
1、使用工具:
Python3.5
BeautifulSoup
2、抓取网站:
csdn首页文章列表 http://blog.csdn.net/
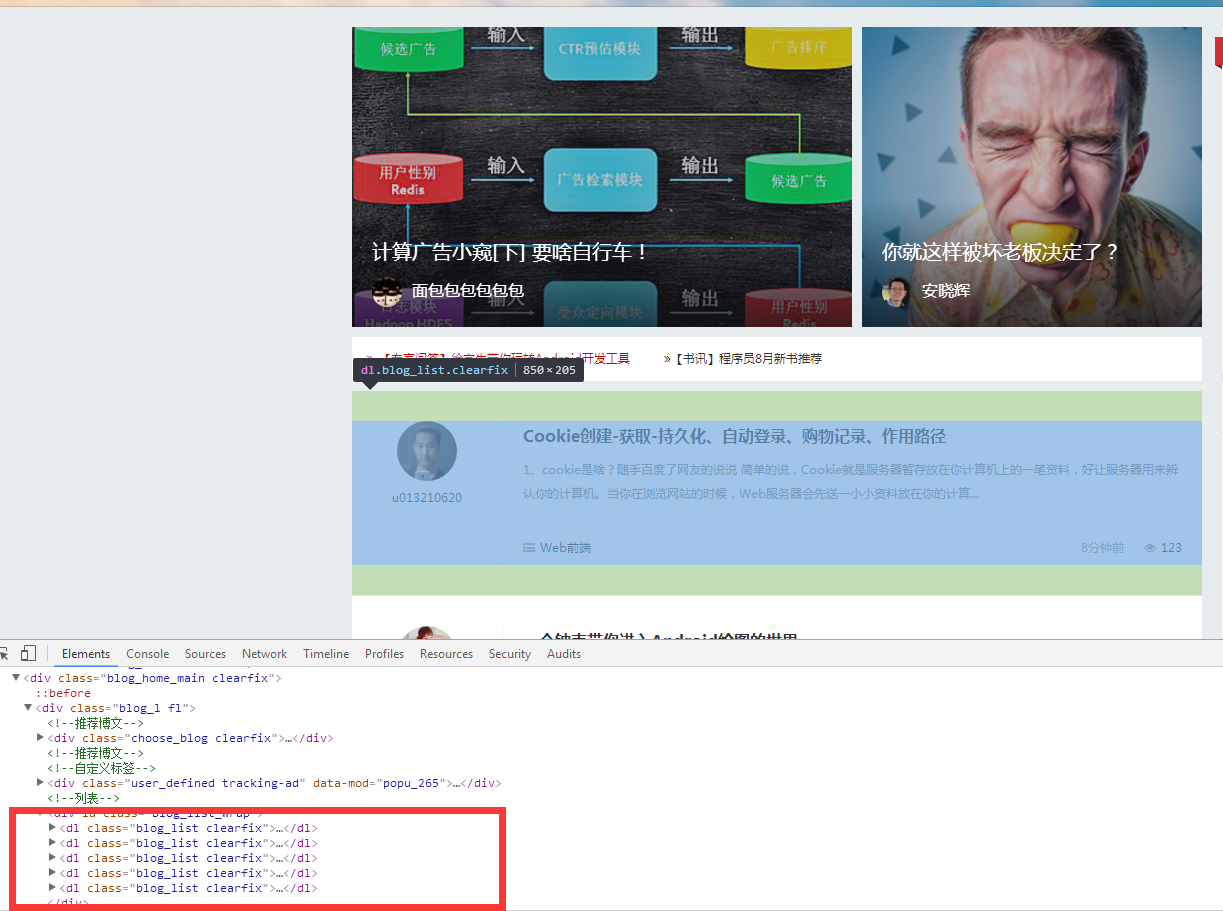
3、分析网站文章列表代码:
4、实现抓取代码:
__author__ = 'Administrator'
import urllib.request
import re
from bs4 import BeautifulSoup
########################################################
#
# 抓取csdn首页文章http://blog.csdn.net/?&page=1
#
# 参数baseUrl是要访问的网站地址
#
########################################################
class CsdnUtils(object):
def __init__(self):
user_agent='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
self.headers ={'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent':user_agent,
}
self.contentAll=set()
def getPage(self,url=None):
request=urllib.request.Request(url,headers=self.headers)
response=urllib.request.urlopen(request)
soup=BeautifulSoup(response.read(),"html.parser")
#print(soup.prettify())
return soup
def parsePage(self,url=None,page_num=None):
soup=self.getPage(url)
itemBlog=soup.find_all('dl','blog_list clearfix')
cnArticle=CsdnUtils
print("========================第",page_num,"页======================================")
for i,itemSingle in enumerate(itemBlog):
cnArticle.num=i
cnArticle.author=itemSingle.find('a','nickname').string
cnArticle.postTime=itemSingle.find('label').string
cnArticle.articleView=itemSingle.find('em').string
cnArticle.title=itemSingle.find('h3',"tracking-ad").string
cnArticle.url=itemSingle.find("h3").find("a").get("href")
print("数据:",cnArticle.num+1,'t',cnArticle.author,'t',cnArticle.postTime,'t',cnArticle.articleView,'t',cnArticle.title,'t',cnArticle.url)
####### 执行 ########
if __name__ =="__main__":
#要抓取的网页地址'http://blog.csdn.net/?&page={}'.format(i+1),i+1)
url = "http://blog.csdn.net"
cnblog=CsdnUtils()
for i in range(0,2):
cnblog.parsePage(url,i+1)
5、执行结果:

