社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
标签(空格分隔): Kafka
Kafka is used for building real-time data pipelines and streaming apps
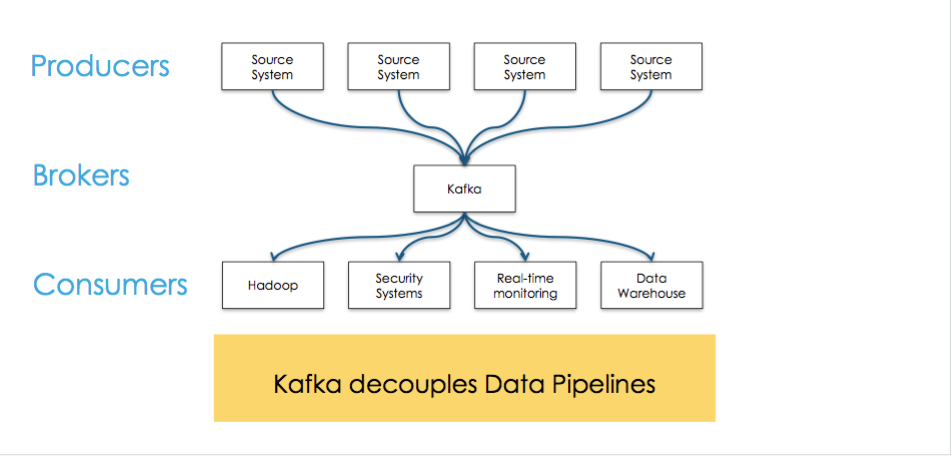
Kafka maintains feeds of messages in categories called topics.
消息都归属于一个类别成为topic,在物理上不同Topic的消息分开存储,逻辑上一个Topic的消息对使用者透明 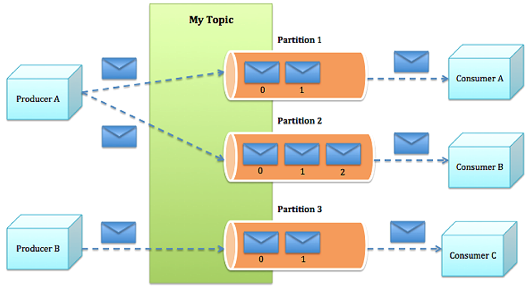
Topics are broken up into ordered commit logs called partitions
每个Topics划分为一个或者多个Partition,并且Partition中的每条消息都被标记了一个sequential id ,也就是offset,并且存储的数据是可配置存储时间的 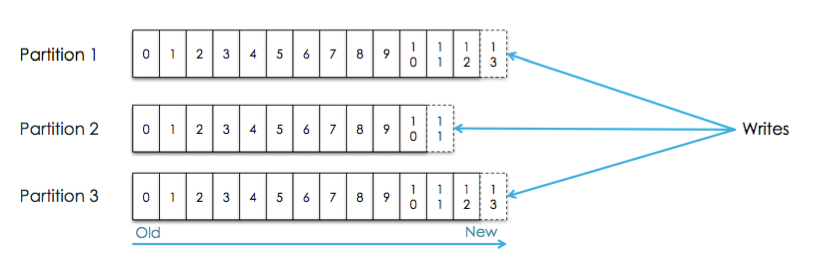
消息只保证在同一个Partition中有序,所以,如果要保证从Topic中拿到的数据有序,则需要做到:
kafka能保证的是:
Partition对应逻辑上的Log
A replica is deemed to be “in-sync” if
The group of in-sync replicas for a partition is called the ISR(In-Sync-Replicas)
Durability can be configured with the producer configuration request.required.acks
Minimum available ISR can also be configured such that an error is returned if enough replicas are not available to replicate data
所以,kafka可以选择不同的durability来换取不同的吞吐量
| Durability | Behaviour | Per Event Latency | Required Acknowledgements(request.required.acks) |
|---|---|---|---|
| Hignest | ACK all ISRs have received | Higest | -1 |
| Medium | ACK once the leader has received | Medium | 1 |
| Lowest | No ACKs required | Lowest | 0 |
通用,kafka可以通过增加更多的Broker来提升吞吐量
一个推荐的配置:
| Property | Value |
|---|---|
| replication | 3 |
| min.insync.replicas | 2 |
| request.required.acks | -1 |
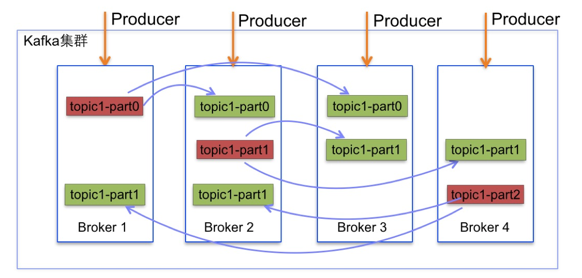
Kafka is run as a cluster comparised of one or more servers each of which is called broker 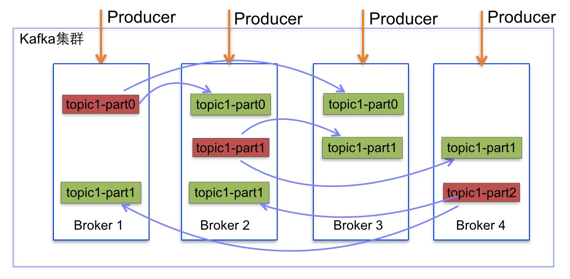
Processes that publish messages to a kafka topic are called producers
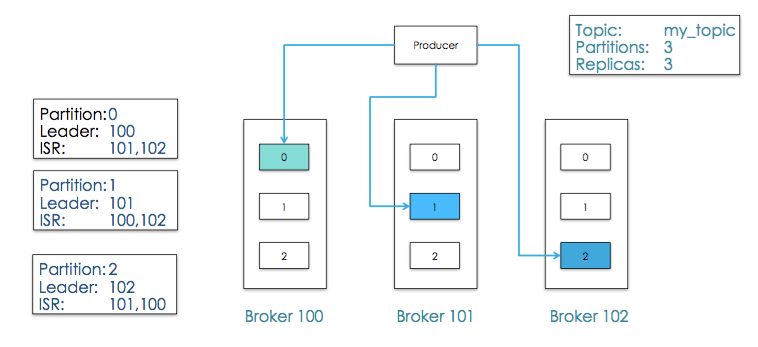
Processes that subscribe(订阅) to tpics and process the feed of published messages are called consumers
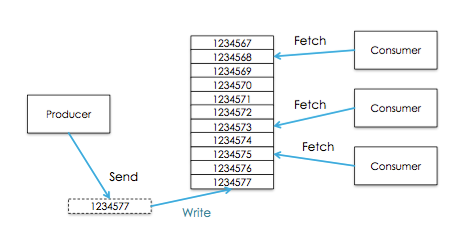
Consumer可以从任一地方开始消费,然后又回到最大偏移量处,Consumers又可以被划分为Consumer Group
Consumer Group是显式分布式,多个Consumer构成组结构,Message只能传输给某个Group中的某一个Consumer
常用的Consumer Group模式:
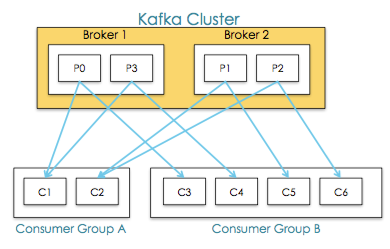
Consumer Groups 提供了topics和partitions的隔离 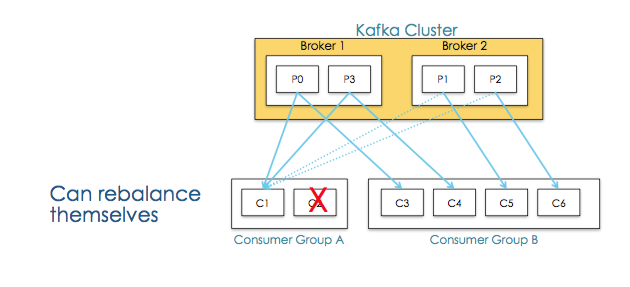
并且当某个Consumer挂掉后能够重新平衡
Consumer Group的应用场景
Partition
topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1 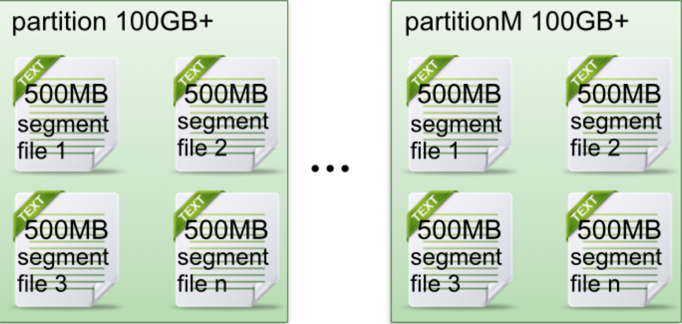
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
segment file

其中.index索引文件存储大量元数据,.log数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。他们两个是一一对应的,对应关系如下 

参数说明:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
解释:
消息传递语义: Producer 角度
当Producer向broker发送消息时,一旦这条消息被commit,因为replication的存在,它就不会丢,但是如果Producer发送数据给broker后,遇到网络问题而造成通信中断,那Producer就无法判断该条消息是否已经commit
理想的解决方案:Producer可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了Exactly once,目前默认情况下一条消息从Producer到broker是确保了At least once
消息传递语义: Consumer : High Level API
Consumer在从broker读取消息后,可以选择commit,该操作会在Zookeeper中保存该Consumer在该Partition中读取的消息的offset
该Consumer下一次再读该Partition时会从下一条开始读取;如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同
现实的问题:到底是先处理消息再commit,还是先commit再处理消息?
消息传递语义: Consumer : Lower Level API
Exactly once的实现思想:协调offset和消息数据
经典做法是引入两阶段提交
offset和消息数据放在同一个地方:Consumer拿到数据后可能把数据放到共享空间中,如果把最新的offset和数据本身一起写到共享空间,那就可以保证数据的输出和offset的更新要么都完成,要么都不完成,间接实现Exactly once
High level API而言,offset是存于Zookeeper中的,无法获取,而Low level API的offset是由自己去维护的,可以实现以上方案
同一个Partition可能会有多个Replica,需要保证同一个Partition的多个Replica之间的数据一致性
而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据
副本与高可用性:副本Leader Election算法
副本与高可用性:Replica分配算法
将所有Replica均匀分布到整个集群
将所有n个Broker和待分配的Partition排序
将第i个Partition分配到第(i mod n)个Broker上
将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
Kafka通过Message分组和Sendfile系统调用实现了zero-copy
传统的socket发送文件拷贝 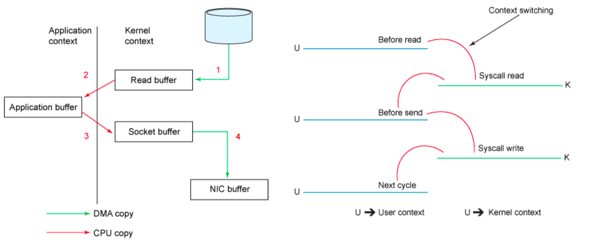
1.内核态
2.用户态
3.内核态
4.网卡缓存
经历了内核态和用户态的拷贝
sendfile系统调用 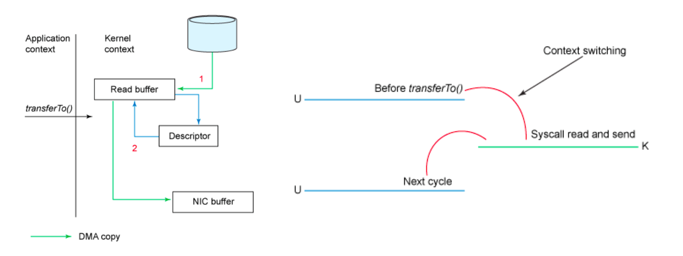
避免了内核态与用户态的上下文切换动作
sendfile
优点:大块文件传输效率高
缺点:小块文件效率较低、BIO而不是NIO
mmap+write
优点:使用小块文件传输时效率高
缺点:比sendfile多消耗CPU、内存安全控制复杂
应用
Kafka使用第一种,大块数据传输
RocketMQ使用第二种,小快数据传输
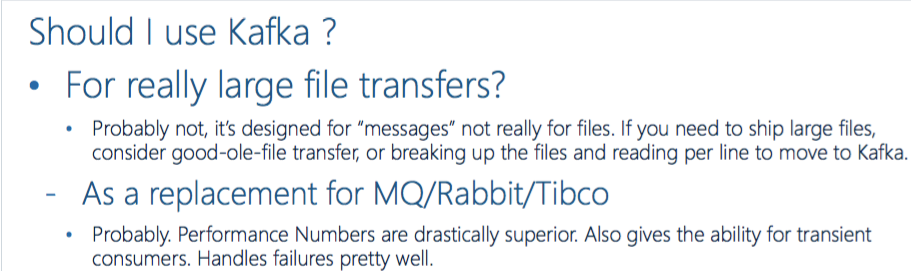
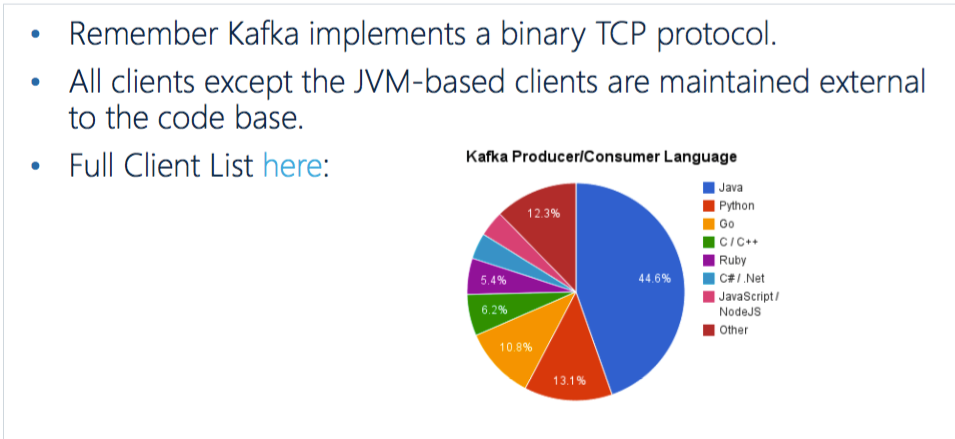
echo "此Kafka集群所有的Topic : "
kafka-topics --list --zookeeper dc226.dooioo.cn:2181, dc227.dooioo.cn:2181,dc229.dooioo.cn:2181/kafka
echo "您要查看的Topic详细 : "
kafka-topics --describe --zookeeper dc226.dooioo.cn:2181, dc227.dooioo.cn:2181,dc229.dooioo.cn:2181/kafka --topic $topicNamekafka-topics --create --zookeeper dc226.dooioo.cn:2181,dc227.dooioo.cn:2181,dc229.dooioo.cn:2181/kafka --replication-factor 1 --pa
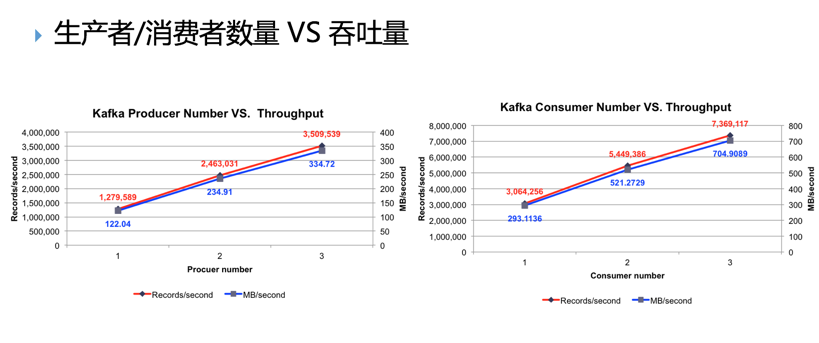
rtitions 1 --topic $topicNamekafka-console-producer --broker-list 10.22.253.227:9092 --topic $topicName kafka-console-consumer --zookeeper 10.22.253.226:2181,10.22.253.227:2181,10.22.253.229:2181/kafka --topic $topicName --from-beginning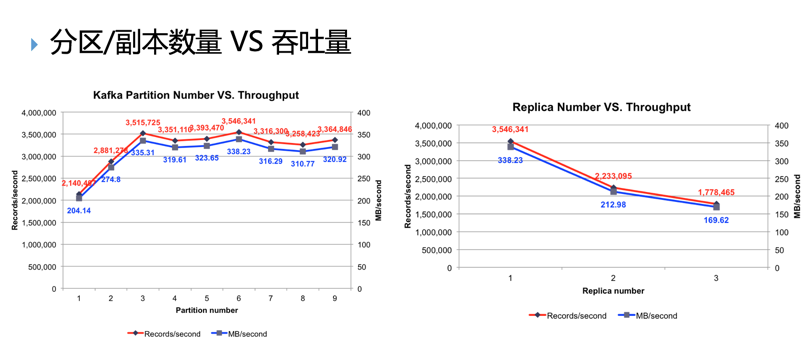
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

