社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
上一篇是一个
python3爬虫系列22之selenium模拟登录需要验证码的微博且抓取数据,
我们是首先进入到验证码网页读取验证码,人来手动识别输入,然后再提交。
比较麻烦。
翻看博客发现,之前有些过关于调用OCR的:
python3调用腾讯API(图像/文字/验证码/名片/驾驶证)识别,
网上一大堆python爬虫验证码识别,都是基于用tesserocr库,用pytesseract了,精度也太低了。
现在就借用一下 【腾讯ocr的API来实现验证码的识别,然后完成咱们的微博全自动化登录。】
看了这篇以后,不要在用用tesserocr库了,不要在用pytesseract了,精度也太低了。
比如在爬虫时遇到页面显示验证码验证环节,需要先截取到验证码,再识别、输入验证码,完成识别过程。(定位到验证码处,截图保存)
1.利用python的selenimu模块启动一个浏览器打开需要登陆网站的登陆页面,通过对网页源码中元素的查找用户名、密码输入框,识别码区域,以selenimu模块send.keys方法向浏览器传送用户名、密码。
2.通过对包含有识别码的区域利用selenimu模块的save_screenshot方法将识别码区域进行截图保存至电脑本地。
3.利用百度/腾讯等第三方中的OCR文字识别功能对2条中的包含有识别码的图片进行识别,返回识别结果,再用selenimu模块send.keys方法将识别结果填充到验证码的输入框中。
4.利用selenimu模块click()方法对登陆按纽进行点击,最终实现全自动登陆。
从网站获取验证码
直接从网站获取验证码必须用到get,然后截取验证码以后,又要采用再次get来写入到本地。这时候,验证码会变。不管你是保存到本地,还是将其转换为Image对象,都会变。
所以我直接采用定位工具:page ruler
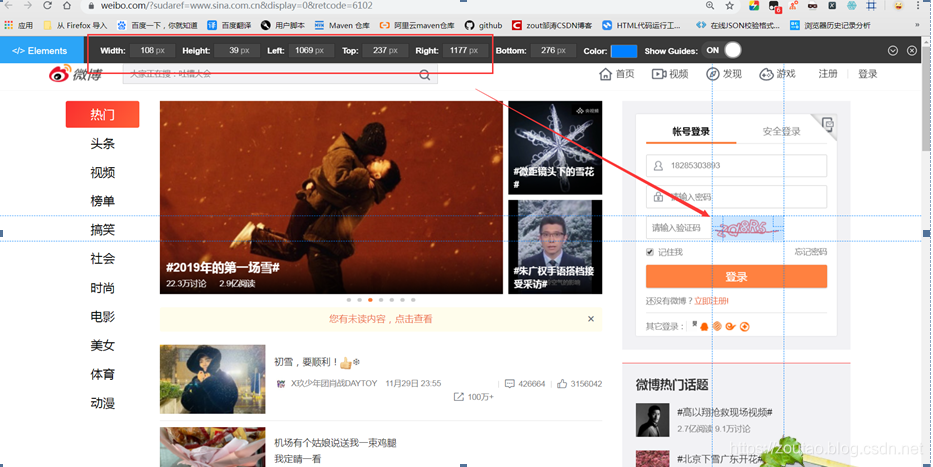
效果图: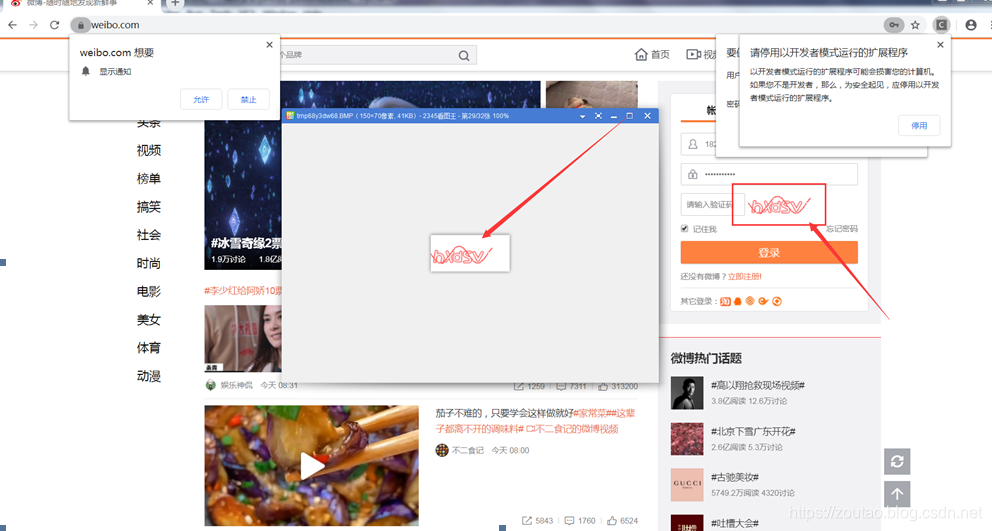
对保存的验证码进行文字识别,并返回结果存于text字典中。

代码:
在python3调用腾讯API(图像/文字/验证码/名片/驾驶证)识别,中的第二个方法。
识别完成以后,如果验证码识别出错,然后就递归刷新再次去识别,直到成功。
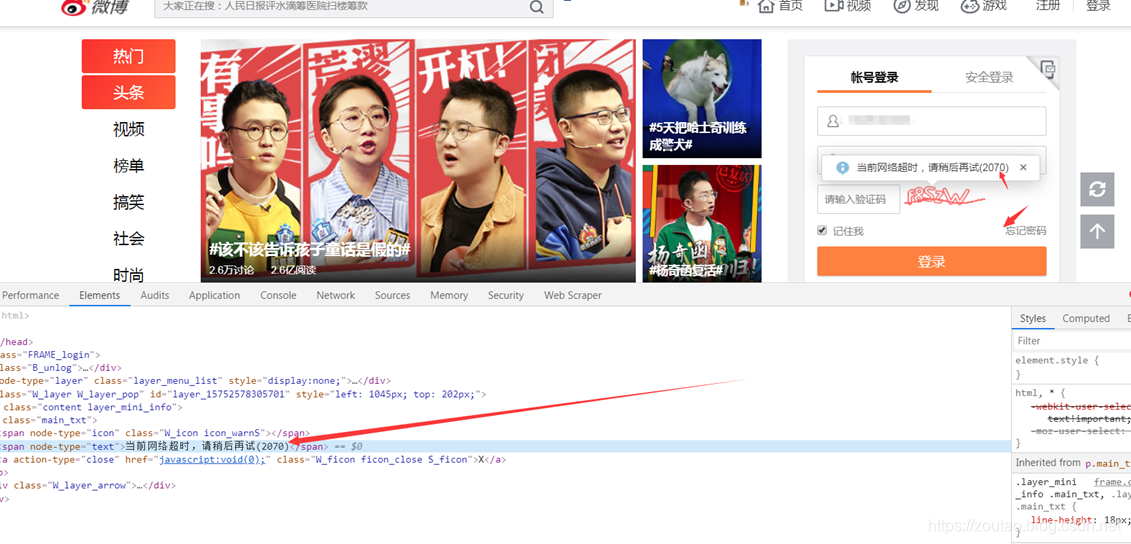
完整代码如下:
#!/usr/bin/python3
# 自动验证码法
import time
from PIL import Image
from selenium import webdriver
import base64, hashlib, json, random, string, time
import requests
from urllib import parse, request
# 3.获取鉴权签名
def GetAccessToken(formdata, app_key):
'''
获取鉴权签名
:param formdata:请求参数键值对
:param app_key:应用秘钥
:return:返回接口调用签名
'''
dic = sorted(formdata.items(), key=lambda d: d[0])
sign = parse.urlencode(dic) + '&app_key=' + app_key
m = hashlib.md5()
m.update(sign.encode('utf8'))
jiami =m.hexdigest().upper()
#print(jiami)
return m.hexdigest().upper()
# 4.改成你自己的app_id、,app_key-可用改为全局变量
app_id = 'xxxxxxx'
app_key = 'xxxxxxxxxxxxxxxxxx'
# 5.腾讯OCR识别通用接口
def RecogniseGeneral(app_id, time_stamp, nonce_str, image, app_key):
'''
腾讯OCR通用接口
:param app_id:应用标识,正整数
:param time_stamp:请求时间戳(单位秒),正整数
:param nonce_str: 随机字符串,非空且长度上限32字节
:param image:原始图片的base64编码
:return:
'''
host = 'https://api.ai.qq.com/fcgi-bin/ocr/ocr_generalocr'
formdata = {'app_id': app_id, 'time_stamp': time_stamp, 'nonce_str': nonce_str, 'image': image}
app_key = app_key
sign = GetAccessToken(formdata=formdata, app_key=app_key) # 获取腾讯鉴权签名
formdata['sign'] = sign
req = request.Request(method='POST', url=host, data=parse.urlencode(formdata).encode('utf8'))
response = request.urlopen(req)
if (response.status == 200):
json_str = response.read().decode()
#print('腾讯OCR通用接口返回结果:',json_str)
jobj = json.loads(json_str)
datas = jobj['data']['item_list']
recognise = {}
for obj in datas:
recognise[obj['itemstring']] = obj
return recognise
# 2.图片base64编码
def Recognise(img_path):
with open(file=img_path, mode='rb') as file:
base64_data = base64.b64encode(file.read())
nonce = ''.join(random.sample(string.digits + string.ascii_letters, 32))
stamp = int(time.time())
# 调用腾讯OCR通用接口
recognise = RecogniseGeneral(app_id=app_id, time_stamp=stamp, nonce_str=nonce, image=base64_data,
app_key=app_key)
return recognise
# 1.调用腾讯OCR验证码识别
def tengxunOCR():
img_path = 'yzm.png'
recognise_dic = Recognise(img_path)
yzm = ''
for k, value in recognise_dic.items():
print('图片识别内容:', k)
yzm=k
return yzm
# 对目标网页进行截全屏
def get_snap(driver):
driver.save_screenshot('full_snap.png')
page_snap_obj = Image.open('full_snap.png')
return page_snap_obj
# 对验证码所在位置进行定位(自动/手动),然后截取验证码的位置图
def get_image(driver):
img = driver.find_element_by_xpath('//img[@node-type="verifycode_image"]')# 不取src地址。
# image_url = img.get_attribute('src')
time.sleep(2)
location = img.location
size = img.size
#print(location,size)
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
page_snap_obj = get_snap(driver) # 截全屏
#print(left, top, right, bottom,size['width'],size['height'])
# 开始自动定位/手动定位验证码的位置。代表(左,上,右,下)
#image_obj = page_snap_obj.crop((left, top, right, bottom))
image_obj = page_snap_obj.crop((1430, 290, 1545, 330))
#image_obj.show() # 查看截取图片
image_obj.save("yzm.png")
return image_obj # 得到验证码
# 刷新验证码重新识别
def repeat(driver,normal_window):
print('刷新验证码重新识别')
# driver.find_element_by_class_name('W_input').click() # 如果需要输入验证码
# time.sleep(3)
image1 = get_image(driver) # 对验证码所在位置进行定位且截图保存
print('图片验证码截取完成。')
yzm = tengxunOCR() # 调用文字验证码识别
print('图片验证码识别完成。')
driver.find_element_by_name('verifycode').send_keys(yzm) # 填入验证码框
time.sleep(5)
driver.find_element_by_css_selector(".info_list.login_btn a[node-type='submitBtn']").click() # 登录按钮
print('再次点击登录。')
time.sleep(3)
logincheck(driver,normal_window) # 登录成功否检查
# 登录成功否检查
def logincheck(driver,normal_window):
print('登录状态检查')
time.sleep(5)
if "我的首页 微博-随时随地发现新鲜事" in driver.title:
print('成功登录微博')
#####获取所有页面句柄
all_Handles = driver.window_handles
#####如果新的pay_window句柄不是当前句柄,用switch_to_window方法切换
for pay_window in all_Handles:
if pay_window != normal_window:
driver.switch_to.window(pay_window)
print('========================跳转页面============================')
# 获取跳转后页面的源码
time.sleep(10)
source = driver.page_source.encode("gbk", "ignore").decode("gbk")
# print(source)
# 接下来可以找自己需要的内容。
# //*[@id="v6_pl_content_homefeed"]/div/div[4]/div[1]/div[2]/div[4]/div[1]/a
username = driver.find_element_by_xpath('//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/div/a[1]')
print('用户名:', username.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[1]/a/strong
guanzhu = driver.find_element_by_xpath(
'//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[1]/a/strong')
print('关注数:', guanzhu.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[2]/a/strong
fensi = driver.find_element_by_xpath(
'//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[2]/a/strong')
print('粉丝数:', fensi.text)
# //*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[3]/a/strong
shumu = driver.find_element_by_xpath(
'//*[@id="v6_pl_rightmod_myinfo"]/div/div/div[2]/ul/li[3]/a/strong')
print('微博数:', shumu.text)
else:
print('登录失败,刷新验证码重试。')
repeat(driver, normal_window) # 重复提交
# 自动化登录
def start(url,username,password):
options = webdriver.ChromeOptions()
# 设置为开发者模式,防止被网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=options) # 或填入chromedriver.exe的绝对路径
driver.set_page_load_timeout(10) # 设置模拟浏览器最长等待时间
driver.maximize_window() # 最大化窗口
print('准备登陆')
normal_window = driver.get(url) # 给当前请求窗口命名
time.sleep(5)
driver.find_element_by_id('loginname').send_keys(username)
driver.find_element_by_name('password').send_keys(password)
driver.find_element_by_class_name('W_input').click() # 如果需要输入验证码
time.sleep(5) # 加延迟,为了加载元素,避免太快出现异常
image1 = get_image(driver) # 对验证码所在位置进行定位且截图保存
print('图片验证码截取完成。')
yzm = tengxunOCR() # 调用文字OCR识别验证码
print('图片验证码识别完成。')
driver.find_element_by_name('verifycode').send_keys(yzm) # 填入验证码框
time.sleep(5)
driver.find_element_by_css_selector(".info_list.login_btn a[node-type='submitBtn']").click() # 登录按钮
print('点击登录。')
time.sleep(8)
logincheck(driver,normal_window) # 登录成功否检查
# driver.close()
# driver.quit()
if __name__ == '__main__':
url = 'https://weibo.com/'
username='xxxxx' # 微博号
password='xxxxxxx' # 微博密码
start(url,username,password)
最终效果:
自动截取验证码,自动送到OCR去识别,自动读取结果,自动填入验证码框,然后自动点击登录,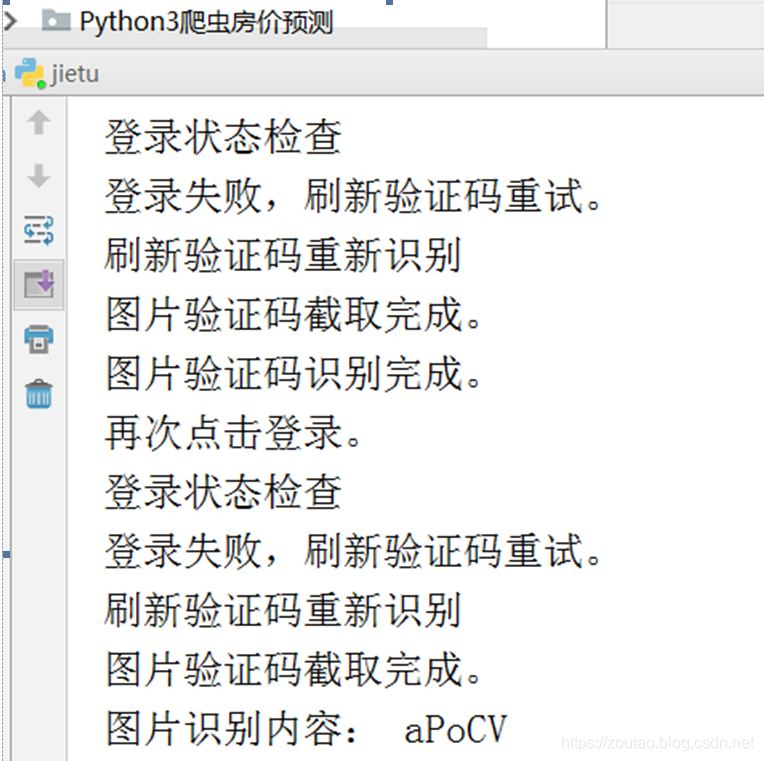
一旦验证码识别成功了,就登录成功。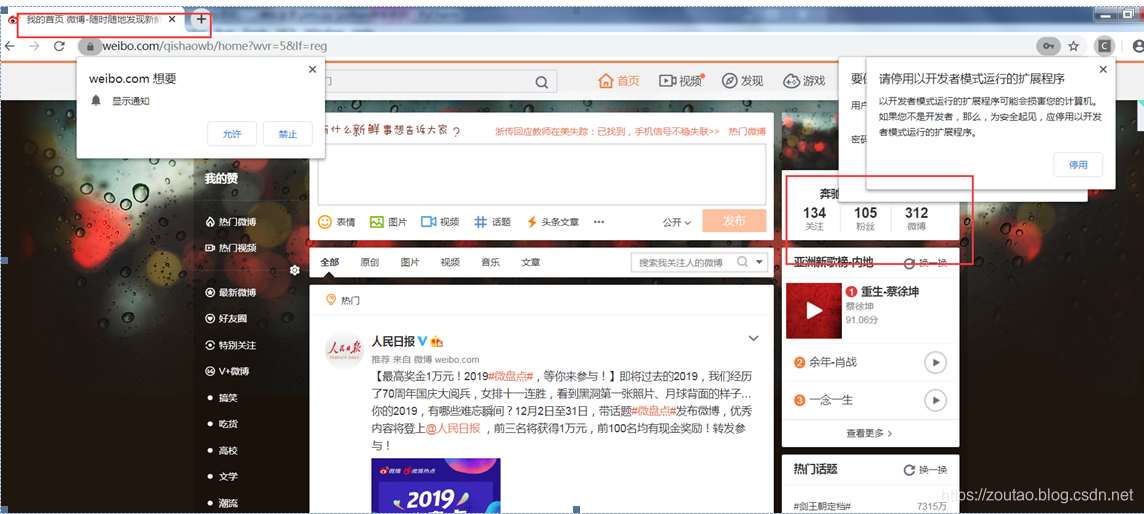
最后就可以随便抓你要的数据了。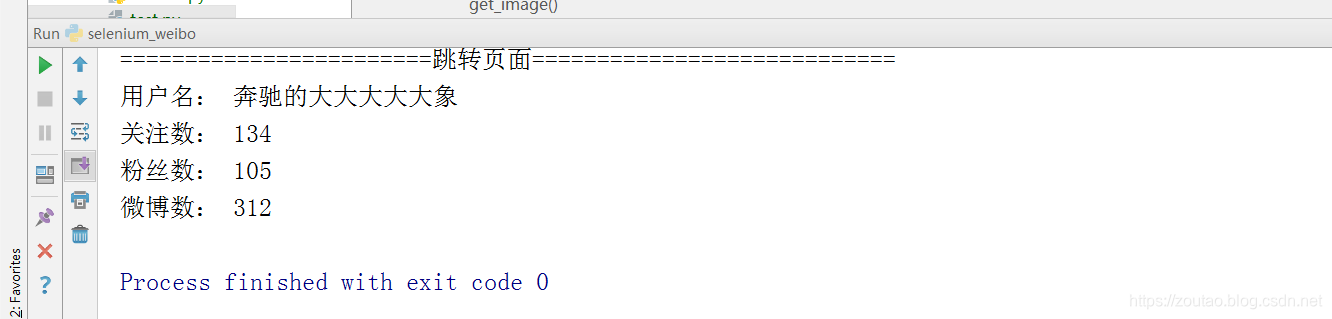
从总体效果来看,腾讯的OCR要比百度的OCR识别效率更好,更好一些,
百度真是越来越走远了。谷歌的tesseract-ocr4.0就更不说了,开源的,自己拿去训练吧。。。
当然如果你有很多时间,可以用深度学习来训练的方法比较好,比如SVM。首先对验证码做一个简单的处理,二值化,去噪,切割,手动分类,然后去标记。用机器学习去训练,识别率挺高的。
太难了?下一篇从另外的角度来搞微博。
参考地址:
https://blog.csdn.net/xiongzaiabc/article/details/83094774
https://blog.csdn.net/weixin_41792971/article/details/88142828
https://blog.csdn.net/weixin_38374974/article/details/80152899
https://jingyan.baidu.com/article/5d368d1e2def6c7f60c05789.html
图像识别验证码:
http://my.cnki.net/elibregister/commonRegister.aspx#
http://www.zol.com.cn/
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
