社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
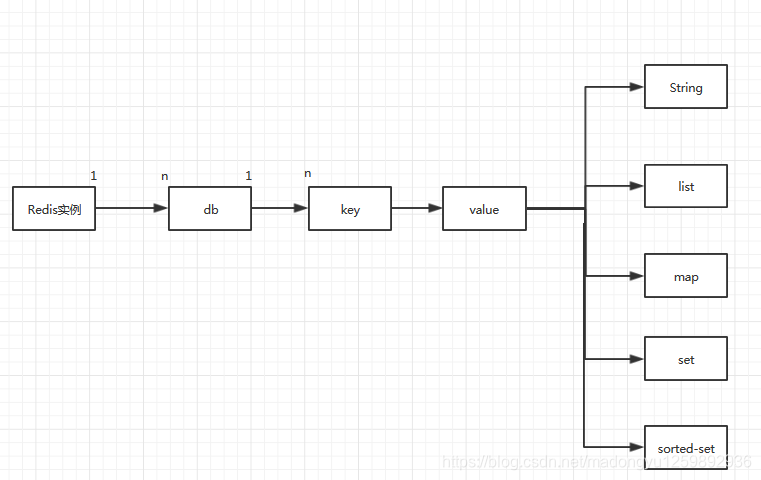
缓存大致可以分为两类,一种是应用内缓存,比如Map(简单的数据结构),以及EH Cache(Java第三方库),另一种就是缓存组件,比如Memached,Redis;Redis是一个基于KEY-VALUE的高性能的存储系统,通过提供多种键值数据类型来适应不同场景下的缓存与存储需求
redis的全称是remote dictionary server(远程字典服务器),它以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容,结构如下图所示:
redis的安装
1.下载redis安装包
2.tar -zxvf 安装包
3.在redis目录下 执行 make
4.可以通过make test测试编译状态
5.make install [prefix=/path]完成安装
注意:
1.需要安装tcl yum install tcl、yum install gcc
2. error: jemalloc/jemalloc.h: No such file or directory说关于分配器allocator,如果有MALLOC这个环境变量,会有用这个环境量的去建立Redis。而且libc并不是默认的分配器,默认的是jemalloc,因为jemalloc被证明有更少的fragmentationproblems比libc。但是如果你又没有jemalloc而只有libc当然make出错。所以加这么一个参数。解决办法make MALLOC=libc
启动停止redis
./redis-server ../redis.conf
./redis-cli shutdown
以后台进程的方式启动,修改redis.conf daemonize =yes
连接到redis的命令 ./redis-cli -h 127.0.0.1 -p 6379
其他命令说明
Redis-server 启动服务
Redis-cli 访问到redis的控制台
redis-benchmark 性能测试的工具
redis-check-aof aof文件进行检测的工具
redis-check-dump rdb文件检查工具
redis-sentinel sentinel 服务器配置
多数据的支持
默认支持16个数据库;可以理解为一个命名空间
跟关系型数据库不一样的点
通过 select dbid 去选择不同的数据库命名空间 。 dbid的取值范围默认是0 -15
字符串类型
字符串类型是redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。你可以用它存储用户的邮箱、json化的对象甚至是图片。一个字符类型键允许存储的最大容量是512M
内部数据结构
在redis内部,String类型通过int ,SDS作为结构储存,int用来存放整型数据,sds存放字节/字符串和浮点型数据。在C的标准字符串结构下进行了封装,用来提升基本的操作的性能,同时也充分利用已有的C的标准库,简化实现逻辑。我们可以在redis的源码【sds.h】中看到sds的结构如下:
typedef char * sds
redis3.2分支引入了五种sdshdr类型,目的是为了满足不同字符串可以使用不同大小的Header,从而节省内存,每次在创建一个sds时根据sds的实际长度判断应该选择什么类型的sdshdr,不同类型的sdshdr占用的内存空间不同。这样细分一下可以省去很多不必要的内存开销,下面是3.2的sdshdr定义
`struct __attribute__ ((__packed__)) sdshdr8 { 8表示字符串最大长度是2^8-1 (长度为255)``
uint8_t len;//表示当前sds的长度(单位是字节)`` uint8_t alloc; //表示已为sds分配的内存大小(单
位是字节)`` unsigned char flags; //用一个字节表示当前sdshdr的类型,因为有sdshdr有五种类型,所
以至少需要3位来表示000:sdshdr5,001:sdshdr8,010:sdshdr16,011:sdshdr32,100:sdshdr64。高5位
用不到所以都为0。`` char buf[];//sds实际存放的位置``};`
sdshdr8的内存布局

列表类型
列表类型list,可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素获得列表的某一个片段,列表类型内部使用双向链表实现,所以向列表两端加元素的时间复杂度为o(1),获取越接近两端的元素速度就快,这意味着即使是一个有几千万个元素的列表,获取头部或者尾部的100条记录也是很快的。

内部数据结构
redis3.2之前,list类型的value对象内部以linkedlist来实现,当list的元素个数和单个元素的长度比较小的时候,redi会采用ziplist(压缩列表)来实现减少内存占用,否则就会采用linkedlist(双向链表)结构
redis3.2之后,采用的一种叫quicklist的数据结构来存储list,列表的底层都是由quicklist来实现的。
这两种存储方式都有优缺点,双向链表在链表的两端进行push和pop操作,在插入节点上复杂度比较低,但是内存开销大,ziplist存储在一段连续的内存上,所以储存效率高,但是插入和删除都需要频繁申请和释放内存。
quicklist任然是一个双向链表,只是列表的每个节点都是ziplist,其实就是linkedlist和ziplist的结合,quicklist中每个节点ziplist都能够存储多个数据元素,在源码中的文件为quicklist,在源码第一行中解释为:Adoubly linked list of ziplist 意思是为一个由ziplist组成的双向链表

hash类型

数据结构
map提供两种结构来存储,一种是hashtable,另一种是前面讲的ziplist,数据量小的时候用ziplist,在redis中,哈希表分为三层,分别是,源码地址【dict.h】
dictEntry
管理一个key-value,同时保留一个同种相邻元素的指针,用来维护哈希桶的内部链:
typedef struct dictEntry {
void *key;
union { //因为value有多种类型,所以value用了union来存储
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;//下一个节点的地址,用来处理碰撞,所有分配到同一索引的元素通过next指针
链接起来形成链表key和v都可以保存多种类型的数据
} dictEntry;
dictht
实现一个hash表会使用一个buckets存放dictEntry的地址,一般情况下通过hash(key)%len得到的值就是buckets的
索引,这个值决定了我们要将此dictEntry节点放入buckets的哪个索引里,这个buckets实际上就是我们说的hash
表。dict.h的dictht结构中table存放的就是buckets的地址
typedef struct dictht {
dictEntry **table;//buckets的地址
unsigned long size;//buckets的大小,总保持为 2^n
unsigned long sizemask;//掩码,用来计算hash值对应的buckets索引
unsigned long used;//当前dictht有多少个dictEntry节点
} dictht;
dict
dictht实际上就是hash表的核心,但是只有一个dictht还不够,比如rehash、遍历hash等操作,所以redis定义了
一个叫dict的结构以支持字典的各种操作,当dictht需要扩容/缩容时,用来管理dictht的迁移,以下是它的数据结
构,源码在
typedef struct dict {
dictType *type;//dictType里存放的是一堆工具函数的函数指针,
void *privdata;//保存type中的某些函数需要作为参数的数据
dictht ht[2];//两个dictht,ht[0]平时用,ht[1] rehash时用
long rehashidx; //当前rehash到buckets的哪个索引,-1时表示非rehash状态
int iterators; //安全迭代器的计数。
} dict;
比如我们要讲一个数据存储到hash表中,那么会先通过murmur计算key对应的hashcode,然后根据hashcode取
模得到bucket的位置,再插入到链表中
集合类型
集合类型中,每个元素都是不同的,也就是不能有重复的数据。同时集合类型中的数据是无序的,一个集合类型键可以存储最多
232-1个,集合类型和列表类型的最大区别就是有序性和一致性
集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在。由于集合类型在redis内部是使用的值
为空的散列表(hash table),所以这些操作的时间复杂度都是O(1).
数据结构
Set在的底层数据结构以intset或者hashtable来存储。当set中只包含整数型的元素时,采用intset来存储,否则,
采用hashtable存储,但是对于set来说,该hashtable的value值用于为NULL。通过key来存储元素
有序集合
有序集合类型,顾名思义,和前面讲的集合类型的区别就是多了有序的功能
在集合类型的基础上,有序集合类型为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入、删除
和判断元素是否存在等集合类型支持的操作,还能获得分数最高(或最低)的前N个元素、获得指定分数范围内的元
素等与分数有关的操作。虽然集合中每个元素都是不同的,但是他们的分数却可以相同
数据结构
zset类型的数据结构就比较复杂一点,内部是以ziplist或者skiplist+hashtable来实现,这里面最核心的一个结构就
是skiplist,也就是跳跃表
如图

如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
