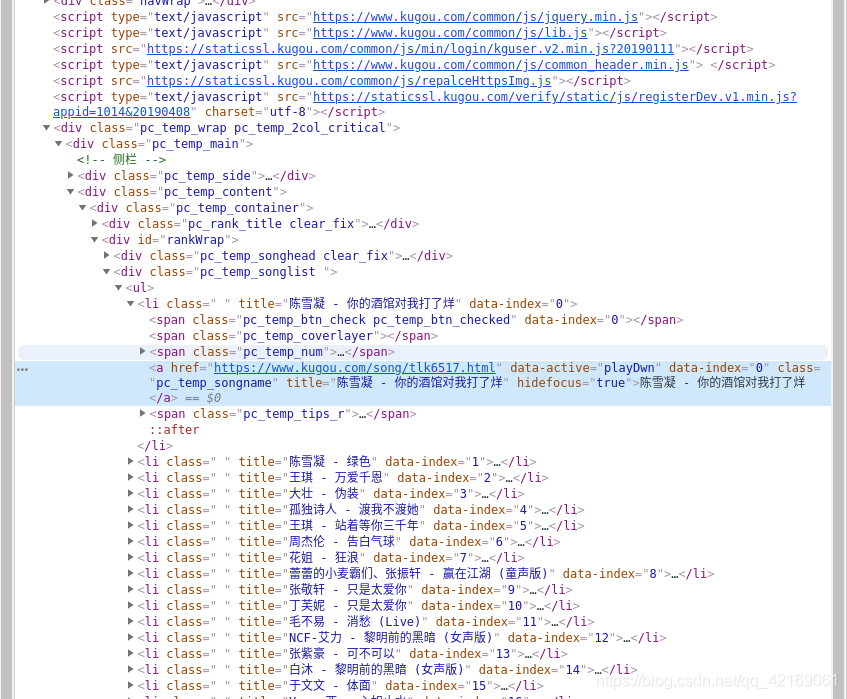
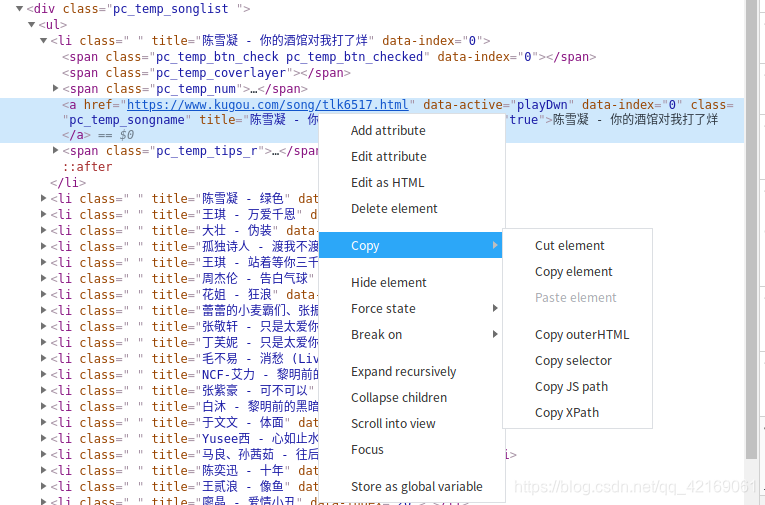
ranks = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
names = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
times = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
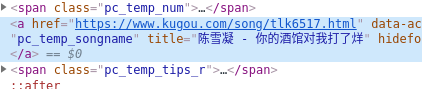
name = names[i].get_text().strip().split('-')[1]
signer = names[i].get_text().strip().split('-')[0]
# 封装成函数
def write_txt(message):
with open('../tmp/_02_kugou/kuGou.txt', 'a+') as f:
f.write(message + 'n')
# 在进行调用时要使用加号把多个元素连接
write_txt(rank + name + signer + time1)
def write_csv(rank, name, signer, time1):
with open('../tmp/_02_kugou/kuGou.csv', 'a+') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([rank, name, signer, time1])
def writer_mysql(rank, name, signer, time1):
con = pymysql.connect(user='root', password='root', db='spider', host='localhost', port=3306, charset='utf8')
cursor = con.cursor()
try:
sql = '''INSERT INTO kugou(rank, name, signer, time) VALUES('%d', '%s', '%s', '%s')'''
cursor.execute(sql % (int(rank), name, signer, pymysql.escape_string(time1)))
con.commit()
except pymysql.err.IntegrityError:
pass
cursor.close()
con.close()
使用模块MySQLdb自带的针对mysql的字符转义函数 escape_string把要存储的元素转义一下如
cursor.execute(sql % (int(rank), name, signer, pymysql.escape_string(time1)))
如果还是出现pymysql.err.ProgrammingError: 1064 错误就使用三引号’‘’ 来括取sql语句。应该就可以解决这个错误了
sql = '''INSERT INTO kugou(rank, name, signer, time) VALUES('%d', '%s', '%s', '%s')'''
cursor.execute(sql % (int(rank), name, signer, pymysql.escape_string(time1)))
if __name__ == '__main__':
urls = ['https://www.kugou.com/yy/rank/home/' + str(i) + '-8888.html' for i in range(1, 24)]
for url in urls:
print(url)
get_message(url)
time.sleep(5)
import csv
import time
import requests
from bs4 import BeautifulSoup
import os
import pymysql
if not os.path.exists('../tmp/_02_kugou'):
os.makedirs('../tmp/_02_kugou')
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
def get_message(url):
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
ranks = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
names = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
times = soup.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span')
# print(len(ranks))
for i in range(0, len(ranks)):
rank = ranks[i].get_text().strip()
name = names[i].get_text().strip().split('-')[1]
signer = names[i].get_text().strip().split('-')[0]
time1 = times[i].get_text().strip()
write_txt(rank + name + signer + time1)
write_csv(rank, name, signer, time1)
writer_mysql(rank, name, signer, time1)
# print(rank, name, signer, time1)
def write_txt(message):
with open('../tmp/_02_kugou/kuGou.txt', 'a+') as f:
f.write(message + 'n')
def write_csv(rank, name, signer, time1):
with open('../tmp/_02_kugou/kuGou.csv', 'a+') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([rank, name, signer, time1])
def writer_mysql(rank, name, signer, time1):
con = pymysql.connect(user='root', password='root', db='spider', host='localhost', port=3306, charset='utf8')
cursor = con.cursor()
try:
sql = '''INSERT INTO kugou(rank, name, signer, time) VALUES('%d', '%s', '%s', '%s')'''
cursor.execute(sql % (int(rank), name, signer, pymysql.escape_string(time1)))
con.commit()
except pymysql.err.IntegrityError:
pass
cursor.close()
con.close()
if __name__ == '__main__':
urls = ['https://www.kugou.com/yy/rank/home/' + str(i) + '-8888.html' for i in range(1, 24)]
for url in urls:
print(url)
get_message(url)
time.sleep(5)

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
