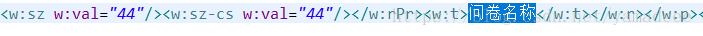社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
最近的需求,有一个导出单张问卷的功能,导出为word。
网上也有很多资料,基本上来说使用freemarker模板导出的教程居多。但是基本上都是比较简单的导出对于遍历之类的问题一带而过。所以记录下自己的开发过程,以便日后查阅,也希望能帮到一些人。
本教程也是使用freemarker
导出word需要有耐心,“word已损坏,无法打开”是常事,不要急。
最好第一次就将要显示的内容,结构,样式都确定下来。因为想要该样式什么的比较麻烦。
跟网上的教程一样,导出word主要分为以下几步, 新建模板,组织数据,替代
根据需求设计文档
根据自己的需要设计好文档。 像“问卷名称”,“corpId”。在转化成xml文件后会被freemaker的脚本替换
将模板另存为xml。
对于高版本的wold,另存为xml,有两种选择。 1. word 2003 xml 文档(.xml) 2.word xml 文档(.xml)
word2003 其实就是以.doc结尾的word文档 , word xml 就是以.docx结尾的文档。
我使用的是第一种方式。这两种格式的xml文档有些许的差别。
全中文作为占位符。因为使用英文的话,转为xml时,word可能会将一个单词拆分成两个,比如 我使用Title作为占位符,转化为xml后,搜索的时候一直找不到。然后你会发现,其实word将其拆分成T 和itle。这种事也不是绝对的(同一个单词如果有不同的样式就会保存在不同的<w:r>中),所以只是建议,即便同一个单词被拆分了,也不用急等到后面就有解决方案。通常我们会将数据保存到map中,这样配合freemarker比较方便实现数据的填充。
List<Map<String,Object>> categorys = new ArrayList<>(); //问卷的类别
Map<String,Object> cate1 =new HashMap<>(); //保存第一个类别下的试题, (选择题)
cate1.put("category","选择题");//
List<Map<String,Object>> issuesList1= new ArrayList<>(); //存放问题
Map<String,Object> issues1= new HashMap<>();
issues1.put("questionDesc","你喜欢那些动漫");
issues1.put("questionType","多选");
List<Map<String,Object>> choices = new ArrayList<>(); //存放选项
Map<String,Object> choice1 =new HashMap<>();
choice1.put("optionDesc","overload");
Map<String,Object> choice2 =new HashMap<>();
choice2.put("optionDesc","七龙珠");
Map<String,Object> choice3 =new HashMap<>();
choice3 .put("optionDesc","柯南");
Map<String,Object> choice4 =new HashMap<>();
choice4 .put("optionDesc","海贼王");
choices.add(choice1);
choices.add(choice2);
choices.add(choice3);
choices.add(choice4);
issues1.put("choices",choices )
issuesList1.add(issues1);
cate1.put("issues",issuesList1);
Map<String,Object> cate2 =new HashMap<>(); //保存第二个类别下的试题, (填空题)
cate2.put("category","填空题");
List<Map<String,Object>> issuesList2 = new ArrayList<>(); //存放问题
Map<String,Object> blank = new HashMap<>(); //填空题
blank.put("questionDesc","你幸福吗???");
issuesList2 .add(blank);
cate2.put("issues",issuesList2 );
categorys .add(cate1 );
categorys .add(cate2);
//根对象
Map<String,Object> map =new HashMap<>();
//答题人信息
map.put("corpId","客户编号");
map.put("corpName","客户名称");
map.put("loginName","问卷填写人姓名");
map.put("loginPhone","问卷填写人手机号");
//问卷信息
map.put("questionnaireName","问卷测试!!!"); //问卷名称.
map.put("categories",categorys );//问卷的题目
直接看代码可能会让很多人心烦,所以画了以下大概的结构
### clientInfo 问卷填写人基本信息部分
-coprId
- corpName
- loginName
- loginPhone
## questionInfo 问卷笔本信息
- questionnaireName
- categorys (问题大类)
-类别1(选择题)
- 选择题1
- 选项1
- 选项2
- 选项3
- 选择题2
- 选项1
- 选项2
- 。。。。
- 类别2 (填空题)
- 填空1
- 填空2
- 填空3
先替换还是先改文件类型,没有影响。建议还是先更改文件类型再替换。更改文件类型以后,可以使用eclipse等开发工具,编辑ftl文件,ftl文本插件有语法的高亮和错误提示,相对来说比较友好,也更容易找出错误
将之前的另存的xml模板文件,更改后缀为.ftl
搜索你之前在模板中定义的占位符。 比如“问卷名称”,替换为“${questionnaireName}”(因为我把问卷名称放在了根Map中,所以可以直接通过Key来取值)以此类推将其他内容替换。 所以使用Map组织数据对于 freemarker 来说获取数据特别方便
注意:替换的内容需要包裹在<w:t> </w:t>之中。
对于List类型的内容来说需要进行遍历。对于上面的数据结构来说,我们需要对categories,issues,choices遍历。
首先我们需要知道word xml的大概结构
<w:wordDocument>
<w:body>
<w:p>
<w:pPr>
</w:pPr>
<w:r>
<w:rPr>
属性:加粗,倾斜,字体颜色等
</w:rPr>
<w:t> 文本内容</w:t>
</w:r>
</w:p>
</w:body>
</<w:wordDocument>
<w:p> 会包裹一段数据,(段落)
<w:r> 它是具有一组共同属性(如格式设置)的文本区域。它可以包含多个<w:t>元素。如果示例文本中只有一个字是粗体,粗体将会分离到一个<w:r>中
<w:t> 实际的文本内容
下面我们用一个例子来说明,写了一些内容,并配置了颜色
另存为xml文件后的部分代码
<w:p wsp:rsidR="0084377C" wsp:rsidRPr="002827FA" wsp:rsidRDefault="009C2113">
<w:pPr>
<w:rPr>
<w:color w:val="000000"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr><w:rFonts w:hint="fareast"/></w:rPr>
<w:t>哈哈</w:t>
</w:r>
<w:r wsp:rsidRPr="009C2113">
<w:rPr>
<w:rFonts w:hint="fareast"/>
<w:color w:val="FF0000"/>
</w:rPr>
<w:t>嗝</w:t>
</w:r>
<w:r wsp:rsidRPr="002827FA">
<w:rPr>
<w:rFonts w:hint="fareast"/>
<w:color w:val="000000"/>
</w:rPr>
<w:t>哈哈</w:t>
</w:r>
</w:p>
从上面可以清楚的看到,上面的内容在一个段落里包裹。同时在一个段落里可以设置多个不同的文字样式,这部分数据就会存放在 <w:r> 中,样式数据就存放在<w:rPr> 里面。
所以说如果我们需要迭代,首先要找到你要迭代的位置在哪里?找好以后就完成了一半的工作。
例如上面的小案例,我们需要遍历 标题 ~ 选项。 所以首先定位到 “标题” 所在的<w:p> 然后查找 “选项”所在的</w:p>。 然后将这么内容使用<#list> </#list>包裹就可以了。
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.23</version>
</dependency>
下面的测试程序就可以在网上随便找了
导出Word工具类
@SuppressWarnings("deprecation")
public class ExportWordUtils {
private Template template;
public ExportWordUtils(String basePackage, String templateName) throws Exception {
init(basePackage, templateName);
}
private void init(String basePackage, String templateName) throws Exception {
Configuration config = new Configuration();//需要指定版本
config.setClassLoaderForTemplateLoading(ExportWordUtils.class.getClassLoader(), basePackage);//去那个文件夹下寻找模板文件
config.setOutputEncoding("utf-8");
template = config.getTemplate(templateName);//模板名称获取模板
}
public <K, V> void doExport(OutputStream out, Map<K, V> results) throws TemplateException, IOException {
template.process(results, new OutputStreamWriter(out));//对模板进行数据填充
}
public void setHeader(HttpServletRequest request, HttpServletResponse response, String fileName) throws UnsupportedEncodingException {
String userAgent = request.getHeader("User-Agent");
if(StringUtils.contains(userAgent, "MSIE")||StringUtils.contains(userAgent, "Trident") ||
StringUtils.contains(userAgent, "Edge")){ //解决IE中文名称乱码
fileName = URLEncoder.encode(fileName,"UTF8");
}else if(StringUtils.contains(userAgent, "Firefox")){//火狐和其他浏览器中文名乱码
fileName = new String(fileName.getBytes("utf8"), "ISO8859-1");
}
response.setContentType("application/octet-stream";charset=utf-8");
response.setHeader("Content-Disposition", "attachment;" + " filename=""+fileName+""");
}
}
导出请求
@RequestMapping("/exportWorld")
public ResultInfo exportWorld(String param,HttpServletRequest request,HttpServletResponse response) {
OutputStream out=null;
try {
out = response.getOutputStream();
Map<String,Object> reuslts =questionnaireService.getAnswers(param); //获取问卷信息,就是上面的结构
if(reuslts==null)
return ResultInfo.error("问卷导出失败!");
ExportWordUtils word =new ExportWordUtils("/excel", "questionnaire.ftl"); // 项目使用的spring boot 。/excel/questionnaire.ftl文件存放在src/main/resources目录下
word.setHeader(request, response, reuslts.get("questionName")+".doc");
word.doExport(out, reuslts);
} catch (Exception e) {
e.printStackTrace();
}finally {
if(out!=null)
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
上面的代码每次请求都会下载一个word文件。但是使用该方式来测试还是太麻烦。
程序不报错的话只能说明数据请求, freemarker数据替换和渲染没有问题,但是Word的内容结构是否完整这是不确定的(xml的格式要求比html 严格)。
所以测试的时候,我会将下面的代码注释掉,
//word.setHeader(request, response, reuslts.get("questionName")+".doc");
返回内容就是字节流。浏览器是支持xml字节流的渲染,当该文件结构不完整时,就会报错。然后调整我们的代码就可以了
比如,我在第30行,增加了一个多余的 <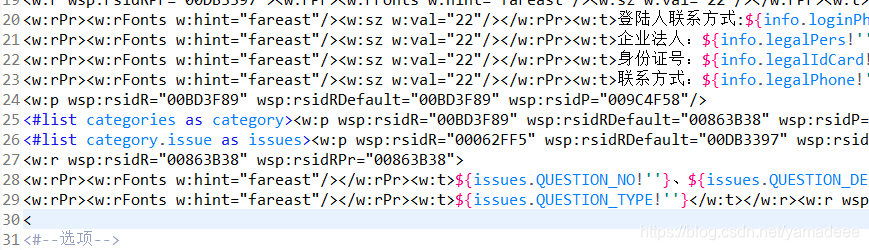
请求之后就会抛出下面的错误,这样比较容易定位问题。
但是有些问题并不那么容易定位。尤其是遍历元素的时候,位置没有确定好,就不太好定位。
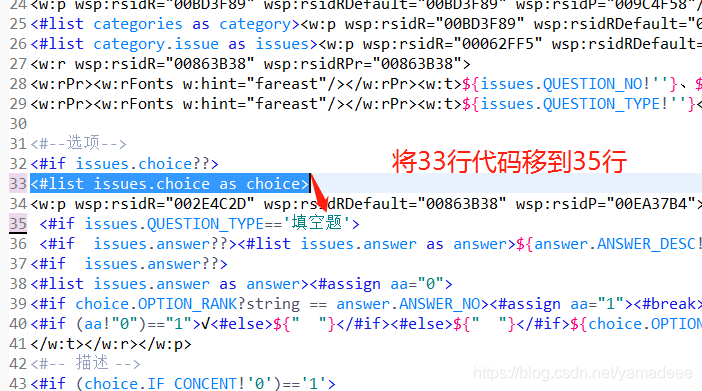

这时候我们可以将字节流在控制台输出。
// out = response.getOutputStream();
out =new ByteArrayOutputStream();
Map<String,Object> reuslts =questionnaireService.getQuestionnaireAnswer(questionnaireId,corpIdGroup,corpId,loginCode,sourceCode);
if(reuslts==null)
return ResultInfo.error("问卷导出失败!");
ExportWordUtils word =new ExportWordUtils("/excel", "questionnaire.ftl");
// word.setHeader(request, response, reuslts.get("questionName")+".doc");
word.doExport(out, reuslts);
System.out.println(out);
将输出的数据在合适的编辑器中打开,找到报错的位置。可以选择在线xml校验等具有xml校验功能的工具,这样更容易定位问题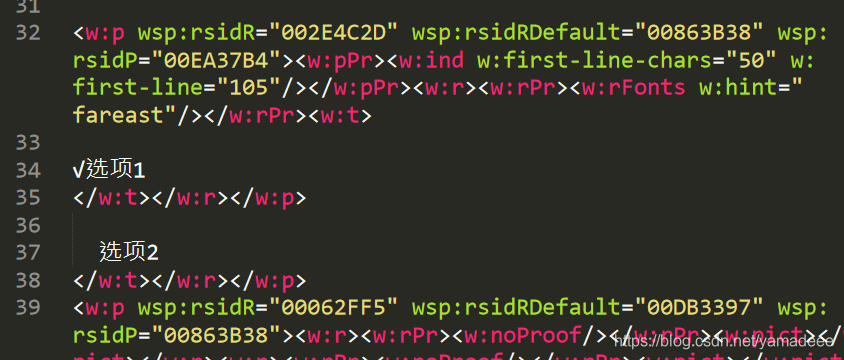
当导出word提示 “无法打开文件,内容有错误” ,但是实际数据已经替换完成。这个问题通常就是,不小心修改了word xml的结构,导致xml标签没有正常闭合 或者 填充的内容中存在<。尤其使用<#if> <#list> 等控制语句时尤其容易出现标签无法闭合的问题,所以要特别注意,这些语句的包裹范围。必要的话需要对填充的内容(特指 <)进行转码。
如果在word 模板中使用的占位元素,被拆分了怎么办?下面就是使用Title作为占位符,但是另存在xml时,被拆分了
<w:p wsp:rsidR="00062FF5" wsp:rsidRDefault="00E640FA" wsp:rsidP="00062FF5"><w:pPr><w:pStyle w:val="a3"/><w:jc w:val="center"/><w:rPr><w:b/>
<w:sz w:val="44"/><w:sz-cs w:val="44"/></w:rPr></w:pPr>
<w:r><w:rPr><w:rFonts w:hint="fareast"/><w:b/><w:sz w:val="44"/><w:sz-cs w:val="44"/></w:rPr>
<w:t>`T`</w:t></w:r>
<w:r><w:rPr><w:b/><w:sz w:val="44"/><w:sz-cs w:val="44"/></w:rPr>
<w:t>`itle`</w:t></w:r>
</w:p>
很简单将多余的<w:r> … </w:r>删除就好了,将T 所在的<w:r>删除就可以了。
不会freemarker怎么办? 。freemarker中文文档,点击就送
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!