社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
声明:本文内容主要来源于中国大学MOOC嵩天老师的课程Python语言程序设计
计算机是根据指令操作数据的设备
计算机的发展 参照摩尔定律,表现为指数方式
摩尔定律 计算机发展历史上最重要的预测法则

程序设计 计算机可编程性的体现
程序设计语言 一种用于人类与计算机之间交互的人造语言,亦称编程语言,比自然语言更简单、更严谨、更精确
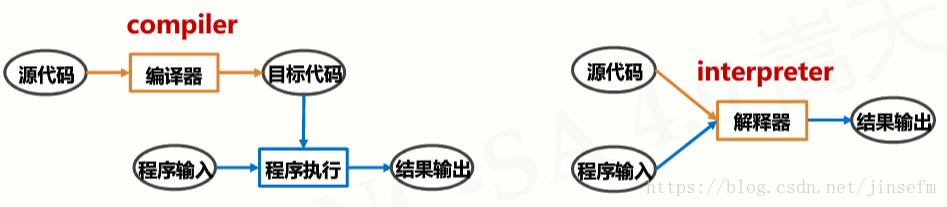
编程语言的执行方式 编译和解释
result = 1+111010010 00111011编译 将源代码一次性转换成目标代码的过程,执行编译过程的程序叫作编译器
解释 将源代码逐条转换成目标代码同时逐条运行的过程,执行解释过程的程序叫作解释器
编译: 一次性翻译,之后不再需要源代码,类似英文翻译
解释:每次程序运行时随翻译随执行,类似实时同声传译
静态语言
动态语言
程序的基本编写方法 IPO
Python语言诞生 创立者 Guido van Rossum
| and | elif | if | or | with |
|---|---|---|---|---|
| as | else | import | pass | yield |
| assert | except | in | raise | del |
| break | finally | lambda | return | False |
| class | for | not | try | |
| continue | from | nonlocal | True | |
| def | global | None | while |
round()函数四舍五入处理<a>e<b>表示c.real获得,虚部用c.imag获得abs(x) x的绝对值 divmod(x,y) 商余,如divmod(10,3) 结果为(3,1)pow(x,y[,z]) 幂余, 表示(x**y)%zround(x,y) 四舍五入max(x1,x2,...,xn) 返回最大值min(x1,x2,...,xn) 返回最小值int(x) 将x变为整数,舍弃小数部分,如 int(123.45) int("123")float(x) 将x变为浮点数,增加小数部分x+y 连接两个字符串n*x 或 x*n 复制n次字符串xx in s 如果x是s的子串,返回True,否则返回Falselen(x) 返回字符串x的长度str(x) 与eval(x) 相反,将x加上引号变为字符串hex(x) 或 oct(x) 整数x的十六进制或八进制chr(u) 或 ord(x) Unicode与单字符的互相转换ch(9800) ~chr(9812) =>♈♉♊♋♌♍♎♏♐♑♒♓str.lower(),str.upper() 返回字符串的副本,全部字符小写/大写str.split(seq=None) 返回一个列表,由str根据sep被分隔的部分组成str.count(sub) 返回子串sub在str中出现的次数str.replace(old,new) 返回字符串副本,所有old子串被替换成newstr.center(width[,fillchar])字符串str根据宽度width居中,fillchar可选"python".center(20,"=") 结果为 '======python======='str.strip(chars) 从str中去掉在其左侧和右侧chars中列出的字符"= python =".strip(" =np") 结果为 "ytho"str.join(iter) 在iter变量除最后元素外每个元素后增加一个str,主要用于字符串分隔",".join("12345") 结果为"1,2,3,4,5"str1.index(str2[,begin[,end]]) 从字符串str1的begin到end位置时搜索到字符串str2时返回在str1的索引。str2 = "exam"
print (str1.index(str2))
print (str1.index(str2, 10))
print (str1.index(str2, 40))
结果为
15
15
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
print(str1.index(str2, 16))
ValueError: substring not found
用法:<模板>.format(<逗号分隔的参数>)
注意槽的变化
"{}:计算机{}的CPU占用率为{}%".format("2018-10-10","C",10)
0 1 2 0 1 2
结果为:"2018-10-10:计算机C的CPU占用率为10%"
"{1}:计算机{0}的CPU占用率为{2}%".format("2018-10-10","C",10)
结果为:"C:计算机2018-10-10的CPU占用率为10%"
槽内部对格式化的配置方式
{<参数序号>:<格式控制标记>}
| : | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 | <为左对齐 >为右对齐 ^居中对齐 | 槽设定的输出宽度 | 数字的千位分隔符 | 浮点数小数精度或字符串最大输出长度 | 整数类型b,c,d,o,x,X浮点数类型e,E,f,% |
"对" if guess==99 else "错"异常处理一
try:
<语句块1>
except <异常类型,可针对响应>:
<语句块2>
异常处理二,直接抛出
raise <异常名称>
三、异常发生,finally中语句正常执行
try:
<语句块1>
(except (<异常类型,可针对响应>):
<语句块>)
finally:
<语句块2>
四、异常不发生时会执行else中语句
try:
<语句块1>
except <异常类型>:
<语句块2>
else:
<语句块3>
finally:
<语句块4>
五、自定义异常
自定义一个MyException类,继承Exception。
class MyException(Exception):
def __init__(self,message):
Exception.__init__(self)
self.message=message
如果输入的数字小于10,就引发一个MyException异常:
a=input("please input a num:")
if a<10:
try:
raise MyException("my excepition is raised ")
except MyException,e:
print e.message
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| SystemExit | Python 解释器请求退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
- for … in 遍历循环:计数、字符串、列表、文件
for <变量> in <遍历结构>:
<语句块1>
else:
<语句块2>
--------------------------
while <条件>:
<语句块1>
else:
<语句块2>
函数定义
def <函数名>(<参数(0个或多个)>):
<函数体>
return <返回值>
函数调用
def fact(n,m=1):
s=1
for i in range(1,n+1):
s *=i
return s//m
>>>fact(10)
3628800
>>>fact(10,5)
725760
def fact(n,*b):
s=1
for i in range(1,n+1):
s*=i
for item in b:
s*=item
return s
>>>fact(10,3)
10886400
>>>fact(10,3,5,8)
435456000
局部变量和全局变量
global保留字在函数内部使用全局变量ls =['F','f'] #全局变量列表ls
def func(a):
ls.append(a) #此处ls是列表类型,未真实创建,等同于全局变量
return
func('C')
print(ls)
>>>
['F','f','C']
1.集合定义
2.集合表示
>>> A={"python",123,('python',123)}
>>> A
{123, 'python', ('python', 123)}
>>> B=set("pypy1233")
>>> B
{'3', 'y', '1', '2', 'p'}
>>> C={"python",123,"python",123}
>>> C
{123, 'python'}
3.集合间操作
S|T 并集 包括在集合S和T中的所有元素S-T差集 包括在S但不在T中的元素S&T交集 包括同时在S和T中的元素S^T补集 包括S和T的非相同元素S<=T 或 S<T 返回True/False,判断S和T的子集关系S>=T 或 S>T 返回True/False,判断S和T的包含关系
S|=T S&=T S^=T S-=T>>> A={'p','y',123}
>>> B=set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A^B
{'3', '1', 123, '2'}
>>> A|B
{'3', 'y', '1', '2', 'p', 123}
4.集合处理方法
S.add(x) 如果x不在集合S中,将x增加到SS.discard(x) 移除S中元素x,如果x不在集合S中,不报错S.remove(x) 移除S中元素x,如果x不在集合S中,产生KeyError异常S.clear()移除S中所有元素S.pop() 随机取出S的一个元素,更新S,若S为空产生KeyError异常S.copy()返回S的一个副本len(S)返回集合S的元素个数x in S 与 x not in判断S中元素x是否存在,返回True/Falseset(x)将其他类型变量x转变为集合类型
try:
while True:
print(A.pop(),end="")
except:
pass
p123y
>>>A
set()
#此方法等价于for...in
5.集合类型应用场景
>>> A
set()
>>> "p" in {'p','y',123}
True
>>> {'p','y'} >={'y',123}
False
>>> ls=['p','p','y',231,'y']
>>> s=set(ls)
>>> s
{231, 'p', 'y'}
>>> lt=list(s)
>>> lt
[231, 'p', 'y']
1.序列类型定义
序列是一个基类类型
包含字符串类型/元组类型/列表类型
2.序列处理函数及方法
序列类型通用操作符x in s和 x not in s 判断x是否为s序列的元素s+t 连接两个序列s和ts*n 或 n*s 将序列复制n次s[i]索引,返回s中第i个元素s[i:j]或s[i:j:k]切片,返回序列s中第i到j以k为步长的元素子序列
序列类型通用函数和方法len(s) 返回序列s的长度min(s)或max(s)返回序列s的最小或最大值,s中元素需可比较s.index(x)或s.index(X,i,j)返回序列s从i开始到j位置中第一次出现元素X的位置s.count(x)返回序列中出现x的总次数
3.元组类型及操作
元组是序列类型的一种扩展
tuple()创建,元素间用逗号,分隔def func():
return 1,2
>>> creature='cat','dog','tiger','human'
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color=(0x001100,'blue',creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
>>> color[-1][2]
'tiger'
4.列表类型定义
>>> ls=['cat','dog','tiger',1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> lt=ls
>>> lt
['cat', 'dog', 'tiger', 1024]#方括号[]真正创建一个列表,赋值仅传递引用
ls[i]=x替换列表ls第i元素为xls[i:j:k]=lt用列表lt替换切片后所对应元素子列表del ls[i]删除列表ls中第i元素del ls[i:j:k]删除列表ls中第i到j以k为步长的元素ls +=lt更新列表ls,将列表lt元素增加到列表ls中ls *=n更新列表ls,其元素重复n次
>>> ls=['cat','dog','tiger',1024]
>>> ls[1:2]=[1,2,3,4]
>>> ls
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
>>> ls
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
ls.append(x)在列表ls最后增加一个元素ls.clear()删除列表ls中所有元素ls.copy()生成一个新列表,赋值ls中所有元素ls.insert(i,x)在列表ls的第i位置增加元素xls.pop(i)将列表元素ls中的第i位置元素取出并删除元素ls.remove(x)将列表ls中出现的第一个元素x删除ls.reverse()将列表ls中的元素反转
5.序列类型应用场景
lt=tuple(ls)1.字典类型定义
dict()创建,键值对用冒号:表示"streetAddr":"中关村南大街1号""City":"北京市"{<键1>:<值1>,<键2>:<值2>,...}2.字典类型的用法
type(x)返回变量x的类型>>> d={"中国":"北京","美国":"华盛顿","法国":"巴黎"}
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
>>> d['中国']
'北京'
>>> de={}
>>> de
{}
>>> type(de)
<class 'dict'>
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎', '日本': '东京'}
3.字典处理函数及方法
del d[k] 删除字典d中键k对应的数据k in d 判断键k是否在字典d中,如果在返回True,否则Falsed.keys() 返回字典d中所有的键信息d.values()返回字典d 中所有的值信息d.items()返回字典d中所有键值对信息>>> '中国' in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国', '日本'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎', '东京'])
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/jinsefm/article/details/80768187
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!