
by Dave Cheney
概观
本次研讨会的目标是为您提供诊断Go应用程序中的性能问题并进行修复所需的工具。
通过这一天,我们将从小工作 - 学习如何编写基准,然后分析一小段代码。然后走出去讨论执行跟踪器,垃圾收集器和跟踪运行的应用程序。剩下的时间将是您提出问题的机会,并尝试使用您自己的代码。
|
您可以在此处找到此演示文稿的最新版本 |
欢迎
你好,欢迎光临!?
本次研讨会的目标是为您提供诊断Go应用程序中的性能问题并进行修复所需的工具。
通过这一天,我们将从小工作 - 学习如何编写基准,然后分析一小段代码。然后走出去讨论执行跟踪器,垃圾收集器和跟踪运行的应用程序。剩下的时间将是您提出问题的机会,并尝试使用您自己的代码。
教师
-
戴夫·切尼dave@cheney.net
先决条件
这是您今天需要的几个软件下载。
研讨会资料库
将源代码下载到本文档并在https://github.com/davecheney/high-performance-go-workshop上编写代码示例
的Graphviz
关于pprof的部分要求dot程序随graphviz工具套件一起提供。
-
Linux的:
[sudo] apt-get install graphviz -
OSX:
-
MacPorts的:
sudo port install graphviz -
macx:
brew install graphviz -
Windows(未经测试)
您自己的代码来分析和优化
当天的最后一部分将是一个开放式会议,您可以在其中试验您学到的工具。
1.微处理器性能的过去,现在和未来
这是一个关于编写高性能代码的研讨会。在其他研讨会上,我谈到了解耦设计和可维护性,但我们今天在这里谈论性能。
我想今天开始简短的讲座,讲述我如何看待计算机发展的历史,以及为什么我认为编写高性能软件很重要。
现实情况是软件在硬件上运行,所以谈到编写高性能代码,首先我们需要讨论运行代码的硬件。
1.1。理解机械

目前有一个流行的术语,你会听到Martin Thompson或Bill Kennedy等人谈论“机械上的理解”。
“机械理解”这个名字来自伟大的赛车手杰基斯图尔特,他是世界一级方程式赛车冠军的3倍。他相信最好的车手对机器如何工作有足够的了解,因此他们可以与之协调工作。
要成为一名优秀的赛车手,你不需要成为一名出色的机械师,但你需要对马车的工作方式有一个粗略的了解。
我相信我们作为软件工程师也是如此。我认为这个会议室里的任何人都不会成为专业的CPU设计师,但这并不意味着我们可以忽略CPU设计人员面临的问题。
1.2。六个数量级
有一个常见的互联网模因,就像这样;

当然这是荒谬的,但它强调了计算行业的变化。
作为软件作者,我们这个房间里的所有人都受益于摩尔定律,40年来,芯片每18个月可用晶体管数量翻了一番。没有其他行业在一生的空间中经历了六个数量级的工具改进[ 1 ]。
但这一切都在改变。
1.3。电脑还在变快吗?
因此,基本问题是,面对上图中的统计数据,我们应该问的问题是计算机是否仍然变得更快?
如果计算机仍然变得越来越快,那么我们可能不需要关心代码的性能,我们只需稍等一下,硬件制造商将为我们解决性能问题。
1.3.1。我们来看看数据
这是您在教科书中找到的经典数据,如计算机体系结构, John L. Hennessy和David A. Patterson的定量方法。该图取自第5版
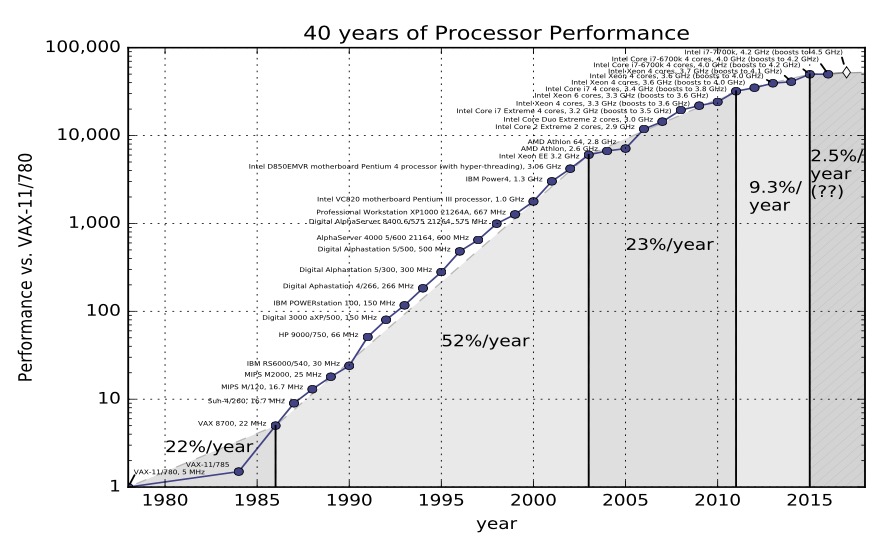
在第5版中,Hennessey和Patterson认为计算性能有三个时代
-
第一个是1970年代和80年代初,这是形成时期。我们今天所知的微处理器并不存在,计算机是用分立晶体管或小规模集成电路构建的。成本,规模和对材料科学理解的限制是限制因素。
-
从80年代中期到2004年,趋势线很明显。计算机整数性能平均每年提高52%。计算机功率每两年翻一番,因此人们将摩尔定律与计算机性能相加,即模具上晶体管数量增加一倍。
-
然后我们来到计算机性能的第三个时代。改进变慢了。总变化率为每年22%。
之前的图表仅上升到2012年,但幸运的是在2012年,Jeff Preshing编写了一个工具来抓取Spec网站并构建自己的图表。
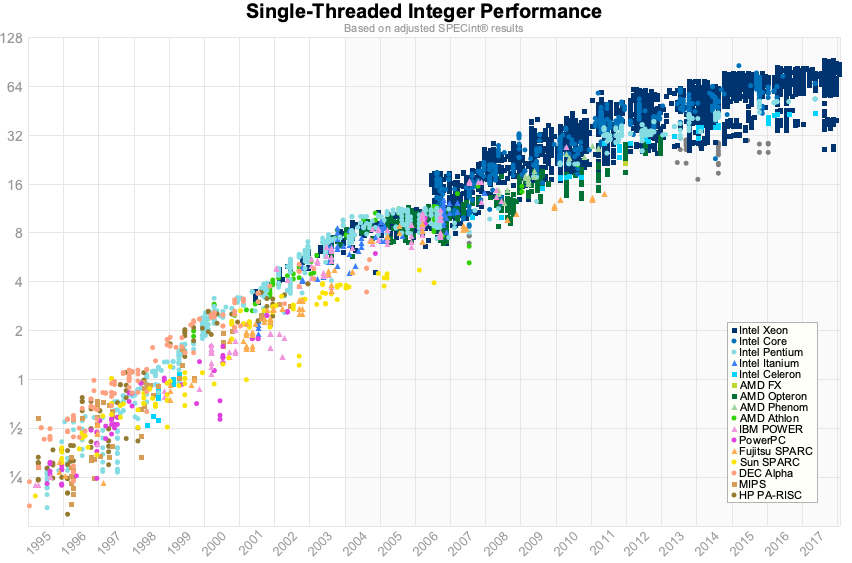
所以这是使用1995年至2017年的Spec数据的相同图表。
对我来说,不是我们在2012年的数据中看到的阶段变化,而是说单核心性能接近极限。对于浮点数而言,这些数字略好一些,但对于我们在会议室中进行业务线应用程序而言,这可能并不相关。
1.3.2。是的,电脑仍然变得越来越快
关于摩尔定律结束的第一件事就是戈登摩尔告诉我的事情。他说“所有指数都结束了”。- 约翰轩尼诗
这是轩尼诗引用Google Next 18和他的图灵奖演讲。他的论点是肯定的,CPU性能仍在提高。但是,单线程整数性能仍在每年提高2-3%左右。按此速度,它将需要20年的复合增长才能达到整数表现。相比之下,90年代的表现每两年增加一倍。
为什么会这样?
1.4。时钟速度
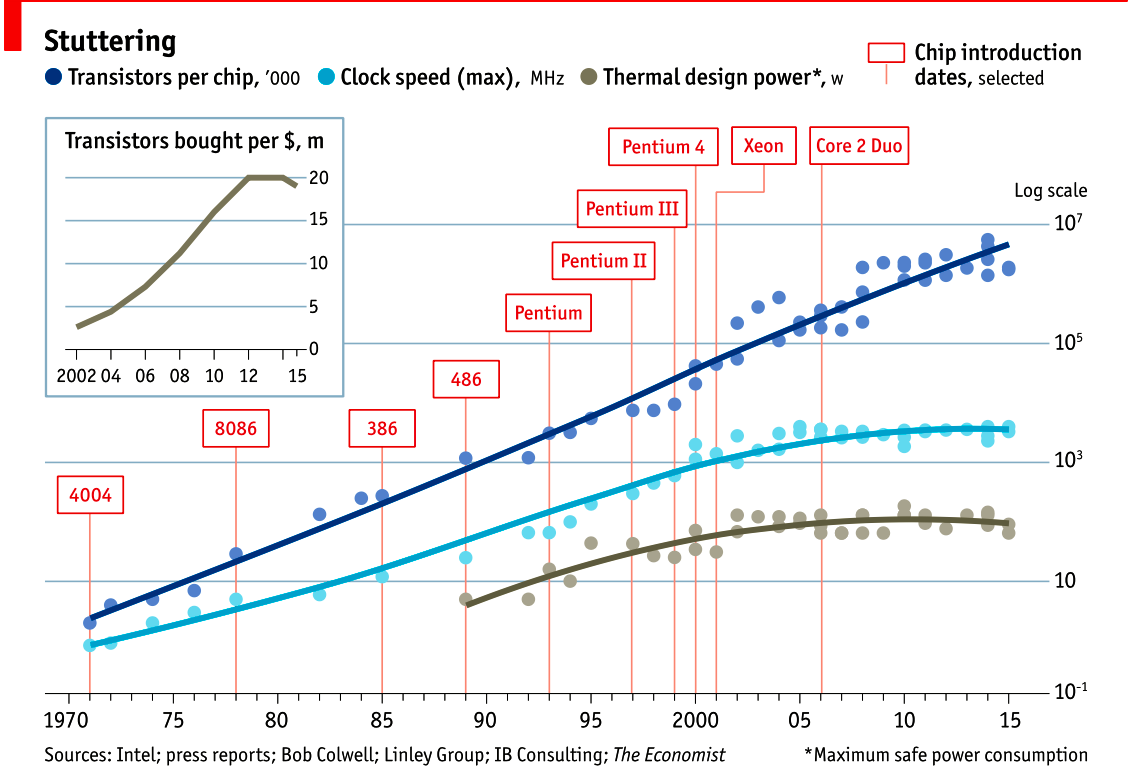
2015年的图表很好地证明了这一点。顶行显示了芯片上的晶体管数量。自1970年代以来,这一趋势在一个大致线性的趋势线上继续。由于这是log / lin图,因此该线性系列代表指数增长。
然而,如果我们看一下中间线,我们看到时钟速度在十年内没有增加,我们看到cpu速度在2004年左右停滞不前
下图显示了散热功率; 即电能变成热量,遵循相同的模式 - 时钟速度和cpu散热是相关的。
1.5。热量
为什么CPU产生热量?它是一个固态设备,没有移动组件,所以摩擦等效果在这里并没有(直接)相关。
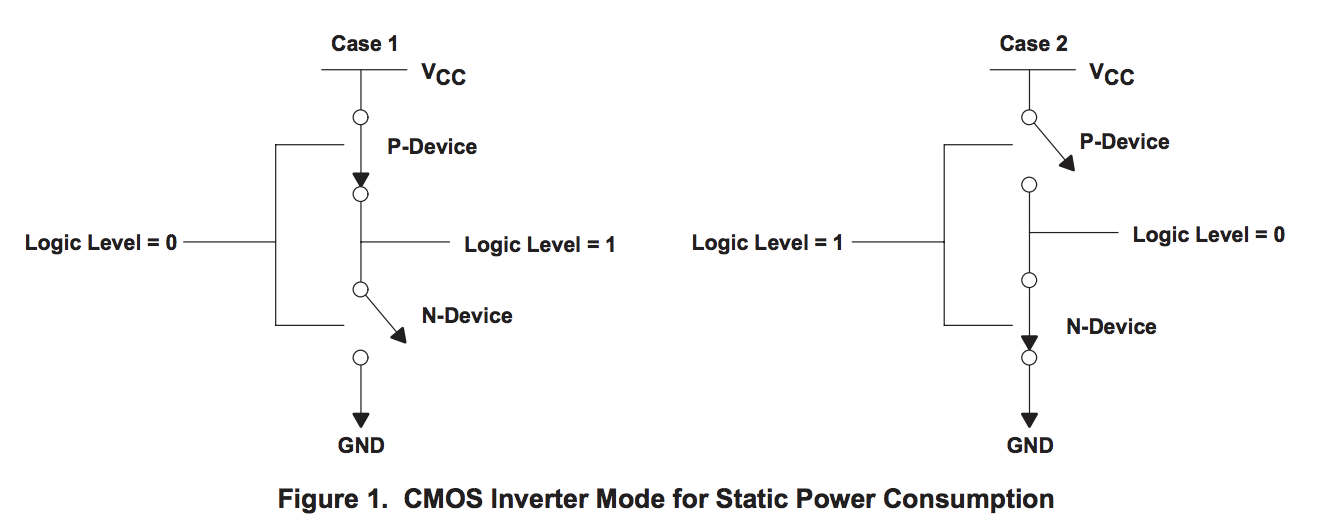
CMOS器件的功耗,就是这个房间里的每个晶体管,桌面和口袋里的三个因素的组合。
-
静电。当晶体管静止时,即不改变其状态时,有少量电流通过晶体管泄漏到地。晶体管越小,泄漏越多。泄漏随温度升高而增加。当你拥有数十亿个晶体管时,即使是少量的泄漏也会增加!
-
动力。当晶体管从一种状态转换到另一种状态时,它必须对连接到栅极的各种电容充电或放电。每个晶体管的动态功率是电容的平方乘以电容和变化的频率。降低电压可以降低晶体管消耗的功率,但是较低的电压会导致晶体管切换较慢。
-
撬棍或短路电流。我们喜欢将晶体管视为数字设备占据一个或另一个状态,原子地关闭或打开。实际上,晶体管是模拟器件。作为开关,晶体管大部分开始关断,并且转换或切换到大部分开启的状态。这种转换或切换时间非常快,在现代处理器中它的速度为皮秒,但仍然代表从Vcc到地的低电阻路径的一段时间。晶体管开关越快,其频率越高,散热量就越大。
1.6。Dennard缩放的结束
为了理解接下来发生的事情,我们需要查看1974年由Robert H. Dennard共同撰写的论文。Dennard的Scaling定律大致指出随着晶体管变小,它们的功率密度保持不变。较小的晶体管可以在较低的电压下运行,具有较低的栅极电容,并且开关速度更快,这有助于减少动态功率。
那怎么办呢?
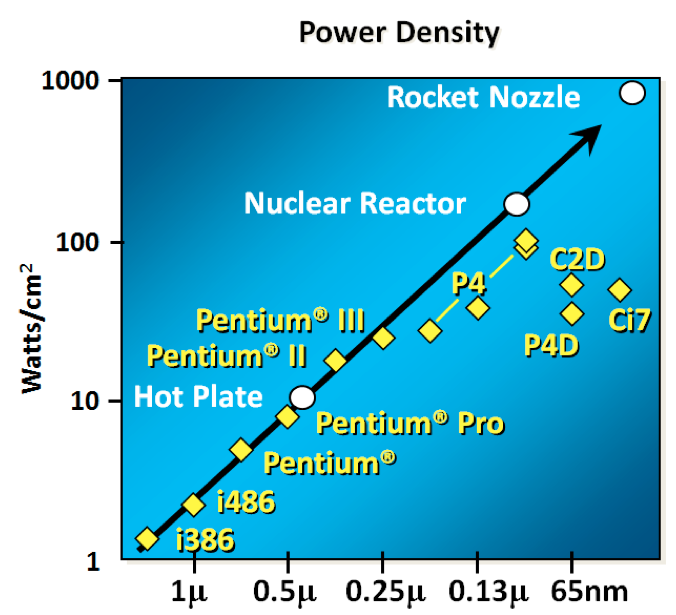
结果并不那么好。随着晶体管的栅极长度接近几个硅原子的宽度,晶体管尺寸,电压和重要的泄漏之间的关系被破坏。
在1999年的Micro-32会议上假设,如果我们遵循时钟速度增加和晶体管尺寸缩小的趋势线,那么在处理器生成中,晶体管结将接近核反应堆核心的温度。显然这是疯狂的。奔腾4 标志着单核,高频,消费类CPU 的终结。
回到这个图表,我们看到时钟速度停滞的原因是因为cpu超出了我们冷却它们的能力。到2006年,减小晶体管的尺寸不再提高其功率效率。
我们现在知道降低CPU特征尺寸主要是为了降低功耗。降低能耗并不仅仅意味着“绿色”,就像回收一样,拯救地球。主要目标是将功耗和热耗散保持在低于损坏CPU的水平。
但是,图表的一部分仍在继续增加,即芯片上的晶体管数量。cpu的行进特征是在相同的给定区域中具有更大的晶体管,具有正面和负面效果。
此外,正如您在插页中看到的那样,每个晶体管的成本持续下降,直到大约5年前,然后每个晶体管的成本开始再次回升。

创建更小的晶体管不仅成本越来越高,而且越来越难。2016年的这份报告显示了2013年芯片制造商认为会发生什么的预测; 两年后,他们错过了所有的预测,虽然我没有这份报告的更新版本,但没有迹象表明他们能够扭转这种趋势。
英特尔,台积电,AMD和三星花费数十亿美元,因为他们必须建立新的晶圆厂,购买所有新的工艺工具。因此,虽然每个芯片的晶体管数量持续增加,但其单位成本已开始增加。
|
甚至术语门长度(以纳米为单位)也变得模棱两可。各种制造商以不同的方式测量晶体管的尺寸,使其能够展示比竞争对手更小的数量,而无需提供。这是CPU制造商的非GAAP收益报告模型。 |
1.7。更多核心(more cores)

由于达到了热量和频率限制,因此不再能够使单核运行速度提高两倍。但是,如果添加其他内核,则可以提供两倍的处理能力 - 如果软件可以支持它。
实际上,CPU的核心数量主要是散热。Dennard缩放的结束意味着CPU的时钟速度是1到4 Ghz之间的任意数字,具体取决于它的热度。当我们谈论基准测试时,我们会很快看到这一点。
1.8。阿姆达尔定律
CPU不会变得越来越快,但随着超线程和多核的发展,它们的范围越来越广。移动部件上的双核,桌面部件上的四核,服务器部件上的数十个核心。这将成为计算机性能的未来吗?不幸的是。
Amdahl定律以IBM / 360的设计者Gene Amdahl命名,是一个公式,它给出了在固定工作负载下执行任务的延迟的理论加速,这可以预期资源得到改善的系统。

Amdahl定律告诉我们,程序的最大加速时间受程序的连续部分的限制。如果编写一个程序,其95%的执行能够并行运行,即使有数千个处理器,程序执行的最大加速也限制为20倍。
想想你每天工作的程序,他们的执行程序有多少是可以分开的?
1.9。动态优化
随着时钟速度的停滞以及在问题上抛出额外核心的回报有限,加速从何而来?它们来自芯片本身的架构改进。这些是具有Nehalem,Sandy Bridge和Skylake等名称的五到七年大型项目。
在过去二十年中,性能的大部分提升来自于体系结构的改进:
1.9.1。乱序执行
乱序,也称为超标量,执行是一种从CPU执行的代码中提取所谓的指令级并行性的方法。现代CPU在硬件级别有效地执行SSA以识别操作之间的数据依赖性,并且在可能的情况下并行地运行独立指令。
但是,任何一段代码中固有的并行数量都是有限的。它也非常耗电。大多数现代CPU已经确定每个核心有六个执行单元,因为在管道的每个阶段都有一个n平方成本将每个执行单元连接到所有其他执行单元。
1.9.2。投机执行
保存最小的微控制器,所有CPU利用指令流水线重叠指令获取/解码/执行/提交周期中的部分。
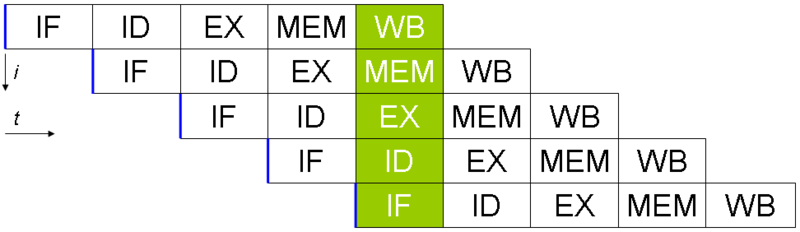
指令流水线的问题是分支指令,平均每5-8条指令发生一次。当CPU到达分支时,它无法查看分支以外的其他指令来执行,并且它无法开始填充其管道,直到它知道程序计数器也将分支到何处。推测执行允许CPU“猜测” 分支指令仍在处理时分支将采用哪条路径!
如果CPU正确预测分支,那么它可以保持其指令管道满。如果CPU无法预测正确的分支,那么当它意识到错误时,它必须回滚对其架构状态所做的任何更改。由于我们都在学习Spectre风格的漏洞,有时这种回滚并不像希望的那样无缝。
当分支预测率低时,推测执行可能非常耗电。如果分支是错误预测的,那么CPU不仅必须回溯到错误预测的点,而且浪费在错误分支上的能量。
所有这些优化都导致了我们所见的单线程性能的提高,代价是大量的晶体管和功率。
| Cliff Click有一个精彩的演示文稿,它不按顺序进行,而且推测性执行对于尽早启动缓存未命中非常有用,从而减少了观察到的缓存延迟。 |
1.10。现代CPU针对批量操作进行了优化
现代处理器就像硝基燃料的有趣汽车,它们在四分之一英里表现出色。不幸的是,现代编程语言就像蒙特卡罗,它们充满了曲折。 - 大卫Ungar
引自David Ungar,一位有影响力的计算机科学家和SELF编程语言的开发人员,我在网上找到了一个非常古老的演示文稿。
因此,现代CPU针对批量传输和批量操作进行了优化。在每个级别,操作的设置都会鼓励您批量工作。一些例子包括
-
内存不是每个字节加载,而是每多个缓存行加载,这就是为什么对齐变得比以前的计算机更少的问题。
-
像MMX和SSE这样的向量指令允许单个指令同时针对多个数据项执行,前提是您的程序可以以该形式表示。
1.11。现代处理器受内存延迟而非内存容量的限制
如果CPU的情况不够糟糕,那么来自房子内存方面的消息就不会好多了。
连接到服务器的物理内存几何增加。我在1980年代的第一台计算机有千字节的内存。当我上高中的时候,我写的所有论文都是386,有1.8兆字节的公羊。现在,它常常找到具有数十或数百GB RAM的服务器,而云提供商正在推动数TB的内存。

但是,处理器速度和内存访问时间之间的差距仍在继续增长。
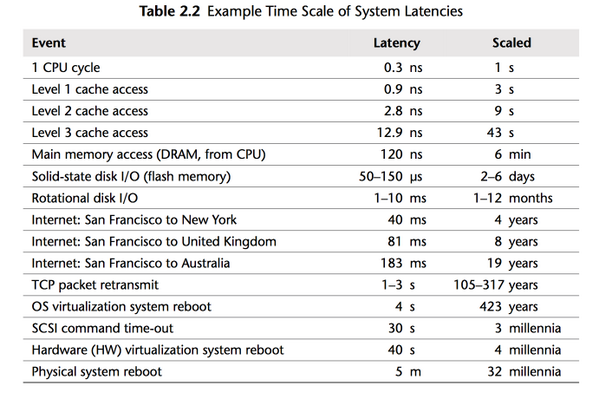
但是,就等待内存而丢失的处理器周期而言,物理内存仍然遥不可及,因为内存跟不上CPU速度的增长。
因此,大多数现代处理器都受到内存延迟而非容量的限制。
1.12。缓存规则我周围的一切

几十年来,处理器/内存上限的解决方案是添加一个缓存 - 一块靠近CPU的小型快速内存,现在直接集成到CPU上。
但;
-
几十年来,L1一直停留在每核心32kb
-
L2在最大的英特尔部分上缓慢爬升至512kb
-
L3现在在4-32mb范围内测量,但其访问时间是可变的

1.13。免费午餐结束了
2005年,C ++委员会领导人Herb Sutter撰写了一篇题为“免费午餐结束”的文章。在他的文章中,Sutter讨论了我所涵盖的所有要点,并断言未来的程序员将不再能够依赖更快的硬件来修复慢速程序或减慢编程语言。
现在,十多年后,毫无疑问Herb Sutter是对的。内存很慢,缓存太小,CPU时钟速度倒退,而单线程CPU的简单世界早已不复存在。
摩尔定律仍然有效,但对于我们这个房间里的所有人来说,免费午餐已经结束了。
1.14。结论
我要引用的数字将是2010年:30GHz,100亿个晶体管和每秒1个tera指令。- 英特尔首席技术官Pat Gelsinger,2002年4月
很明显,如果没有材料科学的突破,那么回归到CPU性能同比增长52%的日子的可能性就会非常小。共同的共识是,错误不在于材料科学本身,而在于如何使用晶体管。以硅表示的顺序指令流的逻辑模型导致了这种昂贵的终结。
网上有很多演示文稿重申了这一点。他们都有相同的预测 - 未来的计算机将不会像今天这样编程。一些人认为它看起来更像是具有数百个非常愚蠢,非常不连贯的处理器的显卡。其他人认为,超长指令字(VLIW)计算机将成为主流。所有人都同意我们目前的顺序编程语言与这些类型的处理器不兼容。
我认为这些预测是正确的,硬件制造商在这一点上拯救我们的前景是严峻的。但是,今天我们为今天的硬件编写的程序有很大的优化空间。Rick Hudson在GopherCon 2015上发表了关于重新使用软件的“良性循环”的说法,该软件与我们今天的硬件配合使用,而不是它的不一致。
看看我之前展示的图表,从2015年到2018年,整数性能提升了5-8%,而且内存延迟时间更少,Go团队将垃圾收集器暂停时间减少了两个数量级。Go 1.11程序显示出比使用Go 1.6在相同硬件上的相同程序明显更好的GC延迟。这些都不是来自硬件。
因此,为了在当今世界的当今硬件上获得最佳性能,您需要一种编程语言:
-
是编译的,而不是解释的,因为解释的编程语言与CPU分支预测器和推测执行的交互性很差。
-
您需要一种允许编写高效代码的语言,它需要能够有效地讨论位和字节以及整数的长度,而不是假装每个数字都是理想的浮点数。
-
你需要一种语言让程序员有效地讨论内存,思考结构与java对象,因为所有指针追逐都会给CPU缓存带来压力,而缓存未命中会烧掉数百个周期。
-
作为应用程序性能而扩展到多个核心的编程语言取决于它使用其缓存的效率以及它在多个核心上并行工作的效率。
显然我们在这里谈论Go,我相信Go继承了我刚才描述的许多特征。
1.14.1。这对我们意味着什么?
只有三个优化:少做。少做一些。做得更快。
最大的收益来自1,但我们将所有时间都花在了3上。 - Michael Fromberger
本讲座的目的是说明当你谈论程序或系统的性能完全在软件中时。等待更快的硬件来挽救这一天是一个愚蠢的错误。
但有一个好消息,我们可以在软件方面做出一些改进,这就是我们今天要讨论的内容。
1.14.2。进一步阅读
-
微处理器的未来,Sophie Wilson JuliaCon 2018
-
计算的未来:与John Hennessy的对话 (Google I / O '18)
2.基准测试
测量两次并切一次。 - 古老的谚语
在我们尝试提高一段代码的性能之前,首先我们必须知道它当前的性能。
本节重点介绍如何使用Go测试框架构建有用的基准测试,并提供避免陷阱的实用技巧。
2.1。基准规则基准
在进行基准测试之前,您必须拥有稳定的环境才能获得可重复的结果。
-
机器必须处于空闲状态 - 不要在共享硬件上进行配置,不要在等待长基准运行时浏览网页。
-
注意省电和热缩放。这些在现代笔记本电脑上几乎是不可避免的。
-
避免虚拟机和共享云托管; 对于一致的测量,它们可能太嘈杂。
如果您负担得起,请购买专用的性能测试硬件。机架,禁用所有电源管理和热缩放,永不更新这些机器上的软件。从系统管理的角度来看,最后一点是糟糕的建议,但如果软件更新改变了内核或库执行的方式 - 想想Spectre补丁 - 这将使之前的任何基准测试结果无效。
对于我们其他人来说,有一个前后样本并多次运行它们以获得一致的结果。
2.2。使用测试包进行基准测试
该testing软件包内置支持编写基准测试。如果我们有这样一个简单的函数:
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
case 2:
return 2
default:
return Fib(n-1) + Fib(n-2)
}
}我们可以使用该testing包为该函数编写函数的基准。
func BenchmarkFib20(b *testing.B) {
for n := 0; n < b.N; n++ {
Fib(20) // run the Fib function b.N times
}
}基准函数与_test.go文件中的测试一起存在。 |
基准测试类似于测试,唯一真正的区别是他们需要的是一个*testing.B而不是一个*testing.T。这两种类型的实现testing.TB提供类似的人群的最爱接口Errorf(),Fatalf()和FailNow()。
2.2.1。运行包的基准
基准测试使用testing它们通过go test子命令执行它们。但是,默认情况下,在您调用时go test,将排除基准。
要在包中显式运行基准测试,请使用-bench标志。-bench采用与您要运行的基准测试名称相匹配的正则表达式,因此调用包中所有基准测试的最常用方法是-bench=.。这是一个例子:
% go test -bench=. ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 30000 40865 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 1.671s|
|
2.2.2。基准测试的工作原理
每个基准函数都被调用不同的值b.N,这是基准应该运行的迭代次数。
b.N从1开始,如果基准函数在1秒内完成 - 默认值 - 然后b.N增加,基准函数再次运行。
b.N大致顺序增加; 1,2,3,5,10,20,30,50,100等。基准测试框架试图变得聪明,如果它看到较小的值b.N相对较快地完成,它将更快地增加迭代次数。
看看上面的例子,BenchmarkFib20-8发现循环的大约30,000次迭代只需要一秒钟。从那里开始,基准框架计算出每次操作的平均时间为40865ns。
|
所述 这显示了使用1,2和4核运行基准测试。在这种情况下,该标志对结果几乎没有影响,因为该基准是完全顺序的。 |
2.2.3。提高基准精度
该fib函数是一个稍微有点人为的例子 - 除非您编写TechPower Web服务器基准测试 - 您的业务不太可能被计算在计算Fibonaci序列中第20个数字的速度。但是,基准测试确实提供了有效基准的忠实示例。
具体而言,您希望您的基准测试运行数万次迭代,以便您获得每次操作的良好平均值。如果您的基准测试仅运行100次或10次迭代,则这些运行的平均值可能具有较高的标准偏差。如果您的基准测试运行数百万或数十亿次迭代,平均值可能非常准确,但受到代码布局和对齐的影响。
为了增加迭代次数,可以使用-benchtime标志增加基准时间。例如:
% go test -bench=. -benchtime=10s ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib20-8 300000 39318 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 20.066sb.N跑到相同的基准测试,直到它达到一个超过10秒的返回值。当我们运行10倍以上时,迭代总数会增加10倍。结果没有太大变化,这是我们的预期。
为什么报告的总时间为20秒,而不是10秒?
如果你有一个运行毫安或数十亿迭代的基准测试,导致微操作或纳秒范围内的每个操作的时间,你可能会发现你的基准数字不稳定,因为热缩放,内存局部性,后台处理,gc活动等。
对于每次操作10或单个数字纳秒的时间,指令重新排序和代码对齐的相对论效应将对您的基准时间产生影响。
要使用-count标志多次处理此运行基准测试:
% go test -bench=Fib1 -count=10 ./examples/fib/
goos: darwin
goarch: amd64
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 1.95 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.97 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 1.96 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 2000000000 2.01 ns/op
BenchmarkFib1-8 2000000000 1.99 ns/op
BenchmarkFib1-8 1000000000 2.00 ns/op基准测试Fib(1)需要大约2纳秒,方差为+/- 2%。
Go 1.12中的新-benchtime标志现在需要进行多次迭代,例如。-benchtime=20x这将完全运行您的代码benchtime。
尝试使用-benchtime10x,20x,50x,100x和300x 运行上面的fib台。你看到了什么?
如果您发现go test需要针对特定软件包调整适用的默认值,我建议将这些设置编成一个,Makefile以便每个想要运行基准测试的人都可以使用相同的设置进行编码。 |
2.3。将基准与benchstat进行比较
在上一节中,我建议不止一次运行基准测试以获得更多数据。由于我在本章开头提到的电源管理,后台进程和热管理的影响,这对任何基准测试都是很好的建议。
我将介绍Russ Cox的一个名为benchstat的工具。
% go get golang.org/x/perf/cmd/benchstatBenchstat可以采取一系列基准测试,并告诉您它们的稳定性。这是Fib(20)关于电池电量的示例。
% go test -bench=Fib20 -count=10 ./examples/fib/ | tee old.txt
goos: darwin
goarch: amd64
BenchmarkFib20-8 50000 38479 ns/op
BenchmarkFib20-8 50000 38303 ns/op
BenchmarkFib20-8 50000 38130 ns/op
BenchmarkFib20-8 50000 38636 ns/op
BenchmarkFib20-8 50000 38784 ns/op
BenchmarkFib20-8 50000 38310 ns/op
BenchmarkFib20-8 50000 38156 ns/op
BenchmarkFib20-8 50000 38291 ns/op
BenchmarkFib20-8 50000 38075 ns/op
BenchmarkFib20-8 50000 38705 ns/op
PASS
ok _/Users/dfc/devel/high-performance-go-workshop/examples/fib 23.125s
% benchstat old.txt
name time/op
Fib20-8 38.4µs ± 1%benchstat告诉我们平均值为38.8微秒,样本间的变化为+/- 2%。这对电池电量非常好。
-
第一次运行是最慢的,因为操作系统的CPU时钟已经降低以节省功耗。
-
接下来的两次运行是最快的,因为操作系统决定这不是一个短暂的工作峰值,它提高了时钟速度,以尽快通过工作,希望能够返回睡觉。
-
其余的运行是用于产热的操作系统和bios交易功耗。
2.3.1。提高Fib
确定两组基准测试之间的性能差异可能是单调乏味且容易出错的。Benchstat可以帮助我们解决这个问题。
|
保存基准运行的输出很有用,但您也可以保存生成它的二进制文件。这使您可以重新运行基准测试以前的迭代。为此,使用 %go test -c %mv fib.test fib.golden |
先前的Fib功能具有斐波那契系列中第0和第1个数字的硬编码值。之后,代码以递归方式调用自身。我们将在今天晚些时候谈论递归的成本,但目前,假设它有成本,特别是因为我们的算法使用指数时间。
简单的解决方法就是从斐波纳契系列中硬编码另一个数字,将每个重复调用的深度减少一个。
func Fib(n int) int {
switch n {
case 0:
return 0
case 1:
return 1
case 2:
return 1
default:
return Fib(n-1) + Fib(n-2)
}
}该文件还包括一个全面的测试Fib。如果没有验证当前行为的测试,请不要尝试
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/dianfu2892/article/details/101467078 站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。
官方社群 |
