社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
由于工作需要,小编最近开始研究大数据流式处理框架SparkStreaming,了解的很浅显,下面跟大家分享一下。
了解SparkStreaming之前,我们先来了解什么是Spark。
一、什么是spark?
1.Spark的认识
spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2.hadoop与spark的区别
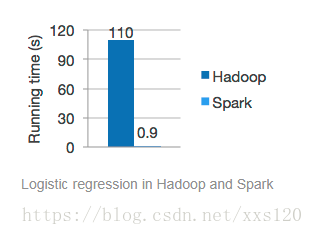
hadoop是基于磁盘的迭代过程,每一次都有一个磁盘落地过程,第二次迭代的时候再去读取,所以速度较慢。而spark是基于内存的迭代过程,它不需要落地到磁盘再读取,而是直接在内存中计算,所以速度特别快,我们可以看到spark官网上hadoop与spark的速度对比将近1:100(如下图)。但是也有缺点,既然是基于内存的计算。所以对内存的消耗很高,因此现在能够承担如此高额费用的公司也有限。
3.spark的api
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。我认为spark的api其实就是各种RDD算子,RDD算子又包括action算子和Transformation算子。
如果能够把所有的RDD算子掌握,那么spark应该就算入门了。
4.spark的组件(Sprak生态系统)
同hadoop一样,spark也有她的组件。通过一张图来理解,有兴趣的同行可以自行去了解
spark生态圈以Spark Core为核心,从HDFS、Amazon S3和HBase等持久层读取数据,以MESS、YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序的计算。 这些应用程序可以来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib/MLbase的机器学习、GraphX的图处理和SparkR的数学计算等等.
二、什么是SparkStreaming
1.SparkStreaming的认识
如上可知SparkStreaming就是spark的组件之一。那么什么是SparkStreaming呢?和我前段时间研究的storm类似。
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备
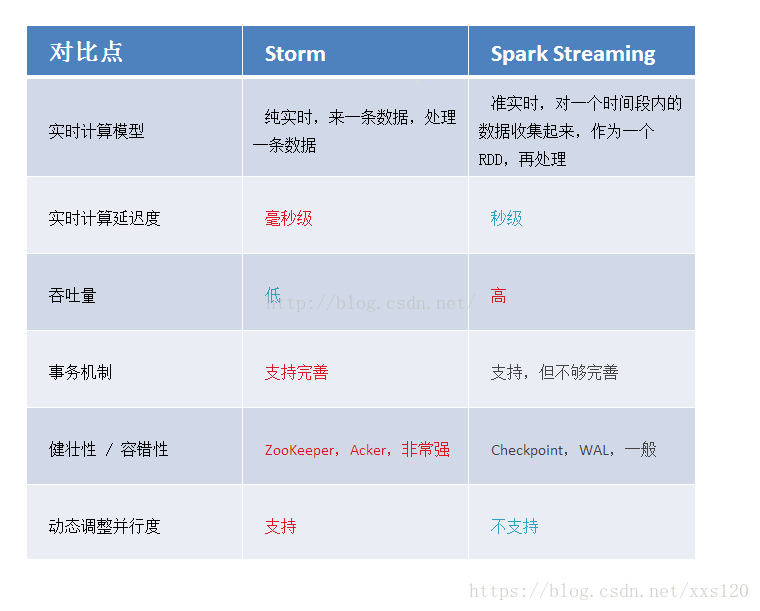
2.SparkStreaming和storm的区别
我们来从SparkStreaming和storm的区别中深入理解SparkStreaming
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
三、我的用途
我使用sparksrtreaming的主要用途是处理mysql插入数据的过滤,想实现每30秒过滤一次的实时性。前面flume的配置我就不多说的,前面已经分享过。大家可以看看https://blog.csdn.net/xxs120/article/details/79925393
下面分享我的主要代码,由于我的scala语言了解的不是很深入,我使用java代码编写
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("DATA Filter").setMaster("local[2]");
JavaStreamingContext jscc = new JavaStreamingContext(sparkConf, new Duration(1 * 30 * 1000));
Map<String, Integer> topicMap = new HashMap<String, Integer>();
String[] topics = TOPIC.split(",");
for (String topic : topics) {
topicMap.put(topic, numThreads);
}
//从Kafka中获取数据
JavaPairReceiverInputDStream<String, String> messages = KafkaUtils.createStream(jscc, ZK_QUORUM, TOPIC, topicMap);
//从话题中过滤所需数据
JavaDStream<String> lines = messages.map(new Function<Tuple2<String, String>, String>() {
public String call(Tuple2<String, String> tuple2) {
return tuple2._2;
}
});
total=0;
i=0;
// 将数据拆分成所需数据,进行处理
JavaPairDStream<Integer, Integer> line = lines.mapToPair(new PairFunction<String, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(String t) throws Exception {
System.out.println(t);
JSONParser jsonParser = new JSONParser(JSONParser.DEFAULT_PERMISSIVE_MODE);
JSONObject map=(JSONObject)jsonParser.parse(t);
if (map.containsKey("commit")) {
boolean commit = Boolean.valueOf(map.get("commit").toString());
if (map.get("table").toString().equals("stang_bid") && map.get("type").toString().equals("insert") && commit) {
String data = map.get("data").toString().trim();
JSONObject mapdata = (JSONObject) jsonParser.parse(data);
if (mapdata.get("author").toString().equals("中国采购与招标网")) {
ProducerRecord<String, String> msg = new ProducerRecord<String, String>(producerTopic, t);
procuder.send(msg);
}
else if (mapdata.get("title") != null && mapdata.get("info") != null) {
int id = Integer.parseInt(mapdata.get("id").toString());
String title = mapdata.get("title").toString();
title = ScreenOfTitle(title);
String info = mapdata.get("info").toString();
Document d = Jsoup.parse(info);
info = d.text();
ResultSet rs = null;
int result = 0;
if (title != null) {
for (String key : keys) {
if (title.contains(key) | info.contains(key)) {
if (pattern1.matcher(title).find() | pattern1.matcher(info).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 1);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern2.matcher(title).find() | pattern2.matcher(info).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 2);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern3.matcher(title).find() | pattern3.matcher(info).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 3);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern4.matcher(title).find() | pattern4.matcher(info).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 4);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern5.matcher(title).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 5);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern6.matcher(title).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 6);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
} else if (pattern7.matcher(title).find()) {
pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 7);
pstmt.setInt(2, 1);
pstmt.setInt(3, id);
result = pstmt.executeUpdate();
break;
}
}
i++;
}
}
total++;
}
}
}
return new Tuple2<Integer, Integer>(total, i);
}
});
line.print();
jscc.start();
jscc.awaitTermination();
}spark的学习之路还很长,希望大家一起努力,共同进步
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!