社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
容器数据类型collections
源代码: Lib / collections /__init__.py
这个模块实现专门的容器数据类型提供替代Python的通用内置容器中,dict,list, set,和tuple。
namedtuple() 用于创建具有命名字段的元组子类的工厂函数
deque 列表式容器在任意一端具有快速追加和弹出
ChainMap 类似类的类,用于创建单个视图的多个映射
Counter dict子类用于计算可哈希对象
OrderedDict dict子类记住添加的订单条目
defaultdict dict子类调用工厂函数来提供缺失值
UserDict 围绕词典对象进行包装,以便于简单的dict子类化
UserList 围绕列表对象进行包装以便于列表子类化
UserString 包装字符串对象以便于字符串子类化
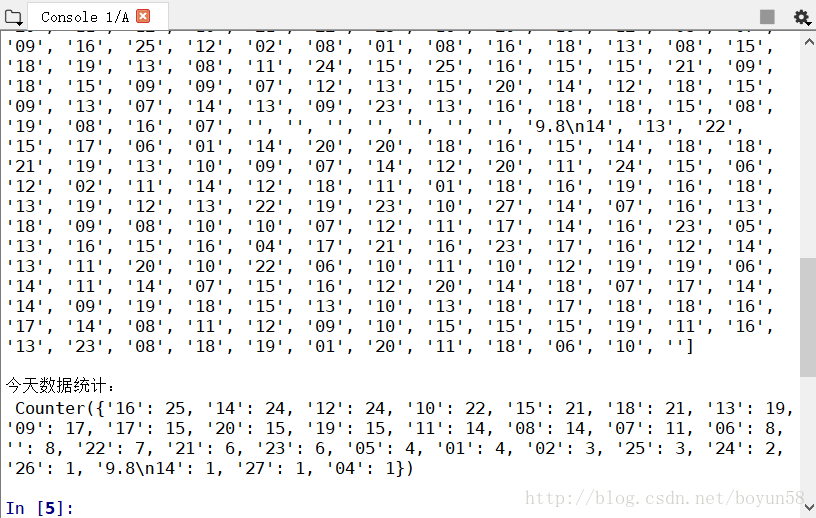
在版本3.3中更改:将集合抽象基类转换为模块。为了向后兼容,它们在该模块中继续可见。collections.abc最近有一位朋友想对一个软件开出的1-27号码就行数据频率统计,但数据过于庞大人工无法实现,苦恼之中求助于我。只用了几行代码就轻松实现了他的需求
创建一个文本,并对其中数字出现的次数进行统计,返回某个数字出现的频率键值对
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 9 22:28:38 2017
@author: Allen_by
"""
import collections
import os
with open(r'./data.txt') as f:
Str=f.read().split(' ')
print("old_data:n%s" % Str)
print("n今天数据统计:n %s" % collections.Counter(str1))如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!