Kafka的Topic和Partition
Topic
- Topic是Kafka数据写入操作的基本单元,可以指定副本
- 一个Topic包含一个或多个Partition,建Topic的时候可以手动指定Partition个数,个数与服务器个数相当
- 每条消息属于且仅属于一个Topic
- Producer发布数据时,必须指定将该消息发布到哪个Topic
- Consumer订阅消息时,也必须指定订阅哪个Topic的信息
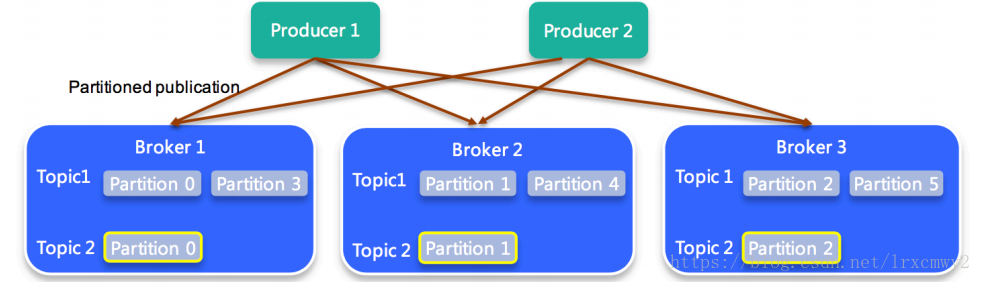
Partition
- 每个Partition只会在一个Broker上,物理上每个Partition对应的是一个文件夹
- Kafka默认使用的是hash进行分区,所以会出现不同的分区数据不一样的情况,但是partitioner是可以override的
- Partition包含多个Segment,每个Segment对应一个文件,Segment可以手动指定大小,当Segment达到阈值时,将不再写数据,每个Segment都是大小相同的
- Segment由多个不可变的记录组成,记录只会被append到Segment中,不会被单独删除或者修改,每个Segment中的Message数量不一定相等
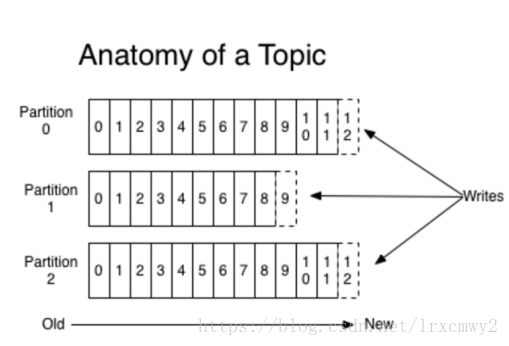
- 清除过期日志时,支持删除一个或多个Segment,默认保留7天的数据
- Kafka实际是用先写内存映射的文件,磁盘顺序读写的技术来提高性能的。Producer生产的消息按照一定的分组策略被发送到broker中的partition中的时候,这些消息如果在内存中放不下了,就会放在partition目录下的文件中,partition目录名是topic的名称加上一个序号。在这个目录下有两类文件,一类是以log为后缀的文件,另一类是以index为后缀的文件,每一个log文件和一个index文件相对应,这一对文件就是一个Segment File,其中的log文件就是数据文件,里面存放的就是Message,而index文件是索引文件。Index文件记录了元数据信息,指向对应的数据文件中Message的物理偏移量。
- LogSegment文件命名的规则是,partition全局的第一个Segment从0(20个0)开始,后续的每一个文件的文件名是上一个文件的最后一条消息的offset值,这样命名的好处是什么呢?假如我们有一个Consumer已经消费到了offset=x,那么如果要继续消费的话,就可以使用二分查找法来进行查找,对LogSegment文件进行查找,就可以定位到某个文件,然后拿x值去对应的index文件中去找第x条数据所在的位置。Consumer读数据的时候,实际是读Index的offset,并且会记录上次读到哪里。

- 再详细的分析一下Index文件,上图的左半部分是Index文件,里面存储的是n对key-value,其中key是Message在log文件中的编号,比如1,3,6,8.....,表示第1条、第3条、第6条、第8条消息等,但是因为Index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中,但缺点是没有建立索引的Message不能一次定位到其在log文件中的位置,这种情况下就需要做一次顺序扫描,不过这次顺序扫描的范围就会很小了。value值表示该消息的物理偏移地址。

- 虽然Kafka是顺序写入数据的,但是难以保证全局的消费是有序的。当有多个partition的时候,message在分组存到partition中的时候就已经是无序了,比如0-10这部分消息存到partition1,11-20被存到partition2等。唯一能保证的是,针对一个topic里的数据,在partition的内部消息消费的有序性,全局有序是做不到的。
Message

一个Message由固定长度的header和一个变长的消息体body组成
8 byte offset在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message
4 byte message sizemessage大小
4 byte CRC32用crc32校验message
1 byte “magic"表示本次发布Kafka服务程序协议版本号
1 byte “attributes"表示为独立版本、或标识压缩类型、或编码类型。
4 byte key length表示key的长度,当key为-1时,K byte key字段不填
K byte key可选
value bytes payload表示实际消息数据。
参考
Kafka文件的存储机制:https://www.cnblogs.com/jun1019/p/6256514.html
https://baijiahao.baidu.com/s?id=1608205621370302980&wfr=spider&for=pc
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/lrxcmwy2/article/details/82853300
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

