社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
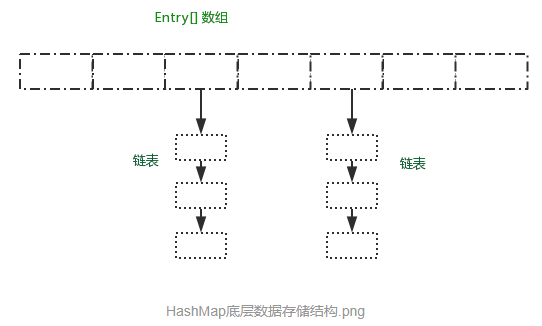
hashmap实现原理
简单一句话数组链表结构存储,这里Entry[]是map中的静态类,entry[]数组默认长度为16,每个数组上跟着一个链表,
链表什么时候出现呢?就是在hashcode相同时出现,当put时候会生成一个hashcode便于存储位置,但是不避免hashcode相同的情况这个时候就存在链表中(但是链表中虽然hashcode相同但是对象在jvm地址中可是不同的,可以用eques去判断)
当entry[]的大小超过负载因子0.75的时候开始扩容到自身的2倍(这是最大扩容)
在jdk1.8中当entry[]大于8个时,后面的数组将进行红黑树数据接口存储,大大提高了效率。
hashmap扩容原理
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
