社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
1、JDK 下载
http://www.oracle.com/technetwork/java/javase/downloads/index.html
2、Hadoop 下载
http://hadoop.apache.org/releases.html
创建 hadoop 用户,并分配以用户名为家目录/home/hadoop,并将其加入到sudo用户组,创建好用户之后,以 hadoop 用户登录:
sudo useradd -m hadoop -s /bin/bash
sudo adduser hadoop sudo
sudo passwd hadoop # 设置hadoop用户密码安装,解压 JDK 到/usr/lib/java/路径下,Hadoop 到/usr/local/etc/hadoop/路径下:
tar zxf ./hadoop-2.6.*.tar.gz
mv ./hadoop-2.6.* /usr/local/etc/hadoop # 将 /usr/local/etc/hadoop作为Hadoop的安装路径解压完成之后,可验证 hadoop 的可用性:
cd /usr/local/etc/hadoop
./bin/hadoop version # 查看hadoop的版本信息配置环境,编辑 “/etc/profile” 文件,在其后添加如下信息:
export HADOOP_HOME=/usr/local/etc/hadoop
export JAVA_HOME=/usr/lib/java/jdk1.8.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin使配置的变量生效:
source /etc/profile在此我们可以运行一个简单的官方 Demo:
cd `echo $HADOOP_HOME` # 到hadoop安装路径
mkdir ./input
cp ./etc/hadoop/*.xml ./input
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'什么是伪分布式?Hadoop 伪分布式模式是在一台机器上模拟 Hadoop 分布式,单机上的分布式并不是真正的分布式,而是使用线程模拟的分布式。分布式和伪分布式这两种配置也很相似,唯一不同的地方是伪分布式是在一台机器上配置,也就是名字节点(namenode)和数据节点(datanode)均是同一台机器。
需要配置的文件有core-site.xml和hdfs-site.xml这两个文件他们都位于${HADOOP_HOME}/etc/hadoop/文件夹下。
其中core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/ylf/hadoop_tmp</value>
</property>
</configuration>修改 hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ylf/hadoop/dfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ylf/hadoop/dfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.http.address</name>
<value>localhost:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>修改 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/ylf/hadoop/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/home/ylf/hadoop/mapred/local</value>
<final>true</final>
</property>
</configuration>修改 yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>shuffle service that needs to be set for Map Reduce to run</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description>hostname of Resource Manager</description>
</property>
</configuration>格式化 hdfs
进入 hadoop home 目录
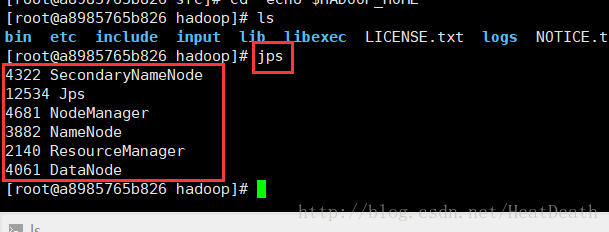
bin/hdfs namenode -format启动集群
sbin/start-all.sh输入 jps 指令查看进程
启动 HDFS 的脚本位于 Hadoop 目录下的sbin文件夹中,即:
cd `echo $HADOOP_HOME`
./sbin/start-dfs.sh # 启动HDFS脚本在执行start-dfs.sh脚本启动 HDFS 时,可能出现类似如下的报错内容:
localhost: Error: JAVA_HOME is not set and could not be found.
很明显,是JAVA_HOME没找到,这是因为在hadoop-env.sh脚本中有个 JAVA_HOME=${JAVA_HOME},所以只需将${JAVA_HOME}替换成你的 JDK 的路径即可解决:
echo $JAVA_HOME # /usr/lib/java/jdk1.*.*_**
vim ./etc/hadoop/hadoop-env.sh # 将‘export JAVA_HOME=${JAVA_HOME}’字段替换成‘export JAVA_HOME=/usr/lib/java/jdk1.*.*_**’即可再次执行
`echo $HADOOP_HOME`/sbin/start-all.sh可以执行以下命令判断是否启动:
jps对应的启动,自然也有关闭咯:
`echo $HADOOP_HOME`/sbin/stop-dfs.sh以上的 “四、测试一下” 只是使用的是本机的源生文件运行的测试 Demo 实例。既然搭建好了伪分布式的环境,那就使用分布式上存储(HDFS)的数据来进行一次 Demo 测试:
先将数据源搞定,也就是仿照 “四” 中的 Demo 一样,新建一个文件夹作为数据源目录,并添加一些数据:
hdfs dfs -mkdir /input # 这里的文件名必须要以‘/’开头,暂时只了解是hdfs是以绝对路径为基础,因为没有 ‘-cd’这样的命令支持
hdfs dfs -put `echo $HADOOP_HOME`/etc/hadoop/*.xml /input也可以查看此时新建的input目录里面有什么:
hdfs dfs -ls /
hdfs dfs -ls /input 再次运行如之前运行的那个 Demo
hadoop jar /usr/local/etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'再次查看 HDFS 中的目录:
hdfs dfs -ls /
hdfs dfs -cat /output*1、Hadoop 学习笔记 - Hadoop HDFS 环境搭建
http://blog.csdn.net/u012342408/article/details/50520696
2、Ubuntu 上搭建 Hadoop 环境(单机模式 + 伪分布模式)
http://blog.csdn.net/hitwengqi/article/details/8008203
3、# 从零开始搭建 Hadoop2.7.1 的分布式集群
http://blog.csdn.net/zl007700/article/details/50533675
4、linux 上 hadoop2.4.0 安装配置
https://www.cnblogs.com/yanglf/p/4020555.html
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!