社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
作者写在前面的话:
单节点是Hadoop当作一个JavaApplication来运行的,大多数是用来测试Hadoop项目能否正确运行来存在的,在官网中,还说该模式对debug很有用,hhhh等以后写代码的时候再议。
伪分布式与完全分布式的区别也很明显,因为,伪分布式是,在同一个服务器节点上运行一个NameNode和一个DataNode,以及ResourceManage与NodeManage程序。并不能达到管理多个服务器节点的实际用途。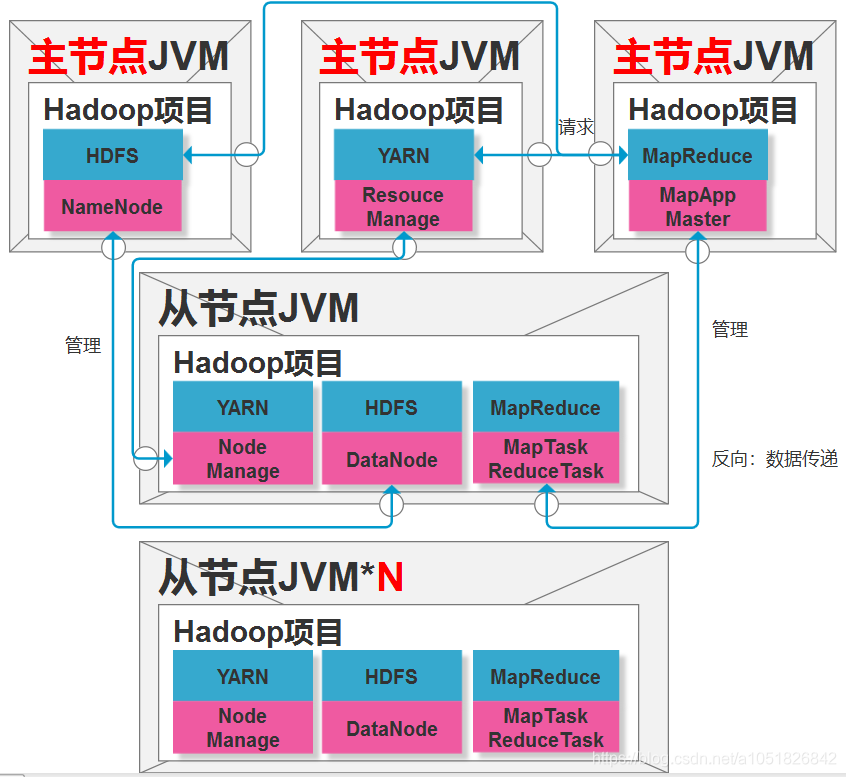
下图,为他人制作的完全分布式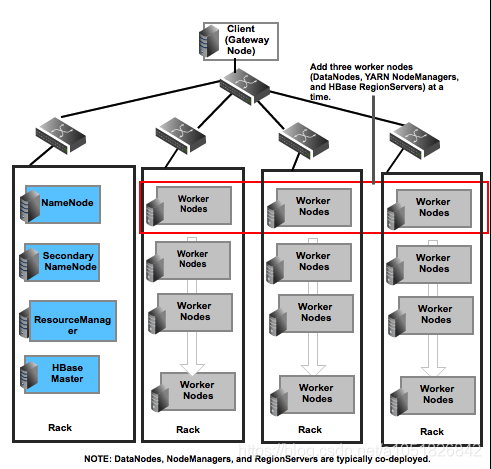
大数据存储
一个NameNode和一个DataNode,这两个是作为Hadoop中的HDFS大数据存储系统独立存在的程序。也就是在单节点的基础上,化分出单独的两个程序NameNode和DataNode来管理大数据存储,而不是单节点模式使用Linux本地文件系统了。当然,HDFS仍然是基于Linux节点资源,对服务器节点磁盘空间做了封装,以HDFS的分布式思想进行调度存储。
服务器集群资源调控
同样,对于服务器节点集群来说,资源调度也要进行统一规划,以达到全局最优解,即对于多个节点的资源管理通过YARN框架来进行解决。
也就是在单节点基础上,单独化分出ResourceManage与NodeManage两个程序来对节点服务器资源进行管理。而不再是直接使用Linux内核的资源调度系统,即也是对Linux内核资源管理命令进行了封装。
Hadoop单节点模式:测试Hadoop项目的完整性,以及以最小代价进行debug实验,当你使用大规模集群实验完成特定任务程序,你会发现代价很大,所以Hadoop单节点模式,不化分细化出任何单独的子程序对资源/存储进行控制,也没必要,就一台服务器,直接使用Linux内核命令即可,只是为了实验我们将要在集群部署的任务代码能否在Hadoop项目正确运行。
单节点,没有什么价值使用HDFS以及YARN,这两个都是为【更大】而服务的。
Hadoop伪分布式模式:在一台服务器节点上体验完整的Hadoop完全分布式的运作,方便人们学习。0-1,学会配置一台Hadoop服务器节点,那么你就有能力去配置N台。伪分布式除了只在一台服务器上跑完整的Hadoop项目功能,剩下基本相同,只是1和N之间的关系——全能细胞->专用已分化细胞。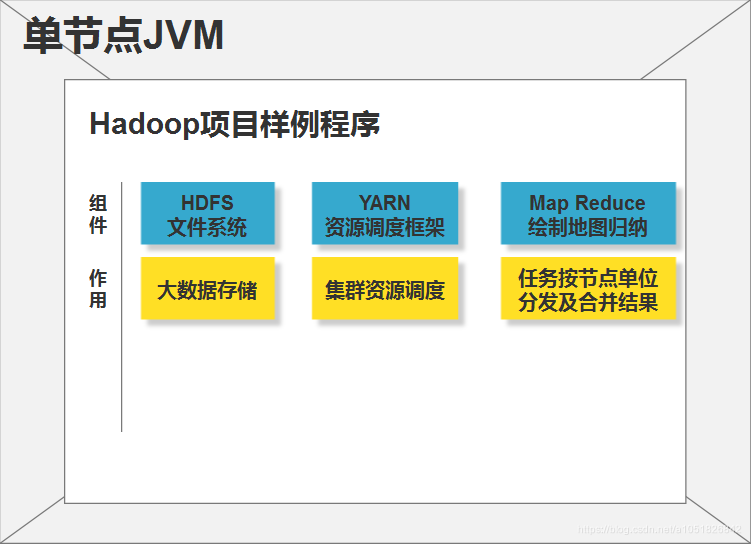
伪分布式与单节点模式是不能共通的,即是修改了$HADOOP_HOME/etc/hadoop/目录下的配置文件,就无法运行上一篇Hadoop单节点部署 Linux网络配置IP 主机名_2019.5.10中Hadoop部署单节点的测试和应用。
但伪分布式与完全分布式是一样的,只不过是所有的骨架都放在了一个服务器节点上——麻雀虽小五脏俱全。
需要注意的是:伪分布式也要在上一篇的基础上(Java安装及系统配置,Hadoop安装及系统配置),伪分布式只是修改了配置文件的内容,而已。
所有文件均在hadoop-2.7.2/etc/hadoophadoop根目录下的etc的hadoop子文件中。
本篇配置基本都是/opt/module/hadoop-2.7.2/etc/hadoop路径下的文件修改。
这个完整路径是怎么来的,可以参考上一篇 准备文档
所有配置文件具体条目解释均可在Hadoop Apache官网中找到。下列为快速传送门如果要修改为对应版本,直接改r2.x.x即可。
| Configuration | Link |
|---|---|
| core-default.xml | http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml |
| hdfs-default.xml | http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml |
| mapred-default.xml | http://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml |
| yarn-default.xml | http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml |
| Deprecated Properties | http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/DeprecatedProperties.html |
hadoop-env.sh的JAVA_HOME路径将/opt/module/hadoop-2.7.2/etc/hadoop中的hadoop-env.shJAVA_HOME
修改为:当前节点JAVA_HOME绝对路径,不使用${JAVA_HOME}
$ vim etc/hadoop/hadoop-env.sh
>>>
export JAVA_HOME=/opt/module/jdk1.8.0_144
缘由:Hadoop是daemon进程,用于后台non-interact监测管理, bash non-interactive 模式不会care关注 profile 。profile 是给 login shell (如 Ctrl+Alt+F[N] 或 ssh 登入 bash) 用的,也就是,hadoop-env.sh从根本不进入profile获取${JAVA_HOME},然而国内教程大部分都是直接修改/etc/profile文件,从Linux内核来说,这个姿势非正统。所以会导致该文件内的JAVA_HOME获取不到,导致项目报错。
参考:http://www.360doc.com/content/18/0420/08/11935121_747191062.shtml
core-site.xml<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop02:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
缘由:
1.fs.defaultFS指定NameNode地址,NameNode用于存储大数据集群的虚拟目录树等。
2.而hadoop.tmp.dir为什么要进行设定修改到/opt/module/hadoop-2.7.2/data/tmp,是因为hadoop的pid文件是默认保存在/tmp目录下的,Linux系统默认会定时去清理这个目录下的文件,所以是没有pid文件而找到关闭Hadoop进程(例如NameNode,DataNode进程)无法结束,你可以用$ jps命令查看到NameNode进程,但你无法使用Hadoop命令正常关闭NameNode。那么解决办法有3个,其中一个是关闭进程时采用$ kill -s 9 PID强制命令,第二个就是修改hadoop的hadoop-env.sh配置文件,修改HADOOP_PID_DIR的路径,而第三个,直接修改hadoop默认hadoop.tmp.dir目录就都解决了。这里我们采用修改hadoop.tmp.dir目录的方法。
hdfs-site.xml<!-- 指定HDFS副本的数量 -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
缘由:默认副本数量为3,自行选择。
注意:关于横杠-!这个很重要,别写成中文的,以及,禁止有多余的空格
[atguigu@hadoop02 hadoop-2.7.2]$ bin/hdfs namenode -format[atguigu@hadoop02 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode[atguigu@hadoop02 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode[atguigu@hadoop02 hadoop-2.7.2]$ jps
注1:关于Windows端被拒绝访问该网站,可用参考上篇文章,有关于防火墙服务的关闭部分。以及如果仍然不行,可考虑关闭关闭selinux,此设置我实验结果是无用
进入/etc/selinux/config文件$ sudo vim /etc/selinux/config
#SELINUX=enforcing
SELINUX=disabled
注2:关于NameNode第二次格式化后出现的问题【启动不了DataNode程序】
现象:启动DataNode命令,但JPS命令看不到DataNode进程
表因:Hadoop记录文件中datanode的clusterID 和 namenode的clusterID 不匹配
解决办法:删除core-site.xml配置的临时目录hadoop.tmp.dir因为上面的两个clusterID记录文件都在这个目录的子目录下,所以直接删除父目录hadoop.tmp.dir即可 == 恢复Hadoop出厂设置。【针对初学者而言】。关于日志目录$HADOOP_HOME/logs一并删除。
根本原因:NameNode二次初始化后,DataNode已存在,就不会联动产生新的DataNode配置文件,也就是DataNode配置不与NameNode联动更新。/tmp中文件还是上次联动NameNode初始化后文件DataNode进程启动产生的文件,所以会出现/tmp目录中datanode的clusterID 和 namenode的clusterID 不匹配。
如果,因某种原因不能以简单粗暴的恢复出厂设置来解决,请参考如下博客
cc19_简洁
love666666shen_详细
或者,如下进入如下目录进行查看修改 clusterID= 是否相同
[atguigu@hadoop02 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[atguigu@hadoop02 current]$ cat VERSION
[atguigu@hadoop02 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
[atguigu@hadoop02 current]$ cat VERSION
注意:修改配置前,一定先 kill -s 9 PID 相关进程
/opt/module/hadoop-2.7.2/logs[atguigu@hadoop02 logs]$ ls
hadoop-atguigu-datanode-hadoop02.log hadoop-atguigu-namenode-hadoop02.log
hadoop-atguigu-datanode-hadoop02.out hadoop-atguigu-namenode-hadoop02.out
SecurityAuth-atguigu.audit
[atguigu@hadoop02 logs]$ cat hadoop-atguigu-datanode-hadoop02.log
HDFS系统作为Hadoop项目数据源
当前目录:Hadoop.tar.gz解压后的目录——/opt/module/hadoop-2.7.2
1.创建HDFS虚拟统一目录 hdfs dfs -mkdir -p /路径$ bin/hdfs dfs -mkdir -p /user/atguigu/input
2.上传文件至HDFS文件系统 hdfs dfs -put 本地上传路径 虚拟目录路径$ bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
3.查看HDFS系统虚拟目录树hdfs dfs -ls 路径$ bin/hdfs dfs -ls /$ bin/hdfs dfs -lsr /现更改为$ bin/hdfs dfs -ls -R /查看所有目录递归查询
4.cat 查看HDFS虚拟目录树中的文件内容$ bin/hdfs dfs -cat /user/atguigu/input/wc.input
5.rm 删除HDFS虚拟目录树中的文件内容$ bin/hdfs dfs -rm -r /user/atguigu/output
应用HDFS作为数据来源,进行官方MapReduce测试WordCount案例$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input/ /user/atguigu/output
命令解析:bin/hadoop命令 以jar方式 运行share目录下的hadoop-mapreduce-examples-2.7.2.jar程序 功能函数为wordcount 输入目录 输出目录
执行成功后查询output目录下文件内容
[atguigu@hadoop02 bin]$ bin/hdfs dfs -cat /user/atguigu/input/wc.input
-bash: bin/hdfs: 没有那个文件或目录
[atguigu@hadoop02 bin]$ cd ..
[atguigu@hadoop02 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/atguigu/output/p*
"China 1
"I 1
"If 2
more
成功查询!注意:关于第一行-bash: bin/hdfs: 没有那个文件或目录失败的原因,是因为我进入了Hadoop根目录下的子目录bin目录,所以失败。一定在Hadoop根目录执行命令
如果执行Hadoop命令失败,请查询logs子目录下对应的datanodehadoop-atguigu-datanode-hadoop02.log或namenodehadoop-atguigu-namenode-hadoop02.log日志文件。
通过Yarn框架(ResourceManage/NodeManage)对MapReduce进行资源调度,也就是MapReduce将被Yarn管理。上面的例子,只是应用了HDFS文件系统,还算不上是伪分布式测试。只是单节点模式测试HDFS文件系统。
yarn-env.sh文件中JAVA_HOME路径将/opt/module/hadoop-2.7.2/etc/hadoop中的yarn-env.shJAVA_HOME
修改为:当前节点JAVA_HOME绝对路径
$ vim etc/hadoop/yarn-env.sh
>>>
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/module/jdk1.8.0_144
yarn-site.xml<configuration>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
</configuration>
mapred-env.sh将/opt/module/hadoop-2.7.2/etc/hadoop中的mapred-env.shJAVA_HOME
修改为:当前节点JAVA_HOME绝对路径
$ vim etc/hadoop/mapred-env.sh
>>>
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/module/jdk1.8.0_144
mapred-site.xml.template为 mapred-site.xml,并设定MR运行在YARN调度控制下。【该文件设定,可参看mapred.default.xml】mapreduce.framework.name设定值可为local/classic/yarn$ mv mapred-site.xml.template mapred-site.xml
$ vi mapred-site.xml
>>>
<configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
启动Yarn框架,对MapReduce进行调度测试
$ jps
115640 Jps
21596 NameNode
21693 DataNode
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ jps
125830 ResourceManager
126187 Jps
21596 NameNode
21693 DataNode
126140 NodeManager
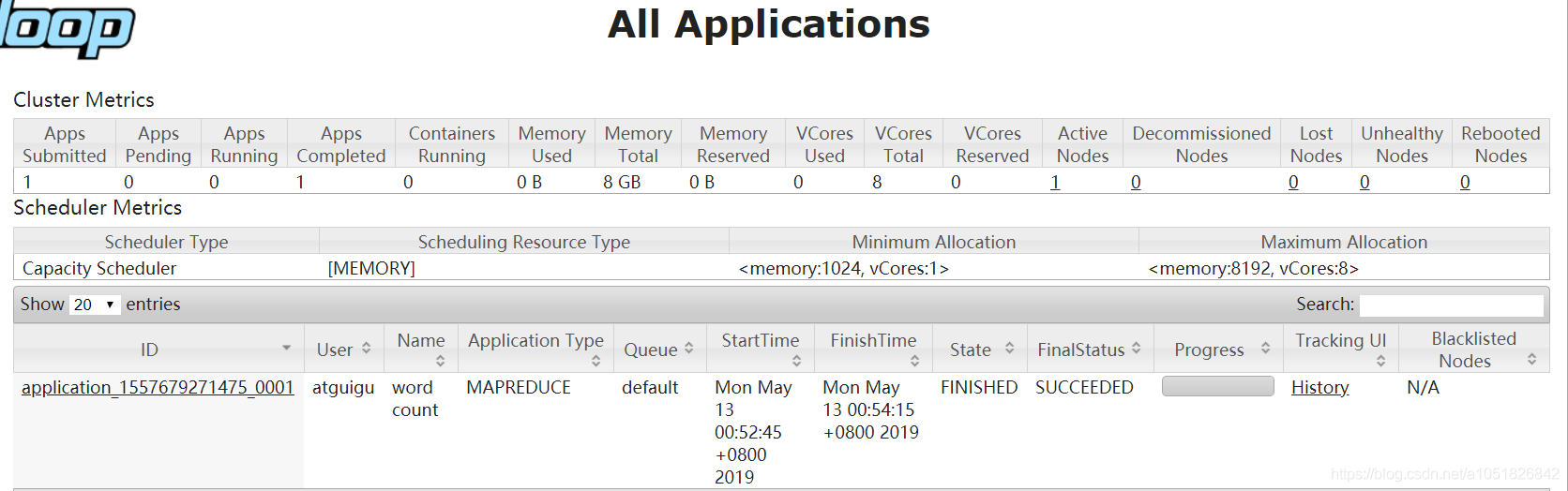
$ bin/hdfs dfs -rm -R /user/atguigu/output$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output配置mapred-site.xml设定文件$ vim mapred-site.xml
<configuration>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>
</configuration>
启动历史服务器$ sbin/mr-jobhistory-daemon.sh start historyserver
查看history服务是否启动$ jps
25552 JobHistoryServer
125830 ResourceManager
21596 NameNode
21693 DataNode
126140 NodeManager
25614 Jps
history任务历史服务器网页前端:http://hadoop02:19888/jobhistory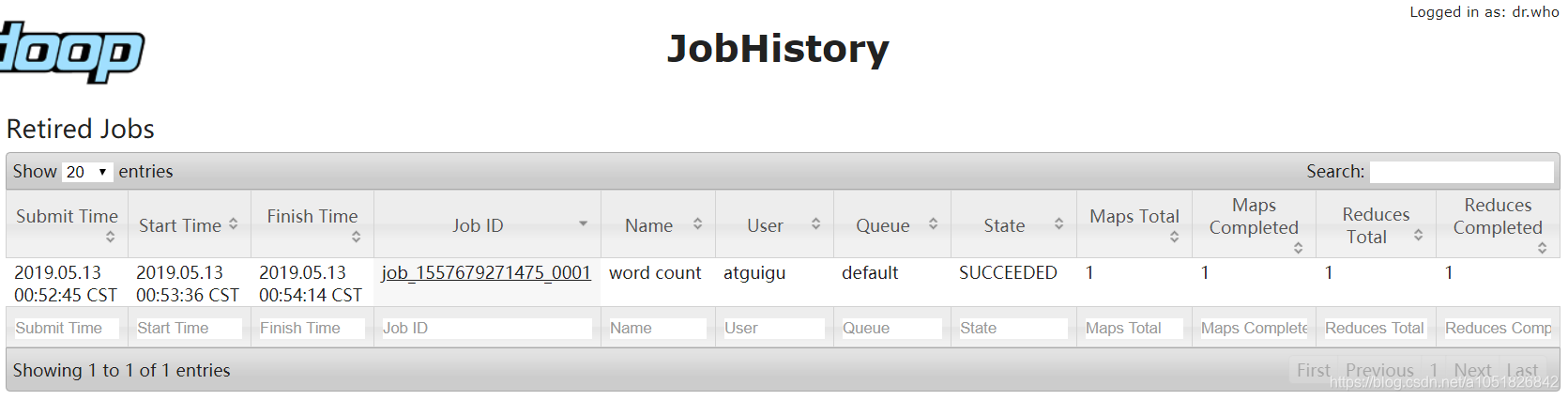
需要注意的,现在 history 记载文件是存储在 CentOS 7 本地文件系统中Hadoop项目根目录的Logs子文件中。
下面继续配置具体的程序运行日志【聚合Aggregation日志文件】上传至HDFS文件系统
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
配置yarn-site.xml设定文件$ vim yarn-site.xml
<configuration>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
关闭上述注意中提示的进程。
$ sbin/yarn-daemon.sh stop resourcemanager
$ sbin/yarn-daemon.sh stop nodemanager
$ sbin/mr-jobhistory-daemon.sh stop historyserver
$ jps
21596 NameNode
21693 DataNode
44445 Jps
再启动上述3个进程
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver
$ jps
46099 Jps
45718 ResourceManager
45801 NodeManager
46041 JobHistoryServer
21596 NameNode
21693 DataNode
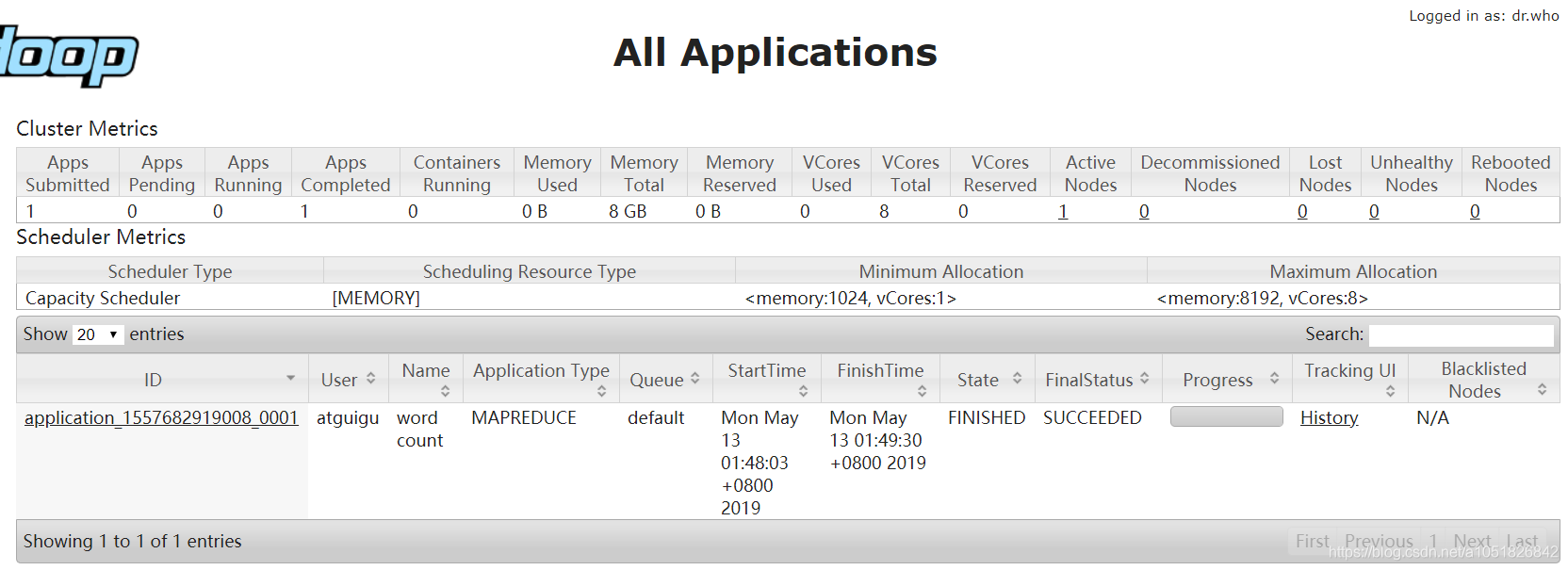
重新运行样例程序,进行Yarn框架功能测试
$ bin/hdfs dfs -rm -R /user/atguigu/output$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output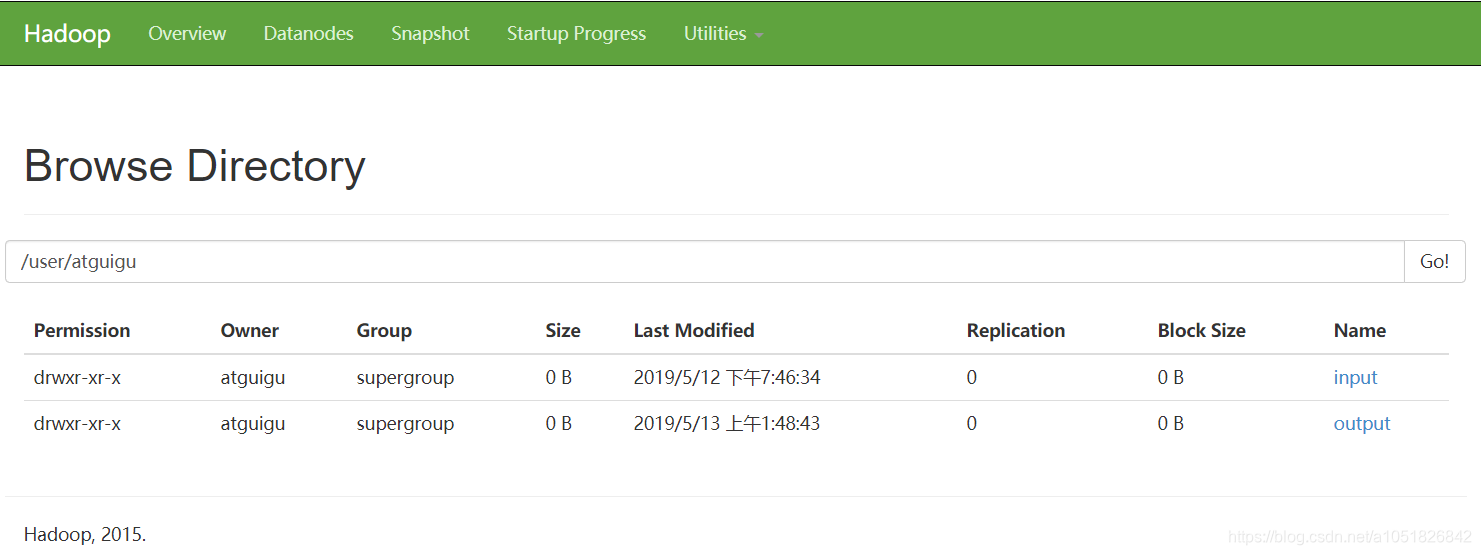

从4月26日,到5月12日……时间确实有点久了,半个月才看到伪分布式。整理前面所学的倒是费了不少时间,emmm艰难求职费了几天,算下来,大概18天刨掉生病面试请客吃饭毕设中期报告,还剩下10天,emmm进度还是慢…这样下去没饭吃哦。
值得庆幸的是,心态调整过来了,身体也恢复了,伪分布式也初步完成基础牢靠。
Hadoop完整思想理解的也差不多了,剩下就是继续学习细节,了解真正大数据面临的问题以及解决方案。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
