社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
根据业务场景需要实时处理日志进行实时图表展示(Highchart等),如果进行对数据库频繁抽取会对数据库服务器造成较大的压力,相应的web服务也会受到很大的影响;因此,抽取数据库的日志既能够很大的减轻数据库服务的压力,又能够解决实时处理实时展示图表的需求。本博客MySQL Binlog日志采集为例提供解决方案
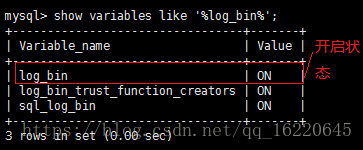
1) 首先查看mysql是否已经开启binlog
2) 下载maxwell
组件下载地址:https://download.csdn.net/download/qq_16220645/11396123
解压tar -zxvf maxwell-1.17.1.tar.gz
3) 给mysql授权(只针对于maxwell库的操作)
其中user01为数据库用户名 666666为数据库密码
GRANT ALL on maxwell.* to 'user01'@'%' identified by '666666';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'user01'@'%';
4) 执行maxwell命令行(注:maxwell默认是把监听的mysql的binlog日志发送到kafka的主题叫maxwell的topic上的)
具体的demo 如下:
bin/maxwell --user='user01' --password='666666' --host='127.0.0.1' --include_dbs=db1 --include_tables=table1,table2 --producer=kafka --kafka.bootstrap.servers=d1:9092,d2:9092,d3:9092 --kafka_topic test
注:--user是数据库用户名 --password数据库密码 --host表示安装mysql的服务器地址(可以和安装maxwell的服务器不在同一台) --include_dbs表示要筛选具体的数据库 --include_tables表示筛选具体库下的具体表 --kafka.bootstrap.servers表示kafka的Ip地址和端口号 --kafka_topic kafka表示kafka对应的topic
1) 启动kafka命令行(这里以后台进程方式运行)
nohup bin/kafka-server-start.sh config/server.properties &
2) 创建kafka的topic为test主题
bin/kafka-topics.sh --zookeeper d1:2181,d2:2181,d3:2181 --create --topic test --partitions 20 --replication-factor 1
3) 启动消费者窗口
bin/kafka-console-consumer.sh --bootstrap-server d1:9092,d2:9092,d3:9092 --topic test
注:本demo的spark版本为2.2.1 kafka的版本为0.10.0,请注意spark版本与kafka版本对应,具体可参考spark官方网站的说明http://spark.apache.org/docs/2.2.1/structured-streaming-kafka-integration.html
package com.baison.realTimeCalculation
import java.lang
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.util.Try
object IposRealTime {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setAppName("IposRealTime")
.set("spark.streaming.blockInterval", "50")//生成block的间隔
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")//用kryo序列化
.set("spark.streaming.backpressure.enabled","true") //数据的反压机制
.set("spark.task.maxFailures","10")//task最大失败次数
.set("spark.streaming.kafka.maxRetries","5") //kafka的最大重试次数
.set("spark.streaming.stopGracefullyOnShutdown","true")//程序优雅关闭
.set("spark.io.compression.codec","snappy") //压缩模式
.set("spark.rdd.compress","true") //压缩RDD的分区
.registerKryoClasses(Array(classOf[EveryWeekForm],classOf[HotGoodsForm],classOf[MemberFlowForm],
classOf[TodayYeJiForm]))
val ssc=new StreamingContext(conf,Durations.seconds(2))
//kafka的配置
val kafkaParam=Map[String,Object](
Constants.KAFKA_METADATA_BROKER_LIST->ConfigurationManager.getProperty(Constants.KAFKA_METADATA_BROKER_LIST),
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"->classOf[StringDeserializer],
Constants.KAFKA_GROUP_ID->ConfigurationManager.getProperty(Constants.KAFKA_GROUP_ID),
Constants.KAFKA_AUTO_OFFSET_RESET->ConfigurationManager.getProperty(Constants.KAFKA_AUTO_OFFSET_RESET),//从该topic最新位置开始读取数据
"enable.auto.commit"->(false:lang.Boolean),
Constants.SESSION_TIMEOUT_MS->ConfigurationManager.getProperty(Constants.SESSION_TIMEOUT_MS) //最大程度的确保Spark集群和kafka连接的稳定性
)
val topics=List(ConfigurationManager.getProperty(Constants.KAFKA_TOPICS)).toSet
val inputDStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent, Subscribe[String, String](topics, kafkaParam)).repartition(50)
ssc.checkpoint(Constants.SPARK_CHECKPOINT_DATA)
//此处进行处理数据操作
ssc.start()
ssc.awaitTermination()
}
如有错误之处,请指正,不胜感激。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!