社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
很幸运地上了两次Tony老师关于python爬虫的课(收获巨多),在这里我对第一次课做一下知识总结:
1.什么是爬虫?
自动从网络上进行数据采集的程序
2.为什么有爬虫?
场景:
(1).新浪新闻报道的新闻从哪里来的?
①新闻肯定最开始产生于记者,记者将新闻发布到某些平台
②其他平台爬取并使用该平台记者所写的新闻,相当于一个人写了文章,另一个人推送文章
(2.)搜索引擎百度为什么可以承载属于其他网站的信息?
①百度很大一部分工作都是在运行自己的爬虫,采集其他网页并存储下来,等待搜索
②通过爬虫来不断补充自己的知识链,实时更新搜索的结果,内容
(3)电商平台
拼多多采集其他电商平台商品的价格浮动,处理分析
(4)大量数据样本需求
大数据的时代数据分析需要大量的数据样本,采集网络数据
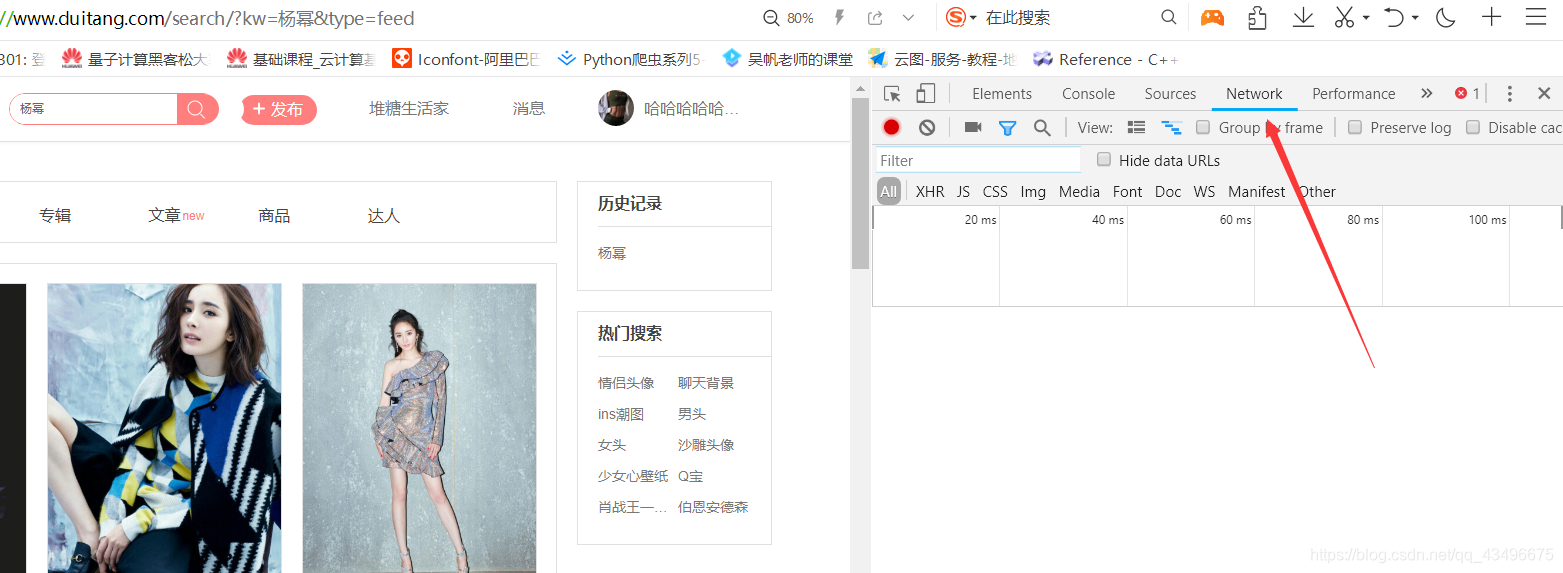
3.在百度上搜索淘宝到得到淘宝的网站信息
这些信息找出来的呢?
①DNS协议:解析域名:
尽管IP地址能够唯一地标记网络上的计算机,但IP地址是一长串数字,不直观,而且用户记忆十分不方便,于是人们又发明了另一套字符型的地址方案,即所谓的域名地址。IP地址和域名是一一对应的,这份域名地址的信息存放在一个叫域名服务器(DNS,Domain name server)的主机内,使用者只需了解易记的域名地址,其对应转换工作就留给了域名服务器。域名服务器就是提供IP地址和域名之间的转换服务的服务器。——摘自《百度百科》
淘宝的域名->淘宝的ip地址->用户通过ip地址请求服务器->服务器返还请求的淘宝信息->浏览器解析数据,显示界面
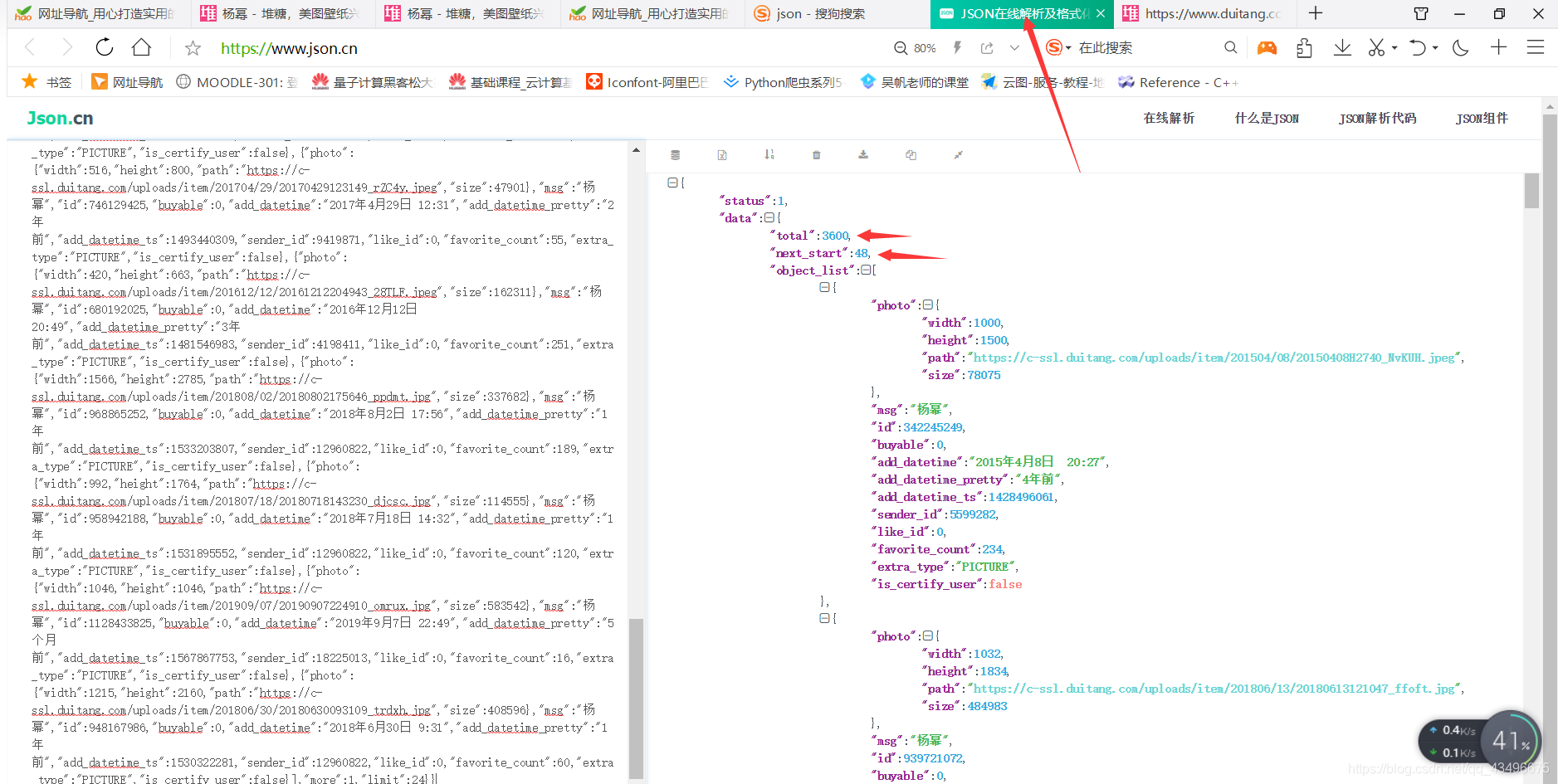
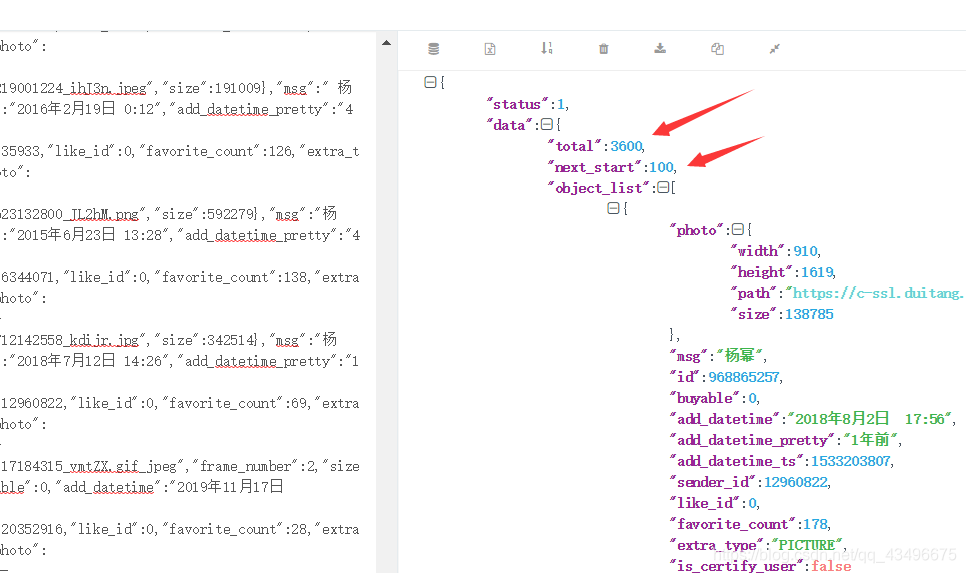
②对真实的url路径进行动态的修改




import requests
""" 利用字符串的格式化,每次访问不同的链接,从index开始请求图片数据
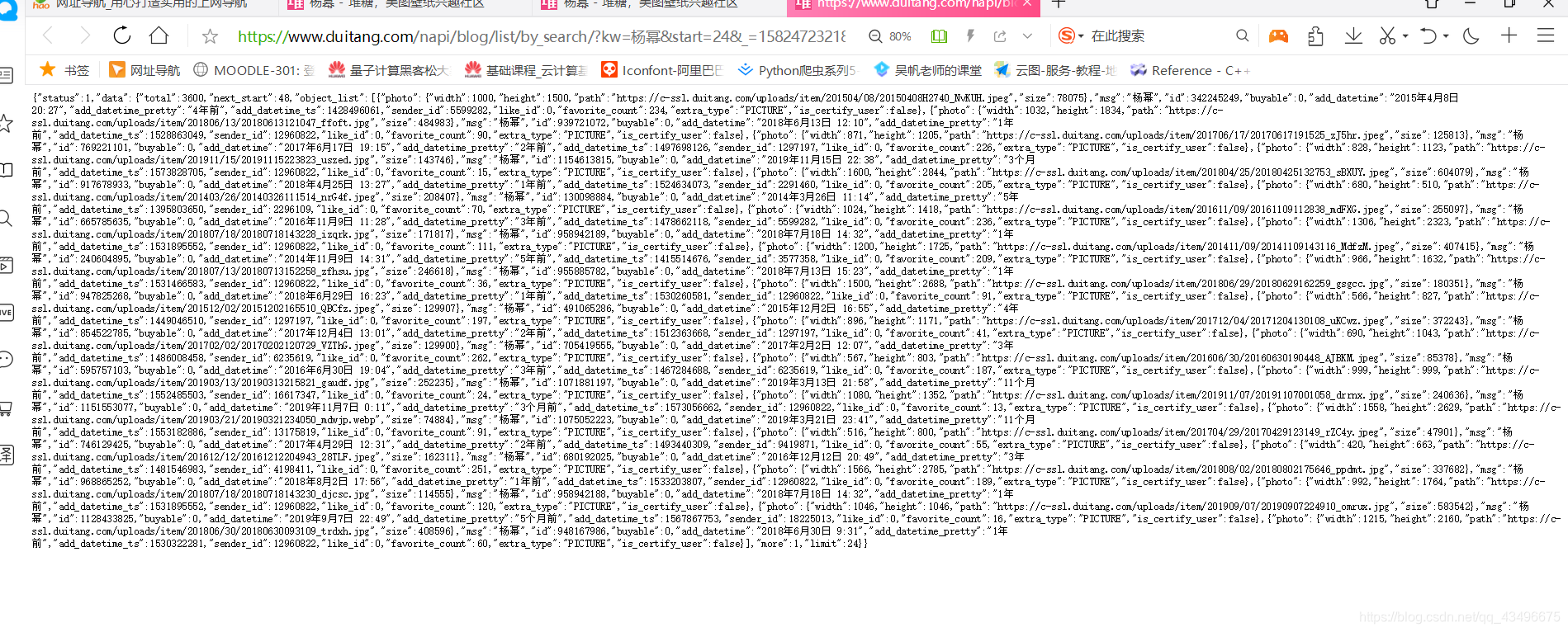
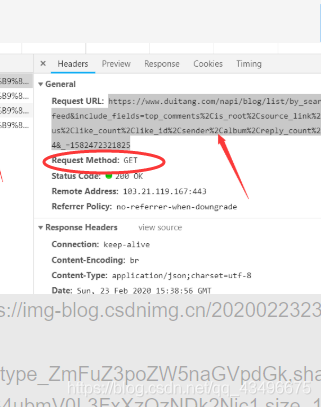
用get请求数据,如上图网页已经做出要求
最后的数据都存储在str_get列表里面
"""
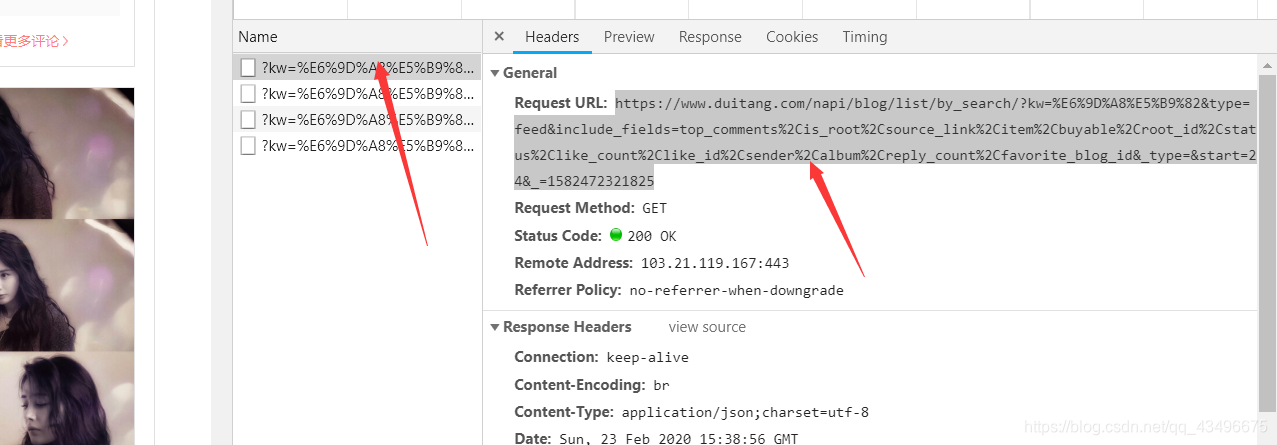
URL="https://www.duitang.com/napi/blog/list/by_search/?kw=%E6%9D%A8%E5%B9%82&start={}&limit=3600"
str_get=[]
for index in range(0,3600,100):
URL.format(index)
s=requests.get(URL).content.decode("utf-8")
str_get.append(s)
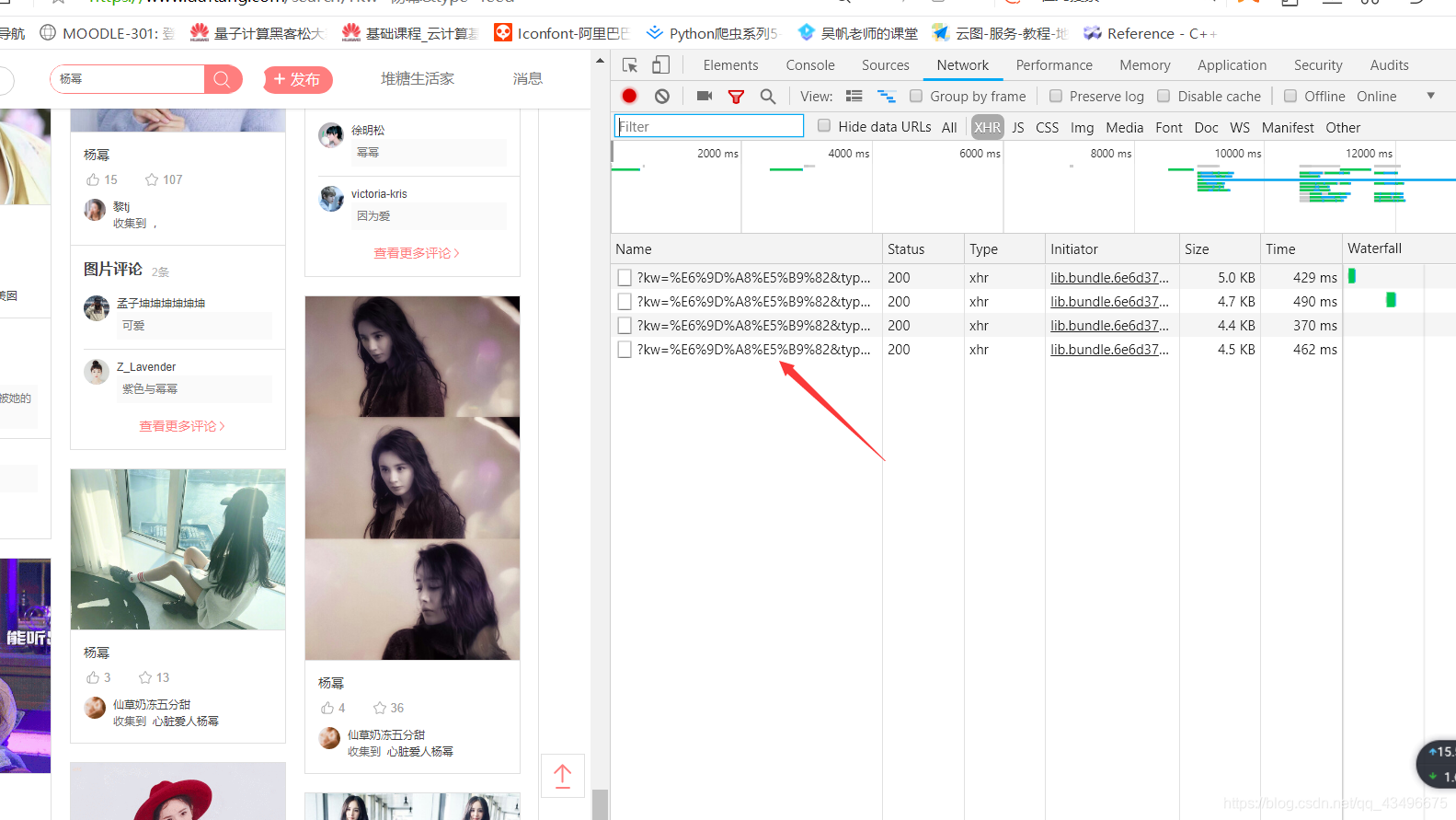
第二部解析数据:提取需要的内容(图片的链接)
将得到的url存储在url_all列表里
left_part='"https:'
right_part= '"'
url_all=[]
for s in str_get:
ip_get = []
start=0
while s.find(left_part, start)!=-1:
l = s.find(left_part, start)
r=s.find(right_part,l+1)
url=s[l+1:r]
url_get.append(url)
start=r
print(url)
url_all.extend(url_get)
numbers=0
for url in ip_all:
numbers+=1
data=requests.get(url)
path="image/"+str(numbers)+".jpg"
with open(path,'wb+') as file:
file.write(data.content)
然后我们可以在左侧看到存储的图片了
到此我们已经成功爬取到了杨幂的图片了
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
