社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,它可以通过添加更多的节点来线性地扩展消息通信的吞吐量。当失去一个RabbitMQ节点时,客户端能够重新连接到集群中的任何其他节点并继续生产或者消费
RabbitMQ集群不能保证消息的万无一失,即使将消息、队列、交换机等都设置为可持久化,生产端和消费端都正确地使用了确认方式,当集群中一个RabbitMQ节点崩溃时,该节点上的所有队列中的消息也会丢失。RabbitMQ集群中的所有节点都会备份所有的元数据信息,包括以下内容:
但是不会备份消息。基于存储空间和性能的考虑,在RabbitMQ集群中创建队列,集群只会在单个节点而不是在所有节点上创建队列的进程并包含完整的队列信息。这样只有队列的宿主节点,即所有者节点知道队列的所有信息,所有其他非所有者节点只知道队列的元数据和指向该队列存在的那个节点的指针。因此当集群节点崩溃时,该节点的队列进程和关联的绑定都会消失。附加在那些队列上的消费者也会丢失其所订阅的信息,并且任何匹配该队列绑定信息的新消息也都会消失
不同于队列那样拥有自己的进程,交换机其实只是一个名称和绑定列表。当消息发布到交换机时,实际上是由所连接的信道将消息上的路由键同交换机的绑定列表进行比较,然后再路由消息。当创建一个新的交换机时,RabbitMQ所要做的就是将绑定列表添加到集群中的所有节点上

1)、启动多个RabbitMQ
docker run -d --hostname rabbit1 --name myrabbit1 -p 15672:15672 -p 5672:5672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-management
docker run -d --hostname rabbit2 --name myrabbit2 -p 5673:5672 --link myrabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-management
docker run -d --hostname rabbit3 --name myrabbit3 -p 5674:5672 --link myrabbit1:rabbit1 --link myrabbit2:rabbit2 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:3.6.15-management
1)多个容器之间用--link连接
2)配置相同的Erlang Cookie
为什幺配置相同的Erlang Cookie?
因为RabbitMQ使用Erlang实现的,Erlang Cookie相当于不同节点之间相互通讯的秘钥,Erlang节点通过交换Erlang Cookie获得认证
Erlang Cookie的位置
首先要获取RabbitMQ启动日志里面的home dir路径,作为根路径。使用”docker logs 容器名称“查看
=INFO REPORT==== 3-May-2019::00:40:56 ===
node : rabbit@rabbit1
home dir : /var/lib/rabbitmq
config file(s) : /etc/rabbitmq/rabbitmq.config
cookie hash : l7FRc4s6MFrXQLBiUlLnOA==
log : tty
sasl log : tty
database dir : /var/lib/rabbitmq/mnesia/rabbit@rabbit1
所以Erlang Cookie的全部路径是“/var/lib/rabbitmq/.erlang.cookie”
root@rabbit1:/# cat /var/lib/rabbitmq/.erlang.cookie
rabbitcookie
复制Erlang Cookie到其他RabbitMQ节点
物理机和容器之间复制命令如下:
设置Erlang Cookie文件权限:“chmod 600 /var/lib/rabbitmq/.erlang.cookie”
2)、加入RabbitMQ节点到集群
rabbitmqctl join_cluster {cluster_node} [–ram]
将节点加入指定集群中。在这个命令执行前需要停止RabbitMQ应用并重置节点
参数--ram表示设置为内存节点,忽略此参数默认为磁盘节点
1)设置节点1
docker exec -it myrabbit1 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
exit
2)设置节点2
docker exec -it myrabbit2 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
3)设置节点3
docker exec -it myrabbit3 bash
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster --ram rabbit@rabbit1
rabbitmqctl start_app
exit
设置好之后访问http://IP:15672/,默认帐号密码是guest/guest
启动了3个节点,1个磁盘节点和2个内存节点

集群的节点类型
RabbitMQ中的每一个节点,不管是单一节点系统或者集群中的一部分,要么是内存节点,要么是磁盘节点。内存节点将所有的队列、交换机、绑定关系、用户、权限和vhost的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。单节点的集群中必然只有磁盘类型的节点,否则当重启RabbitMQ之后,所有关于系统的配置信息都会丢失。不过在集群中,可以选择配置部分节点为内存节点,这样可以获得更高的性能
RabbitMQ只要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点。当节点加入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,而且刚好是它崩溃了,那么集群可以继续发送或者接收消息,但是不能执行创建队列、交换机、绑定关系、用户,以及更改权限、添加或者删除集群节点的操作了。也就是说,如果集群中唯一的磁盘节点崩溃,集群仍然可以保持运行,但是直到将该节点恢复到集群前,无法更改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在
在内存节点重启后,它们会连接到预先配置的磁盘节点,下载当前集群元数据的副本。当在集群中添加内存节点时,确保告知其所有的磁盘节点。只要内存节点可以找到至少一个磁盘节点,那么它就能在重启后重新加入集群中
为了确保集群信息的可靠性,建议全部使用磁盘节点
和SpringBoot整合RabbitMQ主要是配置文件上存在差别:
spring.rabbitmq.addresses=192.168.126.151:5672,192.168.126.151:5673,192.168.126.151:5674
spring.rabbitmq.virtual-host=/
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
RabbitMQ集群addresses使用,隔开
如果RabbitMQ集群是多个Broker节点组成的,那么从服务的整体可用性上来说,该集群对于单点故障时有弹性的,但是同时也需要注意:尽管交换机和绑定关系能够在单点故障问题上幸免于难,但是队列和其上的存储的消息却不行,这是因为队列进程及其内容仅仅维持在单个节点之上,所以一个节点的失效表现为其对应的队列不可用
引入镜像队列的机制,可以将队列镜像到集群中的其他Broker节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。在通常的用法中,针对每一个配置镜像的队列都包含一个主节点(master)和若干个从节点(slave),相应的结构可以参考下图:
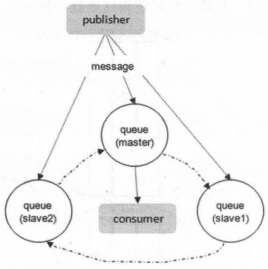
slave会准确地按照master执行命令的顺序进行动作,故slave与master上维护的状态应该是相同的。如果master由于某种原因失效,那么“资历最老”的slave会被提升为新的master。根据slave加入的时间排序,时间最长的slave即为“资历最老”。发送到镜像队列的所有消息会被同时发往master和所有的slave上,如果此时master挂掉了,消息还会在slave上,这样slave提升为master的时候消息也不会丢失。除发送消息(Basic.Publish)外的所有动作都只会向master发送,然后再由master将命令执行的结果广播给各个slave
如果消费者与slave建立连接并进行订阅消费,其实质上都是从master上获取消息,只不过看似是从slave上消费而已。比如消费者与slave建立了TCP连接之后执行一个Basic.Get的操作,那么首先是由slave将Basic.Get请求发往master,再由master准备好数据返回给slave,最后由slave投递给消费者。这里的master和slave是针对队列而言的,而队列可以均匀地散落在集群的各个Broker节点中以达到负载均衡的目的,因为真正的负载还是针对实际的物理机器而言,而不是内存中驻留的队列进程
如下图,集群中的每个Broker节点都包含1个队列的master和2个队列的slave,Q1的负载大多都集中在broker1上,Q2的负载大多都集中在broker2上,Q3的负载大多都集中在broker3上,只要确保队列的master节点均匀散落在集群中的各个Broker节点即可确保很大程度上的负载均衡
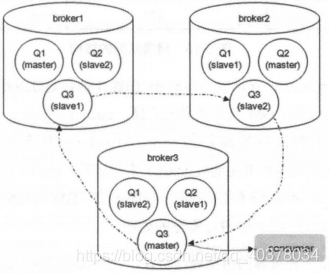
RabbitMQ的镜像队列同时支持publisher confirm和事务两种机制。在事务机制中,只有当前事务在全部镜像中执行之后,客户端才会收到Tx.Commit-Ok的消息。同样的,在publisher confirm机制中,生产者进行当前消息确认的前提是该消息被全部镜像所接收了
镜像队列的结构可以参考下图,master的backing_queue采用的是rabbit_mirror_queue_master,而slave的backing_queue的实现是rabbit_mirror_queue_slave
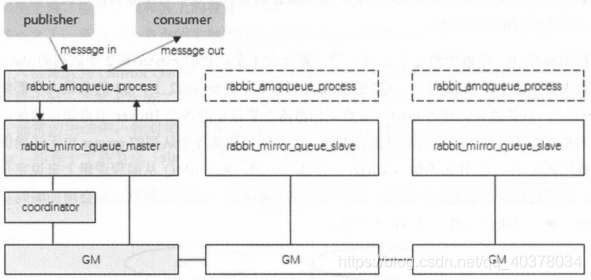
所有对rabbit_mirror_queue_master的操作都会组播GM的方式同步到各个slave中。GM负责消息的广播,rabbit_mirror_queue_slave负责回调处理,而master上的回调处理是由coordinator负责完成的。除了Basic.Publish之外,所有的操作都是通过master来完成的,master对消息进行处理的同时将消息的处理通过GM广播给所有的slave,slave的GM收到消息后,通过回调交由rabbit_mirror_queue_slave进行实际的处理
GM模块实现的是一种可靠的组播通信协议,该协议能够保证组播消息的原子性,既保证组内活着的节点要么都收到消息要么都收不到,它的实现大致为:将所有的节点形成一个循环链表,每个节点都会监控位于自己左右两边的节点,当有节点新增时,相邻的节点保证当前广播的消息会复制到新的节点上;当有节点失效时,相邻的节点会接管以保证本次广播的消息会复制到所有的节点。在master和slave上的这些GM形成一个组,这个组的信息会记录在Mnesia中。不同的镜像队列形成不同的组。操作命令从master对应的GM发出后,顺着链表传送到所有的节点。由于所有节点组成一个循环链表,master对应的GM最终会收到自己发送的操作命令,这个时候master就知道该操作命令都同步到了所有的slave上
整个过程就像在链表中间插入一个节点。注意每当一个节点加入或者重新加入到这个镜像链路中时,之前队列保存的内容将被全部情况

当slave挂掉之后,除了与slave相连的客户端连接全部断开,没有其他影响。当master挂掉之后,会有以下连锁反应:
1)与master连接的客户端连接全部断开
2)选举最老的slave作为新的master,因为最老的slave与旧的master之间的同步状态应该是最好的。如果此时所有slave处于未同步状态,则未同步的消息会丢失
3)新的master重新入队所有unack的消息,因为新的slave无法区分这些unack的消息是否已经达到客户端,或者是ack信息丢失在老的master链路上,再或者是丢失在老的master组播ack消息到所有slave的链路上,所以出于消息可靠性的考虑,重新入队所有unack的消息,不过此时客户端可能会有重复消息
4)如果客户端连接着slave,并且Basic.Consume消费时指定了x-cancel-on-ha-failover参数,那么断开之时客户端会收到一个Consumer Cancellation Notification的通知,消费者客户端中回调Consumer接口的handleCancel方法。如果未指定x-cancel-on-ha-failover参数,那么消费者将无法感知master宕机
镜像队列的配置主要通过添加相应的Policy来完成的,对于镜像队列的配置来说,需要包含3个部分:ha-mode、ha-params和ha-sync-mode
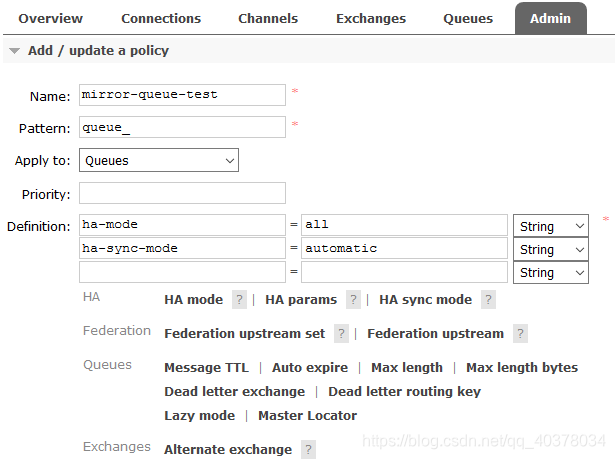
如上图的案例中,对队列名以queue_开头的所有队列进行镜像,并在集群中所有节点上完成镜像,队列的消息的同步方式为automatic
通过队列的属性x-queue-master-locator决定queue master在哪个节点上
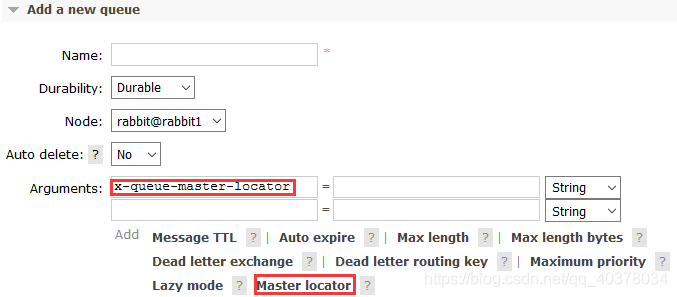
@Bean
public Queue queue() {
Map<String, Object> map = new HashMap<>();
map.put("x-queue-master-locator", "min-masters");
return new Queue(QUEUE, true, false, false, map);
}
将新节点加入已存在的镜像队列时,默认情况下ha-sync-mode取值为manual,镜像队列中的消息不会主动同步到新的slave中,除非显示调用同步命令。当调用同步命令后,队列开始阻塞,无法对其进行其他操作,直到同步完成。当ha-sync-mode设置为automatic时,新加入的slave会默认同步已知的镜像队列。由于同步过程的限制,所以不建议对生产环境中正在使用的队列进行操作
当所有slave都出现未同步状态,并且ha-promote-on-shutdown设置为when-synced时,如果master因为主动原因停掉,那么slave不会接管master,也就是此时镜像队列不可用;但是如果master因为被动原因停掉,那么slave会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,同时放弃了可用性。如果ha-promote-on-shutdown设置为always,那么不论master因为何种原因停止,slave都会接管master,优先保证可用性,不过消息可能会丢失
镜像队列中最后一个停止的节点会是master,启动顺序必须是master先启动。如果slave先启动,它会有30秒的等待时间,等待master的启动,然后加入到集群中。如果30秒内master没有启动,slave会自动停止。当所有节点因故同时离线时,每个节点都认为自己不是最后一个停止的节点,要恢复镜像队列,可以尝试在30秒内启动所有节点
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
