前言
- 众所周知,当一个数据库的单表数据量很大时,比如说是百万数量级的,如果我们使用普通的查询语句的话,耗时会非常多(相比加上索引),今天小编带领着大家做一下实验,见证一下具有二百多万条数据的单表,怎样优化查询语句。
- 首先,我们需要往数据库中的某张表中查询百万条数据,小编插入了2646229条记录,请看下面截图。

普通的查询语句分析
- 小编今天主要说的是简单查询语句和分页查询语句,我们先从简单的查询语句入手。 查询数据库中的第一条记录,查询条件没有加索引。截图如下
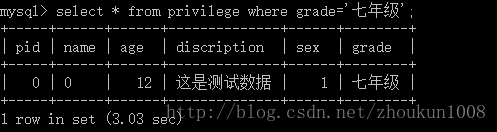
- 这是Privilege表中的第一条记录,大家看一下查询时间,用了3.03秒,下面我们查询最后一条记录,截图如下。
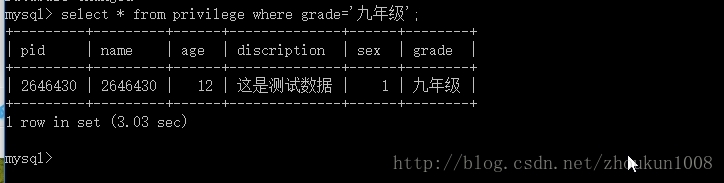
- 耗时还是3.03秒,可见,如果表中的数据量过大的话,我们如果不改变查询策略,及时查询表中的第一条数据,也会很耗时。现在,我们改变查询条件,将pid作为查询条件,因为pid为主键,数据库默认为主键索引,为了与上面一张图形成对比,我们也查询最后一条记录,即pid=2646430的一条记录,截图如下

- 由图我们就可以看出,使用pid为查询条件查询表中的最后一条记录,耗时为0.00 sec,不能说不耗时,但相比3.03 sec来说,已经灰常短了。那是为什么哪?就是因为pid上有默认的主键索引,这就是索引的力量。
分页查询语句
在mysql中,当我们分页查询数据库中的记录时,莫过于使用limit函数了,那么我们接下来做一下实验。
从第1000数据开始查,查10数据
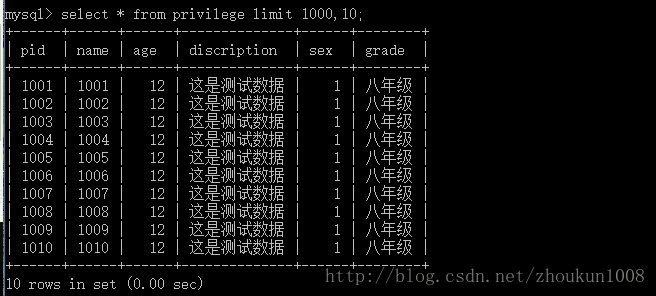
耗时非常短是吧,0.00 sec
从第800000条数据开始查,查10条数据
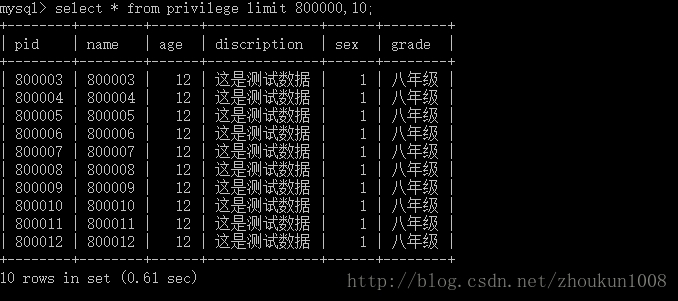
有图可以看出,耗时0.61 sec
查询此表中的最后10条记录
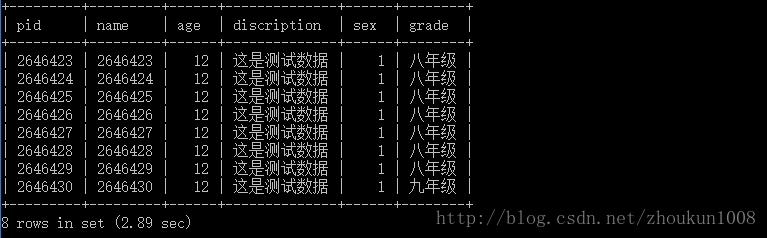
由图可见,耗时2.89 sec ,所以,使用limit分页查询数据所耗的时间,与查询记录条数的起始位置有关,那怎么优化查询速度哪?那就使用索引吧!我将pid,name加上了覆盖索引,语句如下
alter table privilege add index pid_name (pid, name);
- 现在小编用limit函数只查pid 和 name两个字段,分页数据如果还需要别的字段,那么就将该字段与pid建立覆盖索引,置于覆盖索引是什么,小编一会儿再说。请看图,我们还是查询表中的最后十条记录。
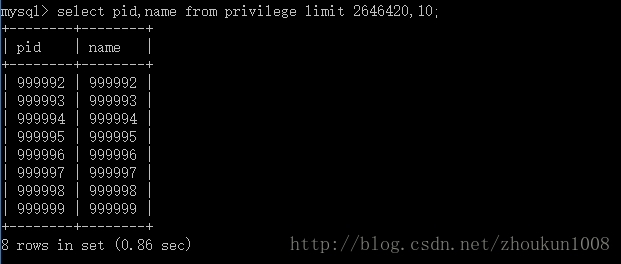
耗时0.86 sec ,2.89 sec 而言,是不是快了很多。
小结
- 从实验可以得出,表中的字段加上索引之后确实能提升查询的速度。当单表中的数据量达到百万之后,我们将数据库表中的数据从数据库中搜出来,再加上网络的传输,最终显示在某个网页上,岂不是更耗时,还有一点,在优化Sql语句的时候,我们尽量不要查询没有用的字段,不要动不动就将所有字段都查询出来,无论是对于数据库查询,还是网络传输,这都是耗时的。当然,索引也不是加上就是好的,当表中的数据没有太多事,加上索引反而是累赘,置于什么是覆盖索引,大家请看下一篇文章。
版权声明:本文来源CSDN,感谢博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u013067402/article/details/54292217
站方申明:本站部分内容来自社区用户分享,若涉及侵权,请联系站方删除。

