社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
本来这篇文章不想爬百度的,但是想到有人可能看到我上一篇博客之后,回去自己去爬百度美眉图
我也敢说,有很大一部分人学习爬虫都有爬百度美眉的想法,不然会感觉世界缺少了点啥,O(∩_∩)O哈哈~
上一篇文章也说了,百度不是那么容易爬的,因为百度的图片不是在html网页中直接展示的,给你展示的只是很少一部分。他们采用了AJAX(异步JavaScript和XML)
这样做的目的不是为了反爬虫,是因为这样节约网络流量啊,不用全部给你展示出来,当时鼠标发生某些动作之后再给你返回你想要的东西,这样就基本没有浪费了
那现在就带你look look,看我是如何解析动态页面的。
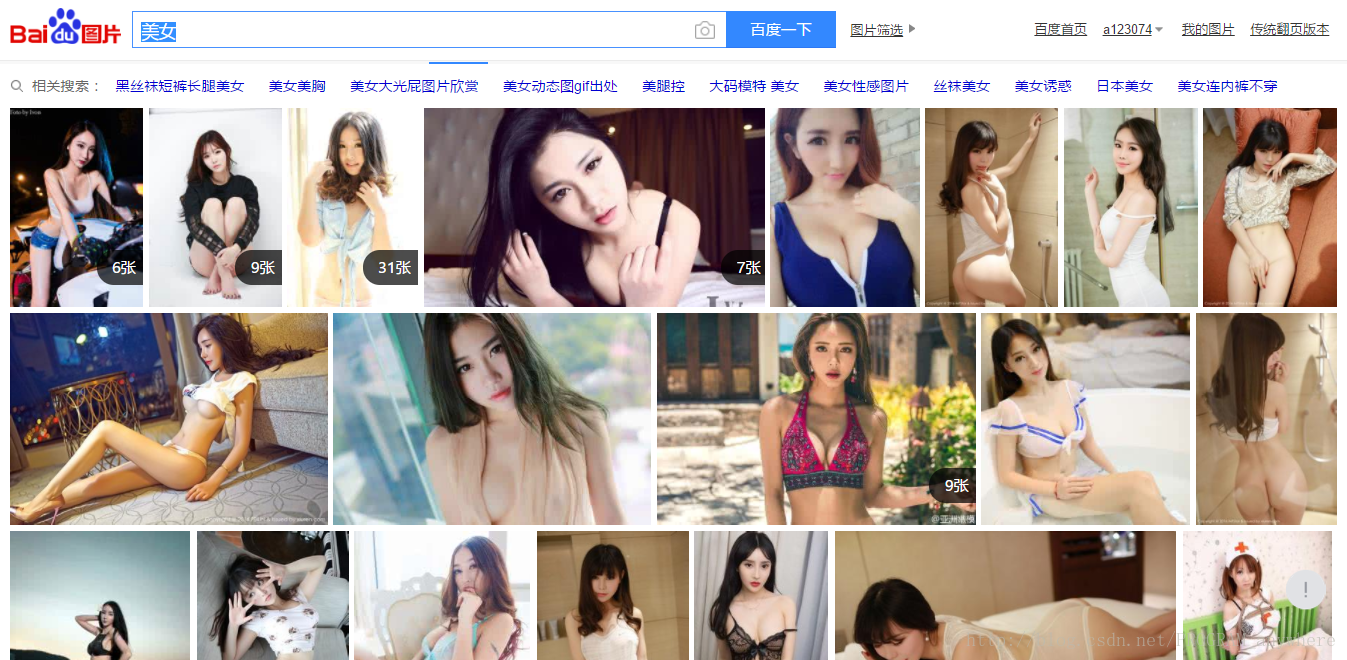
1.打开百度,搜索美女,如下:
(⊙o⊙)… 自己快受不了
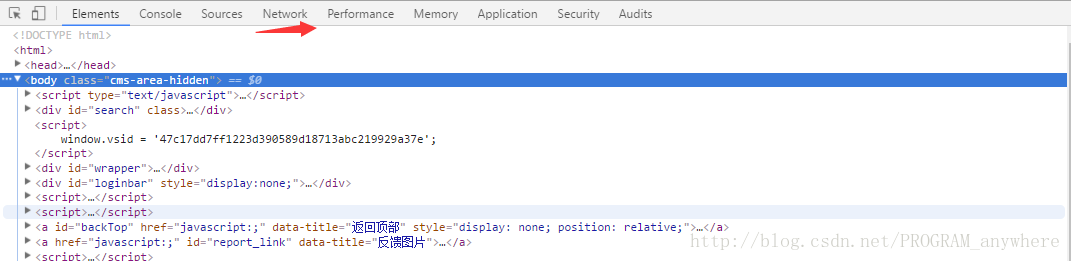
2.按F12(我用的是谷歌浏览器)开始找你想要的json文件
选中Network,再按F5 刷新一下
接下来的任务就很严峻了,你要在这么多的响应中找到你想要的东西。
网上好像也有些人解析动态网页的,说全局都要去看一边,我觉得很low,我自己总结了一些经验,但是你自己去多爬网页,然后总结你自己的经验吧。我觉得这个时候英文就很重要了,别人取名也不是乱取啊,肯定有自己的意义啊
你也不要盲目的找,你要明确你要找的东西是啥,上一篇文章我也说了爬图片的原理和步骤。
http://blog.csdn.net/program_anywhere/article/details/72853689
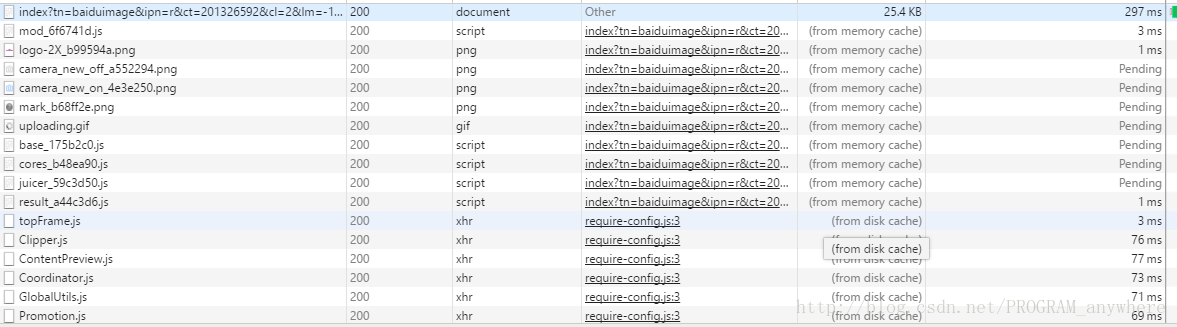
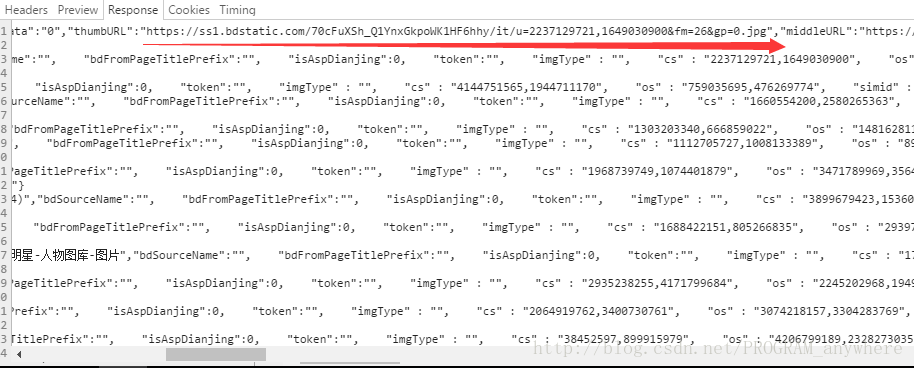
你要找的是url,不是一个两个url,而是是大量的url,你可以点击一个js响应请求,然后看右边的Response
这个是我找出来的,每个网站都不一样,你可以自己去找。
当你一看右边那么多的内容,然后还有美女啥的,这时候你的第7感就要起作用啊,很有可能是这个链接啊,你再往右边滑动一下
看看看,像不像图片的url。看到.jpg,你敢说不是么?
如果不确定,你可以再把链接复制下来,在浏览器中打开看看,看是不是一个活生生的大美眉,O(∩_∩)O哈哈~
看看我们找到的url开头(acjson)很明显嘛,不就是请求json文件么,所以英文真的还是很重要,但是如果你做多了,也能很快发现这些东西。
3.然后你要开始分析url
这一步至关重要。在上上面那个图中有两个acjson请求,你可以比较两个url的区别。
如果你在别的网页没有发现两个json文件也不用怕,既然是动态加载,你多动动你的鼠标,鼠标下滑两下就能出现新的东西了。
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%BE%8E%E5%A5%B3&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E7%BE%8E%E5%A5%B3&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn=30&rn=30&gsm=1e&1496580719340=
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%BE%8E%E5%A5%B3&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E7%BE%8E%E5%A5%B3&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn=60&rn=30&gsm=1e&1496580719347=
上面url可以简化为一下url
image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord=%E7%BE%8E%E7%9C%89&word=%E7%BE%8E%E7%9C%89&pn=30
image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&queryWord=%E7%BE%8E%E7%9C%89&word=%E7%BE%8E%E7%9C%89&pn=60至于怎么简化可以挨个试试,看去掉某一部分还是原来的网页不,其实不简化完全可以,这里只是为了方面大家观看
这个时候你会发现就一个地方不一样,一个是30 一个是 60
pn这个变量引起的不同,这时候就要发挥你的想象,或者长期的经验告诉你,pn就是page nummber的简称(我也是猜的,不过应该不会错)。然后你可以再下滑一下,找找acjson,你会发现 30 60 90 120这些很有规律的数字
那不就是每次给你显示图片的个数么。一次给你30个url
4.然后可以开始写代码了
其他文件和上篇博客一模一样,我这里就展示一下spider这个文件
# coding=utf-8
import scrapy
import json
from baiduImage.items import BaiduimageItem
class Meinv(scrapy.Spider):
name = 'Meinv'
start_urls = [
'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=美女&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=美女&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn=%d' %i for i in range(0,901,30)
]
def parse(self, response):
imgs = json.loads(response.body)['data']
for img in imgs:
item = BaiduimageItem()
try:
item['image_urls'] = [img['middleURL']]
yield item
except Exception as e:
print e没错,就这么点代码,但是加上你分析的时间,可花了我不少时间。
有两个需要注意的地方
1.url中把你查询的中文输入进去,不要直接copy网页中的url,比如上面的“美女”
2.你或许会问json.loads(response.body)[‘data’]、[img[‘middleURL’]]这两个东西咋来的
答:如果你是不会用python加载json文件,建议你百度一下“如何用python加载json文件”
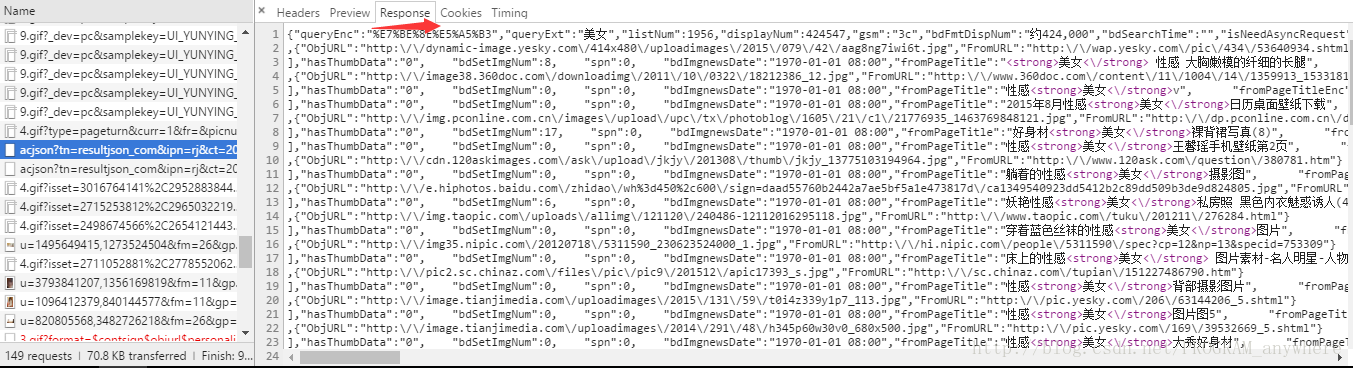
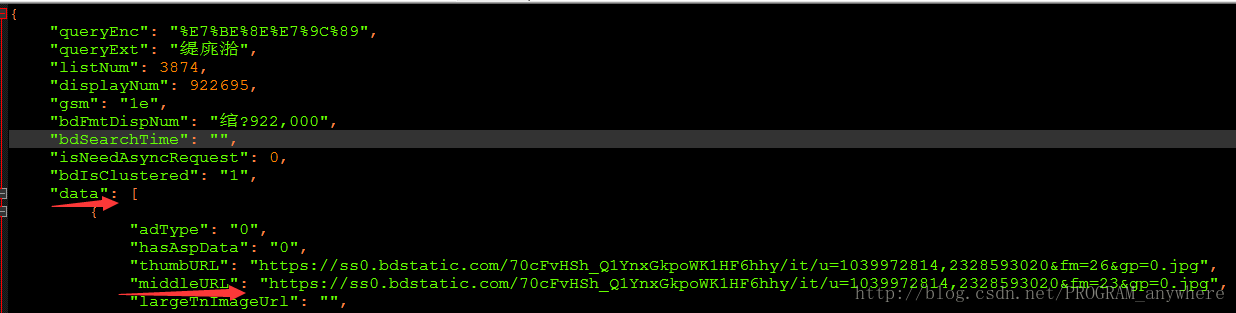
至于‘middleURL’这个东西,你看一眼json文件就行了,建议你下载一个整理json文件的软件,看我下面整理出来的json文件
这下瞬间就明白了吧
OK—-开始装B
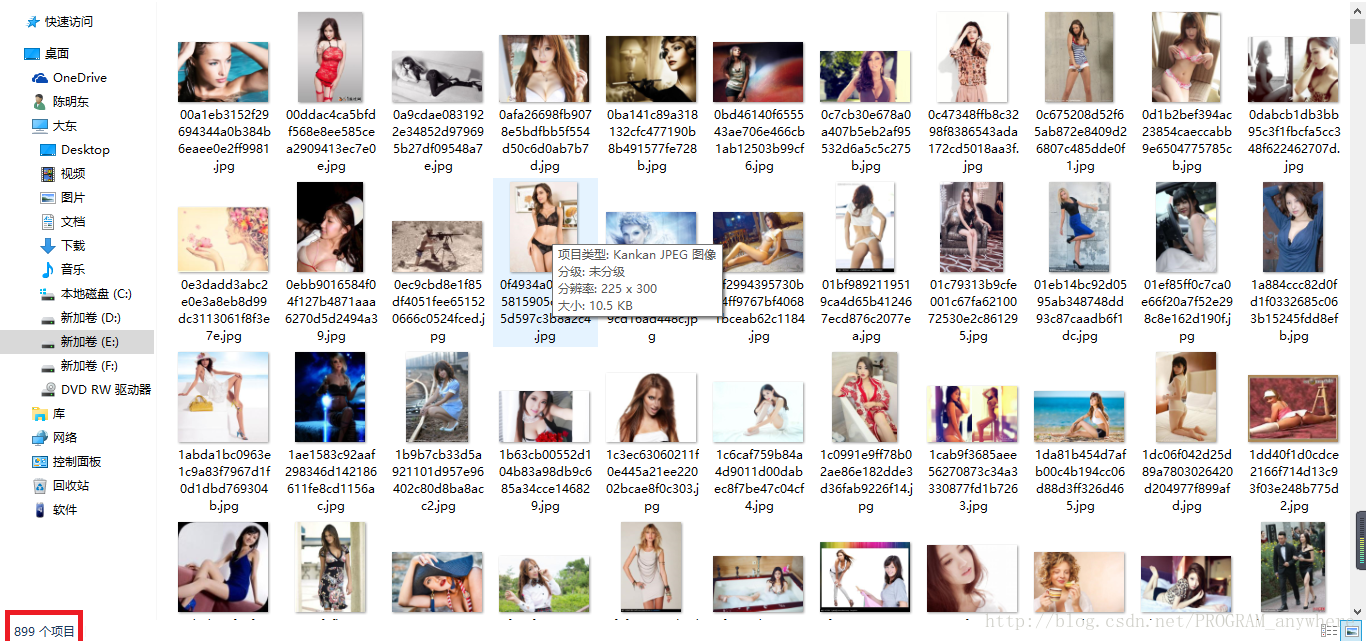
我想爬的是900张图片,实际爬下来899张,那一张为啥没爬下来你可以自己研究一下,对于我来说是够够的啦,O(∩_∩)O哈哈~
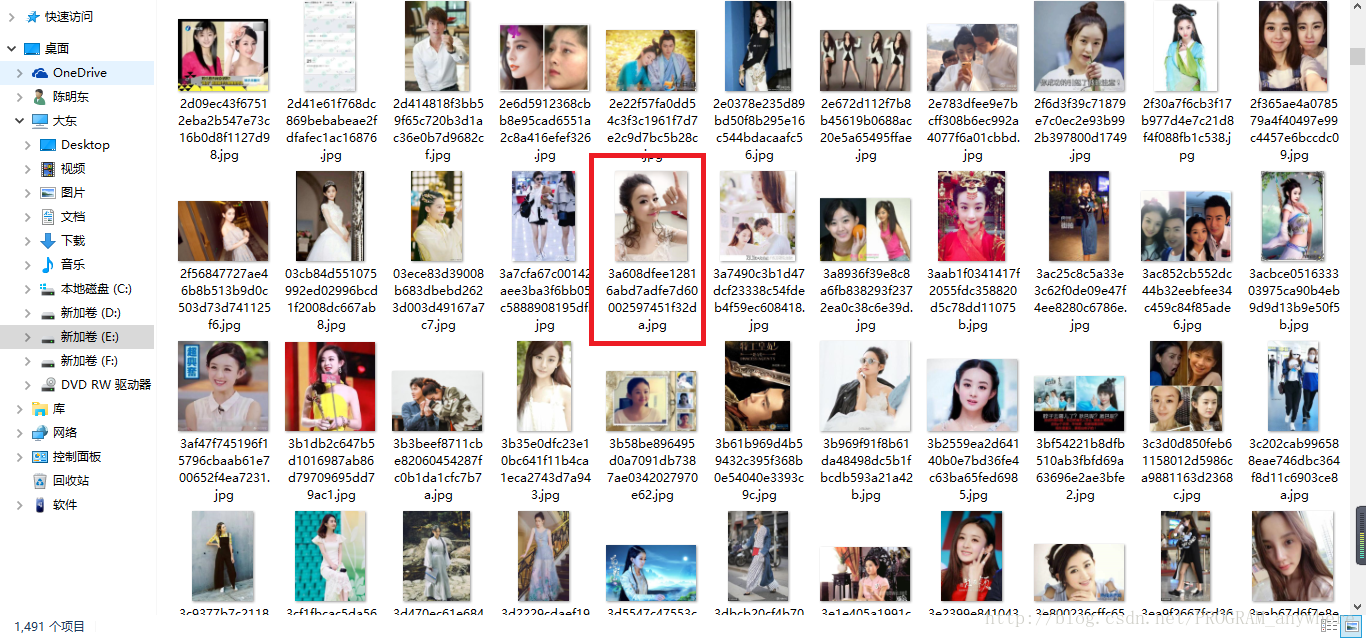
下面再展示一下自己找女神的“赵丽颖”的图片,你只需要改一下url,把“美女”换成“赵丽颖”就好了
美美哒,不过这次我找了1500张图片少了9张图片,也在我能理解的范围,我就没管了。
O(∩_∩)O哈哈~
现在你可以去爬各大网站啦。开始秀出你的技能。注意悠着点
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!