社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
| 分类 | 定义 |
|---|---|
| 程序 | 一个应用可以当做一个程序,比如qq软件。 |
| 进程 | 程序运行的最小的资源分配单位,一个程序可以有多个进程。 |
| 线程 | cpu最小的调度单位,必须依赖进程而存在。 |
关系:一个程序至少有一个进程,一个进程至少有一个线程。
import threading
t=threading.Thread(
target= 方法名, #运行的方法
args=() #运行的方法的参数,是个元组,无参数可不写,单个参数记住加,
)
t.start() #启动
举例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zVojUBLS-1572865723544)(../AppData/Roaming/Typora/typora-user-images/1572831852823.png)]](https://img-blog.csdnimg.cn/2019110419111555.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQwNTU4MTY2,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zuLosYtS-1572865723545)(../AppData/Roaming/Typora/typora-user-images/1572831872805.png)]](https://img-blog.csdnimg.cn/2019110419112989.png)
继承threading.Thread
重写run()方法
实例化这个类就可以创建线程,之后再调用start()方法启动
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6W1zAYSi-1572865723545)(../AppData/Roaming/Typora/typora-user-images/1572833222261.png)]](https://img-blog.csdnimg.cn/20191104191142709.png)
import threading
def hello(a):
print(a)
def eat(b):
print(b)
if __name__ == '__main__':
t1 = threading.Thread(target=hello, args=("a",))
t2 = threading.Thread(target=hello, args=("b",))
t1.start()
t2.start()
调用父类的init方法有两种:
#方法一:
super().init()
#super(MyThread, self).__init__() #都可以
#方法二:
threading.Thread.__init__(self)
举例:
import threading
class MyThread(threading.Thread):
def __init__(self, name):
super(MyThread, self).__init__() # 方法一
# threading.Thread.__init__() #方法二
self.name = name
def run(self):
print(self.name)
if __name__ == '__main__':
my = MyThread('hello')
my.start()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DHb4Atak-1572865723546)(../AppData/Roaming/Typora/typora-user-images/1572832371604.png)]](https://img-blog.csdnimg.cn/20191104191201269.png)
当我们启动一个线程到这个线程的任务方法执行完毕的过程就是这个这个线程的生命周期
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RNmmBC50-1572865723546)(../AppData/Roaming/Typora/typora-user-images/1572836866361.png)]](https://img-blog.csdnimg.cn/20191104191217207.png)
self.name='haha'
①新建:线程创建
t=threading.Thread(target=方法名)或者线程类
②就绪:当启动线程后,线程就进入就绪状态,就绪状态的线程会被放到一个cpu调度队列里面,cpu会负责让其中的线程运行,变为运行状态。
③运行状态:cpu调度一个就绪状态的线程,该线程就变为运行状态。
④阻塞状态:当运行状态的线程被阻塞变为阻塞状态,阻塞状态的线程就会重新变为就绪状态才能继续运行
⑤死亡状态:线程执行完毕
简略概括:线程的执行开销小,但不利于资源的管理和保存。进程正好相反。
①多线程的优点:
② 多线程缺点:
③ 多进程优点:
④多线程缺点:
在实际开发中,选择多线程和多进程应该从具体实际开发来进行选择。最好是多进程和多线程结合,即根据实际的需要,每个CPU开启一个子进程,这个子进程开启多线程可以为若干同类型的数据进行处理。
代码示例:
from threading import Thread
g_num = 0
def test1():
global g_num
for i in range(1000000):
# g_num += 1
b = g_num + 1
g_num = b
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
a = g_num + 1
g_num = a
print("---test2---g_num=%d"%g_num)
if __name__ == '__main__':
p1 = Thread(target=test1)
p1.start()
p2 = Thread(target=test2)
p2.start()
#--------------------运行结果------------------------
---test2---g_num=1559989
---test1---g_num=1516811
Process finished with exit code 0
问题分析:
问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果达不到预期。这种现象我们称为“线程不安全”
解决思路(解决方案:互斥锁):
(1)t1被调用的时候,获取g_num=0,然后上一把锁,即不允许其它线程操作num。
(2)对num进行加1
(3)解锁,g_num = 1,其它的线程就可以使用g_num的值,而且g_num的值是而不是原来的0
(4)同理其它线程在对num进行修改时,都要先上锁,处理完成后再解锁。
在上锁的整个过程中,不允许其它线程访问,保证了数据的正确性。
互斥锁:当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制。线程同步能够保证多个线程安全访问“竞争资源”,最简单的同步机制就是引用互斥锁。互斥锁为资源引入一个状态:锁定/非锁定状态。某个线程要更改共享数据时,先将其锁定,此时资源状态为“锁定”,其它线程不能更改;直到当前线程释放资源,将资源变成"非锁定"状态,其它的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行“写操作”,从而保证多个线程数据正确性。
分析:一个变量被锁住之后,必须解锁才可以重新使用。否则不可使用。而且锁住之后只能运行一个线程,降低了效率。
使用互斥锁解决变量被破坏代码示例:
import threading,time
g_num = 0#全局变量
def w1():
global g_num
for i in range(10000000):
mutexFlag = mutex.acquire(True)#上锁
if mutexFlag:
g_num+=1
mutex.release()#解锁
print("test1---g_num=%d"%g_num)
def w2():
global g_num
for i in range(10000000):
mutexFlag = mutex.acquire(True)# 上锁
if mutexFlag:
g_num+=1
mutex.release()# 解锁
print("test2---g_num=%d" % g_num)
if __name__ == "__main__":
mutex = threading.Lock()#创建锁
t1 = threading.Thread(target=w1)
t1.start()
t2 = threading.Thread(target=w2)
t2.start()
分析:上锁/解锁过程。
当一个线程调用锁的acquire()方法获取锁时,锁就进行“锁定(Locked)”状态。每次只有一个线程可以获得这个锁。如果此时另一个线程试图获取锁中的资源,该线程就会变为“阻塞”状态。直到拥有锁的那个线程执行release(),锁就变成“非锁定(Unlocked)”状态。
线程调试程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入“运行(running)”状态。
锁的好处:
(1)确定了某段代码只能由一个线程从头到尾完整地执行。
(2)全局变量的安全
锁的坏处:
(1)阻止了多线程的并发执行,包含锁的某段代码实际上只能以单线程模块执行,效率大大地下降了。
(2)由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁的时,可能会造成“死锁”。
死锁的两种情况:
(1)同一个线程先后两次调用lock,在第二次调用时,由于锁已经被自己占用,该线程会挂起等待自己释放锁,由于该线程已被挂起而没有机会释放锁,因此 它将一直处于挂起等待状态,变为死锁;
(2)线程A获得了锁1,线程B获得了锁2,这时线程A调用lock试图获得锁2,结果是需要挂起等待线程B释放锁2,而这时线程B也调用lock试图获得锁1,结果是需要挂起等待线程A释放锁1,于是线程A和B都在等待对方释放自己才释放,从而造成两个都永远处于挂起状态,造成死锁。
例如
1.A拿了一个苹果
2.B拿了一个香蕉
3.A现在想再拿个香蕉,就在等待B释放这个香蕉
4.B同时想要再拿个苹果,这时候就等待A释放苹果
5.这样就是陷入了僵局,这就是生活中的死锁
死锁概念:在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源时,就会造成死锁。尽管死锁很少发生,但一旦发生就会造成应用的停止响应。
产生死锁的必要条件:
① 互斥条件:指线程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一
个线程占用。如果此时还有其它线程程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
② 请求和保持条件:指线程已经保持至少一个资源,但又提出了新的资源请求,而该资
源已被其它进程占有,此时请求线程阻塞,但又对自己已获得的其它资源保持不放。
③不剥夺条件:指线程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时
由自己释放。
④环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即线程集合
{P0,P1,P2,···,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,……,Pn正在等待已被P0占用的资源。
死锁避免:理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、线程调度等方面注意如何能够不让这四个必要条件成立,如何确定资源的合理分配算法,避免线程永久占据系统资源。此外,也要防止线程在处于等待状态的情况下占用资源,在系统运行过程中,对线程发出的每一个系统能够满足的资源申请进行动态检查,并根据检查结果决定是否分配资源,若分配后系统可能发生死锁,则不予分配,否则予以分配。因此,对资源的分配要给予合理的规划。
确定网站的哪个url是数据的来源
简要分析一下网站结构,查看数据存放在哪里
查看是否有分页,并解决分页的问题
发送请求,查看response.text是否有我们所需要的数据
如果没有(可能就是ajax),我们可以通过以下两种方法来实现爬取数据
分析数据来源,查看是否通过一些接口获取到的页面内容
分析接口的步骤:
1.查看该接口数据是否为我们想要的
2.重点查看该接口的请求参数,了解哪些参数是变化的,及其变化规律
selenium+phantomjs来获取
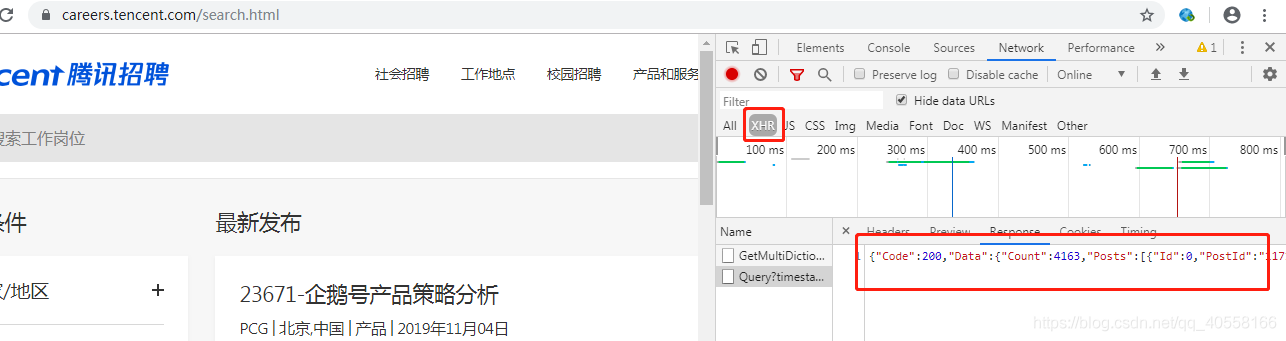
通过分析我们发现,腾讯招聘使用的是ajax的数据接口,因此我们直接去寻找ajax的数据接口链接。
import requests, json
class Tencent(object):
def __init__(self):
self.base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
self.headers = {
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'referer': 'https://careers.tencent.com/search.html'
}
self.parse()
def parse(self):
for i in range(1, 3):
params = {
'timestamp': '1572850838681',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(i),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
response = requests.get(self.base_url, headers=self.headers, params=params)
self.parse_json(response.text)
def parse_json(self, text):
# 将json字符串编程python内置对象
infos = []
json_dict = json.loads(text)
for data in json_dict['Data']['Posts']:
RecruitPostName = data['RecruitPostName']
CategoryName = data['CategoryName']
Responsibility = data['Responsibility']
LastUpdateTime = data['LastUpdateTime']
detail_url = data['PostURL']
item = {}
item['RecruitPostName'] = RecruitPostName
item['CategoryName'] = CategoryName
item['Responsibility'] = Responsibility
item['LastUpdateTime'] = LastUpdateTime
item['detail_url'] = detail_url
# print(item)
infos.append(item)
self.write_to_file(infos)
def write_to_file(self, list_):
for item in list_:
with open('infos.txt', 'a+', encoding='utf-8') as fp:
fp.writelines(str(item))
if __name__ == '__main__':
t = Tencent()
改为多线程版后
import requests, json, threading
class Tencent(object):
def __init__(self):
self.base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
self.headers = {
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'referer': 'https://careers.tencent.com/search.html'
}
self.parse()
def parse(self):
for i in range(1, 3):
params = {
'timestamp': '1572850838681',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(i),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
response = requests.get(self.base_url, headers=self.headers, params=params)
self.parse_json(response.text)
def parse_json(self, text):
# 将json字符串编程python内置对象
infos = []
json_dict = json.loads(text)
for data in json_dict['Data']['Posts']:
RecruitPostName = data['RecruitPostName']
CategoryName = data['CategoryName']
Responsibility = data['Responsibility']
LastUpdateTime = data['LastUpdateTime']
detail_url = data['PostURL']
item = {}
item['RecruitPostName'] = RecruitPostName
item['CategoryName'] = CategoryName
item['Responsibility'] = Responsibility
item['LastUpdateTime'] = LastUpdateTime
item['detail_url'] = detail_url
# print(item)
infos.append(item)
self.write_to_file(infos)
def write_to_file(self, list_):
for item in list_:
with open('infos.txt', 'a+', encoding='utf-8') as fp:
fp.writelines(str(item))
if __name__ == '__main__':
tencent = Tencent()
t = threading.Thread(target=tencent.parse)
t.start()
改成多线程版的线程类:
import requests, json, threading
class Tencent(threading.Thread):
def __init__(self, i):
super().__init__()
self.i = i
self.base_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?'
self.headers = {
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'referer': 'https://careers.tencent.com/search.html'
}
def run(self):
self.parse()
def parse(self):
params = {
'timestamp': '1572850838681',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': '',
'attrId': '',
'keyword': '',
'pageIndex': str(self.i),
'pageSize': '10',
'language': 'zh-cn',
'area': 'cn'
}
response = requests.get(self.base_url, headers=self.headers, params=params)
self.parse_json(response.text)
def parse_json(self, text):
# 将json字符串编程python内置对象
infos = []
json_dict = json.loads(text)
for data in json_dict['Data']['Posts']:
RecruitPostName = data['RecruitPostName']
CategoryName = data['CategoryName']
Responsibility = data['Responsibility']
LastUpdateTime = data['LastUpdateTime']
detail_url = data['PostURL']
item = {}
item['RecruitPostName'] = RecruitPostName
item['CategoryName'] = CategoryName
item['Responsibility'] = Responsibility
item['LastUpdateTime'] = LastUpdateTime
item['detail_url'] = detail_url
# print(item)
infos.append(item)
self.write_to_file(infos)
def write_to_file(self, list_):
for item in list_:
with open('infos.txt', 'a+', encoding='utf-8') as fp:
fp.writelines(str(item) + 'n')
if __name__ == '__main__':
for i in range(1, 50):
t = Tencent(i)
t.start()
这样的弊端是如果有多个多线程同时运行,会导致系统的崩溃,因此我们使用队列,控制线程数量
import requests,json,time,threading
from queue import Queue
class Tencent(threading.Thread):
def __init__(self,url,headers,name,q):
super().__init__()
self.url= url
self.name = name
self.q = q
self.headers = headers
def run(self):
self.parse()
def write_to_file(self,list_):
with open('infos1.txt', 'a+', encoding=
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_40558166/article/details/102903321
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
