社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
分区原因:
1.分区的原因
(1)方便在集群中扩展,每个partition可以通过调整以适应它所在的机器,而一个topic又可以有多个partition组成,因此整个集群就可以适应任意大小的数据了。
(2)可以提高并发,因此可以以partition为单位读写
2.partition的三种分区原则
(1)指明partition的情况下,直接将指明的值直接作为partition的值
(2)没有指明partition值单有key的值,将key的hash值与toptic的partition数进行取余的到partition值
(3)既没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin 算法。
数据的可靠性
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据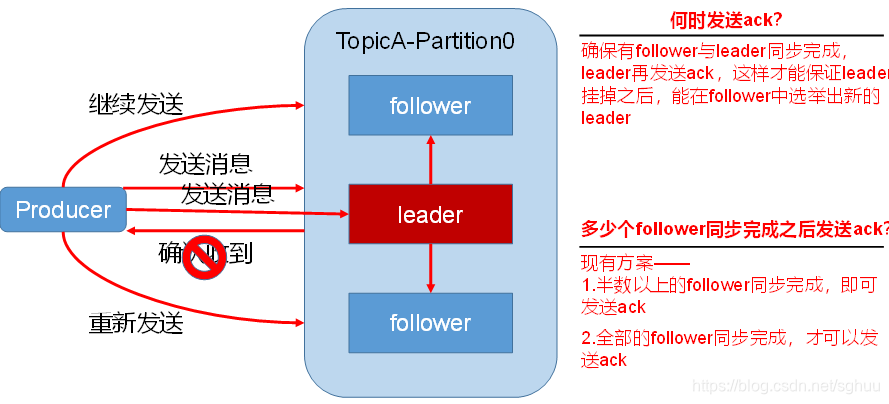
副本数据同步原则:
Kafka选择了第二种方案,原因如下:
1.同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
2.虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小,因为kafka一般部署在同一个机架内,因而网络延迟比较低。
2)ISR
采用第二种方案之后,设想以下情景:leader收到数据,所有follower都开始同步数据但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Leader维护了一个动态的in-sync replica set (ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就会给producer发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。Leader发生故障之后,就会从ISR中选举新的leader。被踢出ISR的follower重连后依然会从leader中拉取数据,直到拉取的数据到达ISR的中partition的HW位置时,此被踢出的follower会重新加入ISR中。
ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
acks参数配置:
acks:
0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;(这是kafka默认的模式!!!)
-1(all):producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复
故障处理机制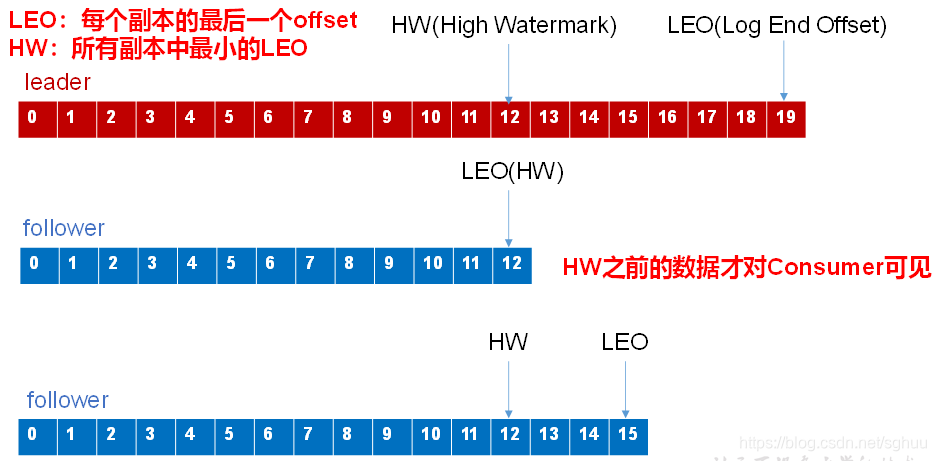
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
Exactly Once语义
对于某些比较重要的消息,我们需要保证exactly once语义,即保证每条消息被发送且仅被发送一次。
在0.11版本之后,Kafka Producer引入了幂等性机制(idempotent),配合acks = -1时的at least once语义,实现了producer到broker的exactly once语义。
idempotent + at least once = exactly once
使用时,只需将enable.idempotence属性设置为true,kafka自动将acks属性设为-1,并将retries属性设为Integer.MAX_VALUE。
即每条消息都有唯一的标识:为了实现Producer的幂等语义,Kafka引入了Producer ID(即PID)和Sequence Number。每个新的Producer在初始化的时候会被分配一个唯一的PID,该PID对用户完全透明而不会暴露给用户。
对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number。
类似地,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每次Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号(即最后一次Commit的消息的序号)大一,则Broker会接受它,否则将其丢弃:
如果消息序号比Broker维护的序号大一以上,说明中间有数据尚未写入,也即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
(Exactly once详见https://www.cnblogs.com/jasongj/p/7912348.html)
消费方式
consumer采用pull(拉)模式从broker中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
分区分配策略
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。
Kafka有两种分配策略,一是roundrobin,一是range。
示例:0、1、2、3、4、5、6、 7、8、 9 、总共十个分区,四个consumer
采取roundrobin策略:
consumer0 : 0、4、8
consumer1: 1、5、9
consumer2: 2、6
consumer3: 3、7
采取range策略
consumer0 :0,1 ,2
consumer0 : 3,4 , 5
consumer0 : 6 , 7
consumer0 : 8 , 9
roundrobin适合只有一个topic的分区分配方式,如果有多个主题,会造成consumer消费数据的倾斜
range适合多个topic的分区分区分配的方式,会均衡多个topic下的consumer是消费数据的数量(默认分配方式)
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
