社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
在windows系统中安装VMware14pro,直接下载安装,无需赘述
下载地址:https://www.vmware.com/cn.html
激活方式参考另一篇博文:https://blog.csdn.net/MDbabyface/article/details/82084346
ps:如有条件,请购买使用
CentOS 是一个基于Red Hat Linux 提供的可自由使用源代码的企业级Linux发行版本。也可以选择其他Linux发行版。例如: Ubuntu、Fadora
下载地址:https://www.centos.org/download/
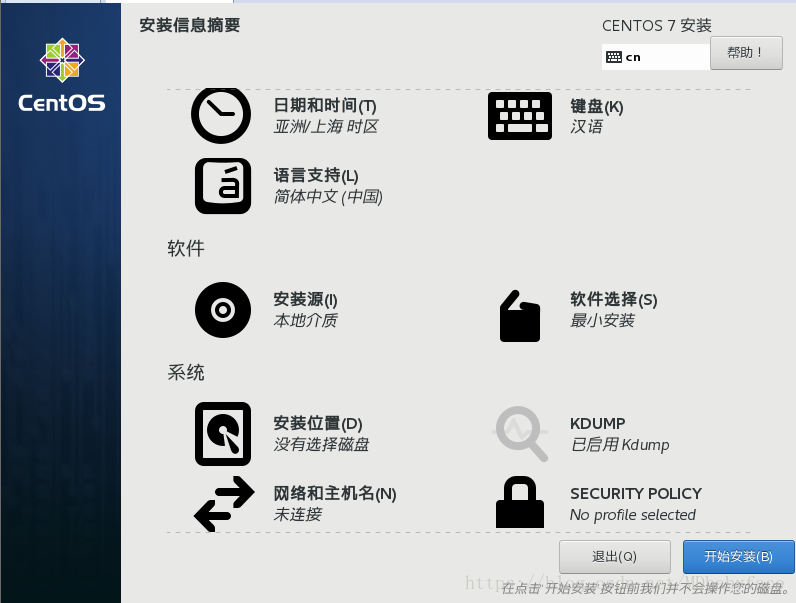
选择创建新的虚拟机——选择典型安装——选择centos7镜像获取位置——选择centos7系统安装位置——磁盘大小默认20G
点击完成即可完成系统安装
进入配置界面——选择语言中文——软件选择(最小化安装或者带图形界面)——网络与主机名自行配置——选择开始安装
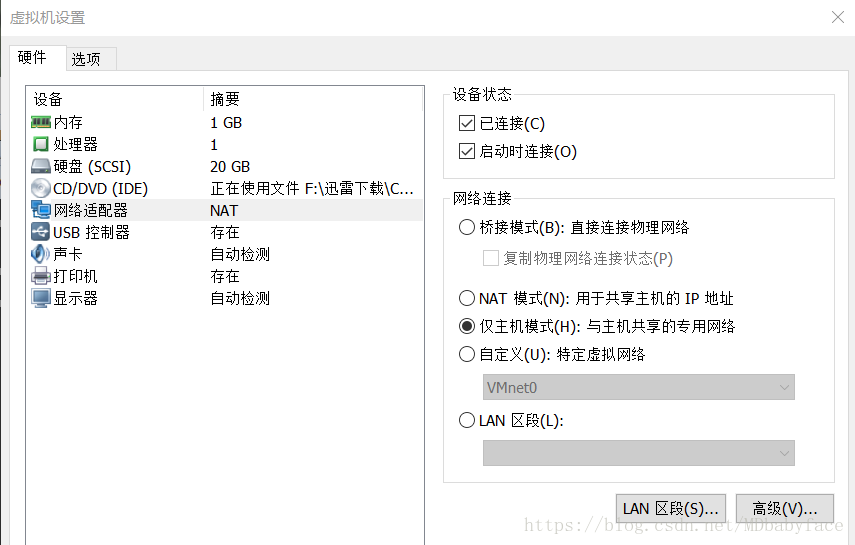
安装完成之后打开虚拟机设置,网络适配器选择仅主机模式(也可选择其他模式,此处仅配置单机hadoop,选用仅主机模式)
ps:这里简单介绍一下三种网络模式
桥接模式:相当于在宿主机前端加入了一个虚拟交换器,宿主机和虚拟机共享这个虚拟交换器,虚拟机需要手动配置IP地址、子网掩码,而且需要和宿主机处于同一个网段,保证能与宿主机进行通信。虚拟机相当于一台独立主机。
NAT模式:此种模式下宿主机成为双网卡主机,同时参与现有 的宿主局域网和新建的虚拟局域网,虚拟局域网通过虚拟的NAT服务器,使用宿主机IP地址访问公网。
仅主机模式:此种模式下宿主机与上所以虚拟机可以相互通信,但是虚拟机和真实网络是被隔离开的。
把原先的主机名删去,写入新的主机名 hadoop,保存退出
修改主机名需要重启才能生效,可以通过临时修改使得主机名立即生效
查看当前主机名
表示修改成功
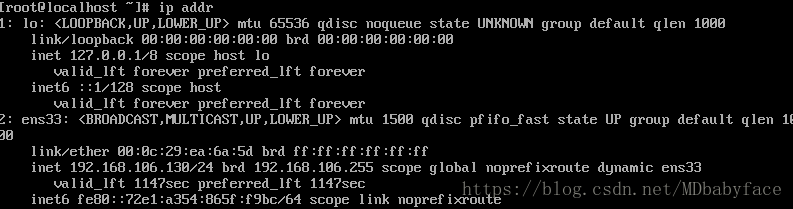
查看当前网络状态:
第一个网卡lo是回路网卡,机器与自己通信的,
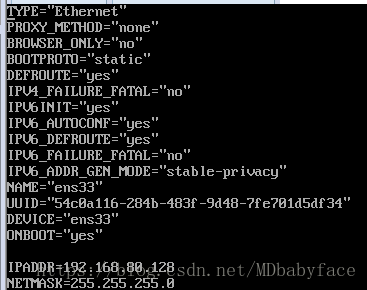
第二个ens33是与外部通信的网卡,可以看到IP地址,但默认情况下IP地址自动获取,因此需要手动修改成静态
输入指令:
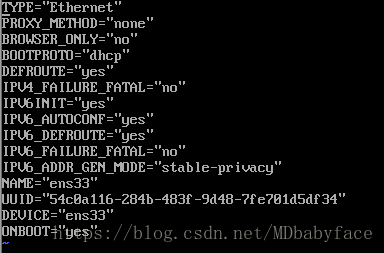
打开ens33配置文件
将“BOOTPROTO=dhcp”改成“BOOTPROTO=static”(设置成静态)
将“ONBOOT=no”修改成“ONBOOT=yes”(设置开机启动网卡)
在下面写入:
IPADDR=192.168.80.128
NETMASK=255.255.255.0
因此本机网络设置为仅主机模式无法连接外网,所以仅设置IP地址和子网掩码
其他模式需要连接外网请自行设置网关和DNS。
重启网络即可完成设置
输入指令
在文件中写入一行
192.168.91.124 hadoop
:wq 保存退出
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
输入指令 systemctl disable firewalld
若想立即成效,则输入关闭防火墙指令
systemctl stop firewalld
authorized_keys:存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥
id_rsa : 生成的私钥文件
id_rsa.pub : 生成的公钥文件
know_hosts : 已知的主机公钥清单
输入指令生成秘钥
enter几次之后完成秘钥生成
输入ls指令即可查看生成的秘钥文件
将公钥写入新的文件authorized_keys中
测试一下:ssh hadoop
显示last login并且无需输入密码则设置成功
查看当前jdk版本
java -version
hadoop官网推荐使用sun公司的jdk版本,因此先卸载原先的jdk
yum -y remove java java-1.8.0-openjdk-headless.x86_64
yum -y remove java java-1.7.0-openjdk-headless.x86_64
yum -y remove java java-1.8.0-openjdk
查看是否卸载完成
将jdk安装包文件拷入到 usr/java 下
cd到usr/java 目录下
解压java安装包
tar -zxvf jdk1.8.0_181
安装完成后需要配置一下环境变量,编辑/etc/profile文件:
vim /etc/profile
在文件尾部添加如下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_131/ export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin
最后一步就是通过source命令重新加载/etc/profile文件,使得修改后的内容在当前shell窗口有效:
source /etc/profile
4、测试查看当前jdk版本
jdk安装完成!
将下载好的hadoop安装包拷入到 /usr/hadoop 文件夹中
cd 到/usr/java/ 目录下
tar -zxvf hadoop-2.8.4.tar.gz
解压完成
进入到hadoop的配置文件目录中
/usr/hadoop/hadoop-2.8.4/etc/hadoop
vi hadoop-env.sh
将JAVA_HOME修改为jdk安装路径
vi core-site.xml
# 在<configuration>中添加配置
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<!-- 指定hadoop运行时产生临时文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/java/jdk1.8.0_181/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
将 mapred-site.xml.template复制一份并重命名为 mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
# 配置mapred-site.xml <configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
保存退出,配置完成!
cd到bin目录下
./hdfs namenode -format
看见这一行提示即表示格式化成功
cd 到sbin目录下
启动 start-all.sh
start-all.sh
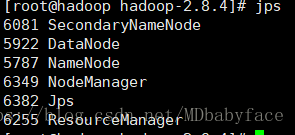
用jps指令查看当前启动的进程
看见下面几个即表示启动成功
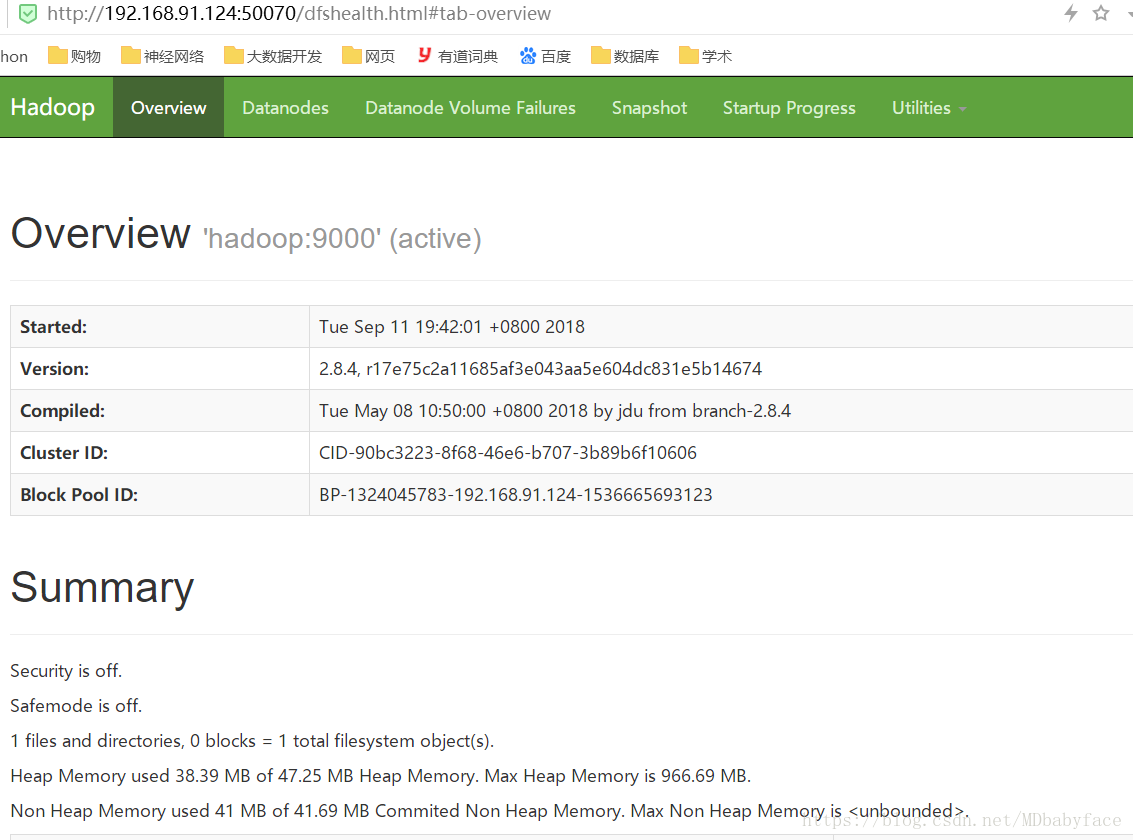
在浏览器地址栏中输入 192.168.91.124:50070(IP地址可能不一样,端口是一样的)
登录成功!
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!