社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
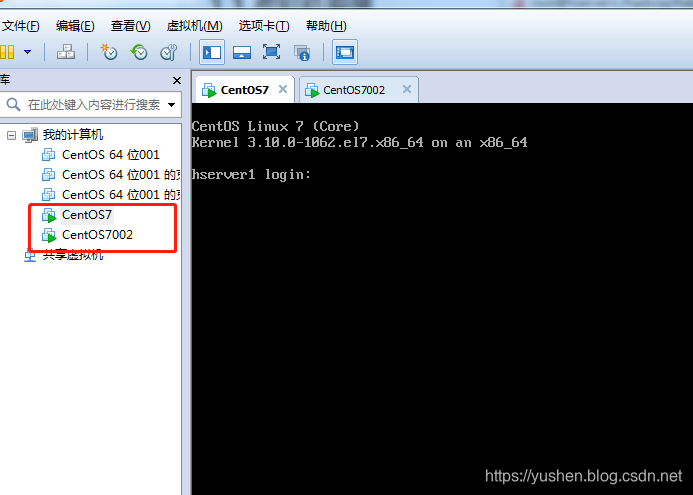
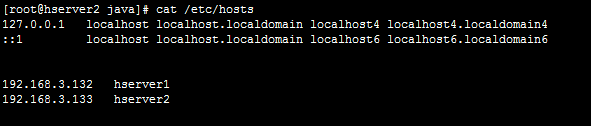
改成上边这个,然后测试ping一下 看是否通
一路回车,后会在~/.ssh中生成文件
俩台机器都执行这个
然后
把俩个机器的公钥都拷贝到 一个新文件中文件名叫 authorized_keys
这个文件俩个电脑都放一下 这样ssh 链接 就ok了 如果没做过就从网上找例子吧非常多
测试联通ssh
进去就ok了
检测是否已经有安装的了,有的话就卸载掉,卸载命令如下 或从网上查下
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepsjava-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodepsjava-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
rpm -e --nodepsjava-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
从网上下载jdk
然后解压
export JAVA_HOME=/java/jdk1.8.0_192
export JRE_HOME=$JRE_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export HADOOP_HOME=/hadoop/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:HADOOP_HOME/sbin:$PATH
查看是否生效
重要
以下步骤在hserver1和hserver2都需要做一遍
mkdir -p /hadoop
mkdir -p /hadoop/tmp
mkdir -p /hadoop/var
mkdir -p /hadoop/dfs
mkdir -p /hadoop/dfs/name
mkdir -p /hadoop/dfs/data
http://hadoop.apache.org/releases.html
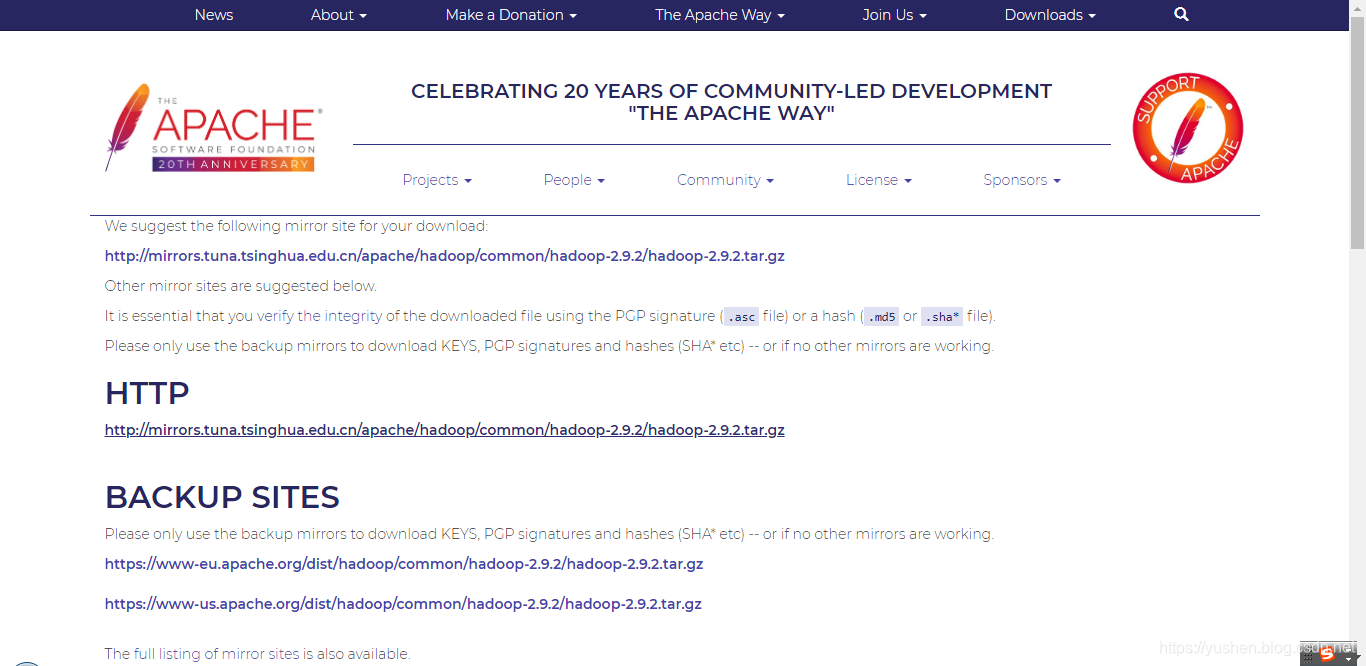
放到 /hadoop目录下
打开文件:vim /opt/hadoop/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
然后使环境变量生效,执行:
source /opt/hadoop/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
打开文件:vim /opt/hadoop/hadoop-2.9.2/etc/hadoop/slaves
将里面的localhost删除,添加hserver2。
hserver2
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml
在<configuration></configuration>之间添加配置参数如下:
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hserver1:9000</value>
</property>
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
在<configuration></configuration>之间添加配置参数如下:
<property>
<name>dfs.name.dir</name>
<value>/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
在/opt/hadoop/hadoop-2.9.0/etc/hadoop/中没有mapred-site.xml文件,但可以通过复制mapred-site.xml. template文件重命名为mapred-site.xml,再进行修改。在<configuration></configuration>之间添加配置参数如下:
<property>
<name>mapred.job.tracker</name>
<value>hserver1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
打开文件:vim /opt/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
内存根据机器配置越大越好,更具自己服务器情况配置
在<configuration></configuration>之间添加配置参数如下:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hserver1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
这里也可以拷贝吧hadoop 拷贝到 另一台服务器
可以执行
现在hserver1是namenode,hserver3是datanode,只需要在hserver1上进行初始化及启动操作。
首先进入namenode格式化命令所在目录:
[root@hserver1 hadoop]#cd /opt/hadoop/hadoop-2.9.0/bin
然后执行namenode格式化命令:
[root@hserver1bin]# ./hadoop namenode –format
跳出如下信息说明初始化成功:
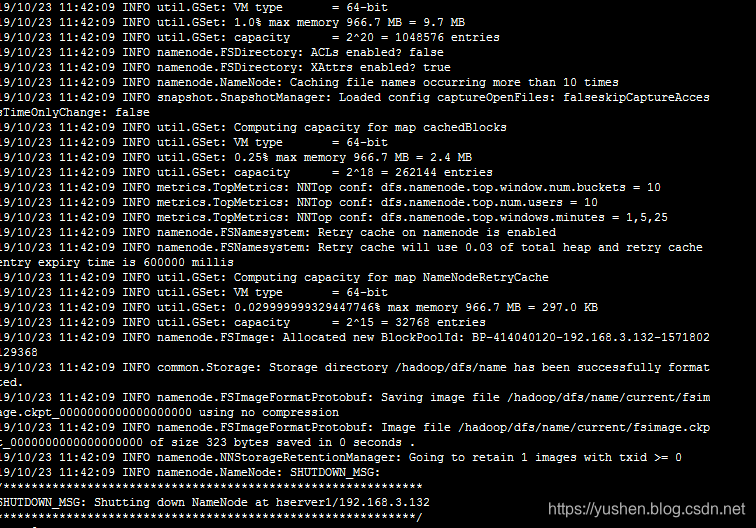
进入到启动命令文件夹:
[root@hserver1bin]# cd /opt/hadoop/hadoop-2.9.0/sbin
启动dfs和yarn:
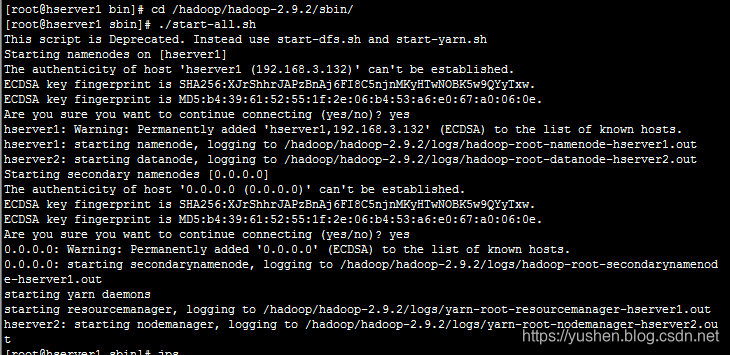
[root@hserver1bin]#./start-all.sh
启动成功后会看到以下信息:
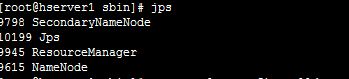
输入jps可以看到如下信息:
首先关闭防火墙:
[root@hserver1sbin]# systemctl stop firewalld
接下来访问hadoop管理首页,hserver1的IP是192.168.3.132,因此访问:
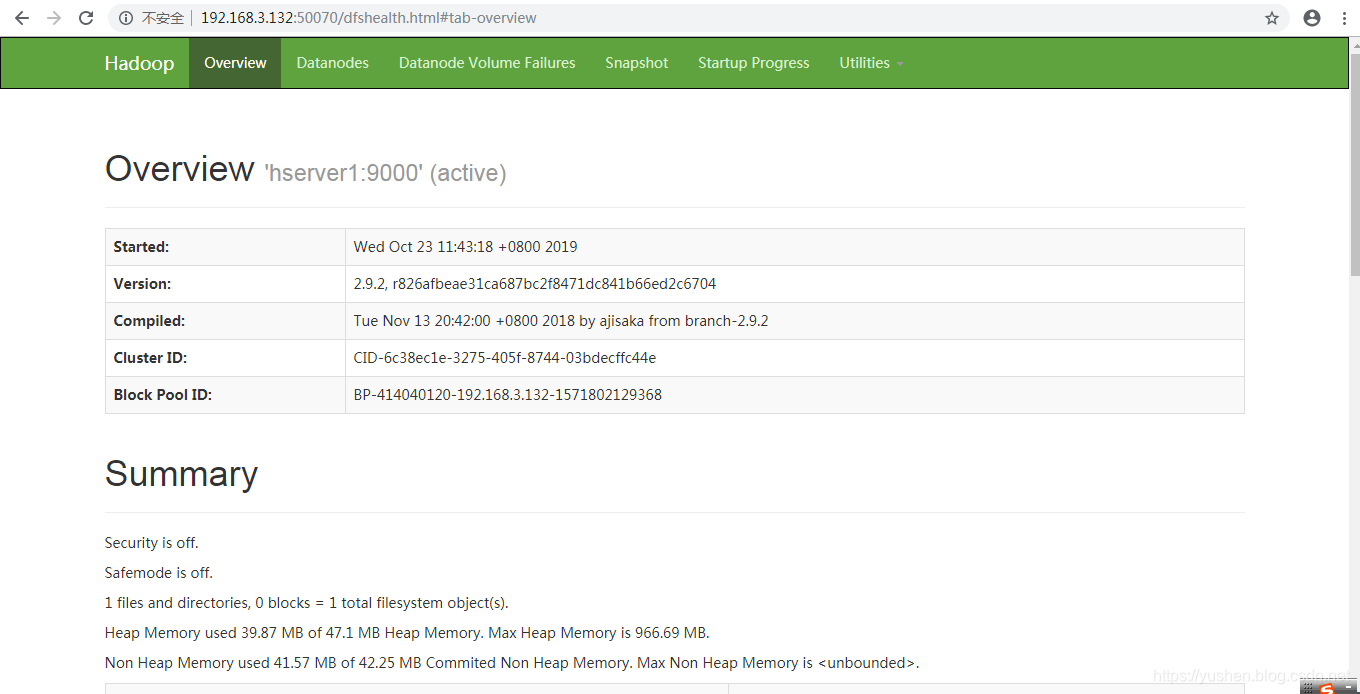
在本地浏览器里访问如下地址:
自动跳转到了cluster页面
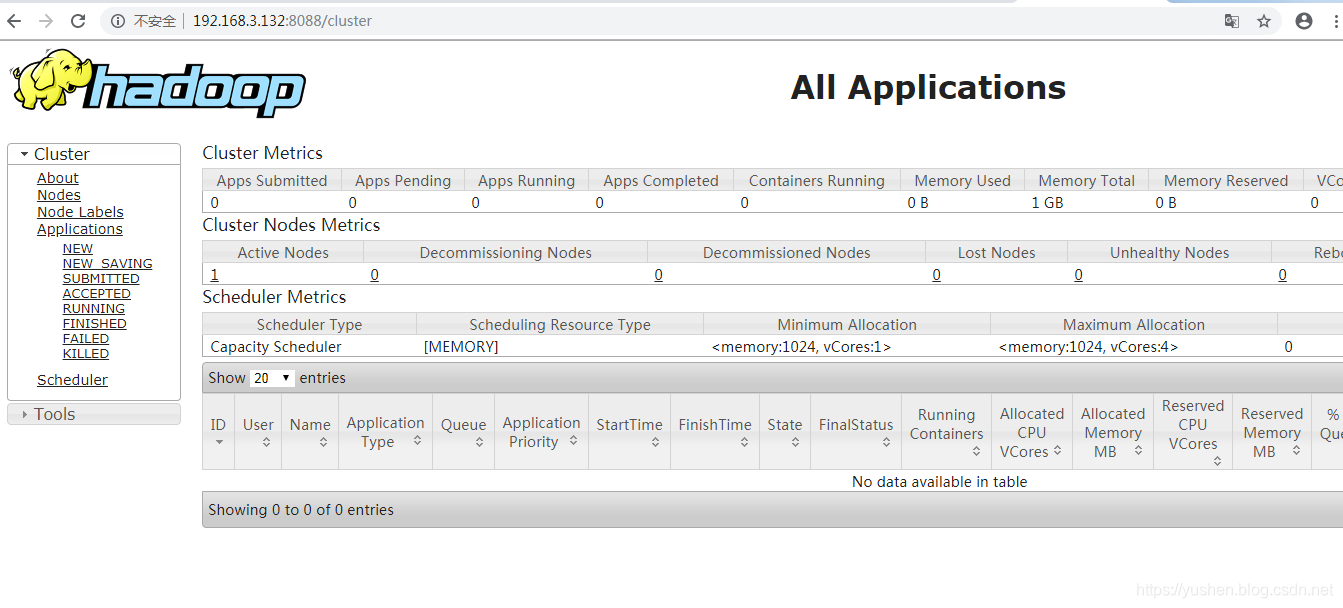
出现如下 及ok了
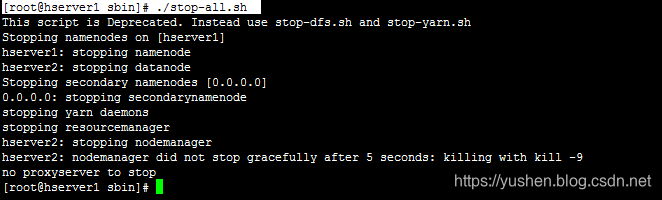
到这里就说明ok了
ok
持续更新
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
