社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
根据实际的物理属性,CPU域可以分为以下几类:
| CPU分类 | Linux内核分类 | 说明 |
|---|---|---|
| 超线程(SMT, Simultaneous MultiThreading) | CONFIG_SCHED_SMT | 一个物理核心可以同时执行多于一个线程,超线程使用相同的CPU资源且共享L1 Cache,迁移进程不会影响Cache的利用率 |
| 多核(MC, MultiCore) | CONFIG_SCHED_MC | 每个物理核心独享L1 Cache,多个物理核心可以组成一个cluster,cluster里的CPU共享L2 Cache |
| 片上系统(SoC, System-on-a-Chip) | 称为DIE | ? |
此处参考自这篇博客,参考内容如下:
CPU拓扑结构简介
- SMT Level
超线程处理器的一个核心- MC Level
多核CPU的一个核心- DIE Level
一个物理CPU的晶片(注意不是package,package是封装好了的,肉眼看到的CPU处理器)cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”。
内核有一个数据结构struct sched_domain_topology_level来描述CPU的层次关系,简称SDTL,请见[/include/linux/sched/topology.h:186]
struct sched_domain_topology_level {
sched_domain_mask_f mask; //函数指针,用于指定某个SDTL的cpumask bitmap
sched_domain_flags_f sd_flags; //函数指针,用于指定某个SDTL的标志位
int flags;
int numa_level;
struct sd_data data;
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
};另外,Linux内核定义了default_topology[]来概括CPU域的层次结构
,顺序是自底向上,请见[/kernel/sched/topology.c:1205]
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
static struct sched_domain_topology_level *sched_domain_topology =
default_topology;从default_topology[]看,DIE类型是默认类型,而SMT和MC类型只有和具体的硬件架构匹配,才能发挥出效果。
内核对CPU的管理是通过bitmap管理的,可见[/include/linux/cpumask.h:16]
typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;Linux定义了四种CPU状态:possible、present、online、active,可见[kernel/cpu.c:1960]
#ifdef CONFIG_INIT_ALL_POSSIBLE
struct cpumask __cpu_possible_mask __read_mostly
= {CPU_BITS_ALL};
#else
struct cpumask __cpu_possible_mask __read_mostly;
#endif
EXPORT_SYMBOL(__cpu_possible_mask);
struct cpumask __cpu_online_mask __read_mostly;
EXPORT_SYMBOL(__cpu_online_mask);
struct cpumask __cpu_present_mask __read_mostly;
EXPORT_SYMBOL(__cpu_present_mask);
struct cpumask __cpu_active_mask __read_mostly;
EXPORT_SYMBOL(__cpu_active_mask);cpu_possible_mask表示的是系统中有多少个可以运行的CPU核心;cpu_online_mask表示的是系统中有多少个处于工作状态的CPU核心;cpu_present_mask表示的是系统中有多少个具备online条件的CPU核心,不一定都处于online状态,有的CPU核心可能被热插拔了;cpu_active_mask表示系统中有多少个活跃的CPU。 bitmap使用一个long型数组name[],每一位代表一个CPU。对于32位处理器来说,一个long类型最多只能支持32个CPU核心。假设CONFIG_NR_CPUS是8,那么只需要一个long类型的数组就行了,struct cpumask数据结构本质上也是bitmap,内核通常使用cpumask的相关接口函数来管理CPU核心数量,在[/lib/cpumask.c]和[includelinuxcpumask.h]文件实现了大部分和cpumask有关的API。
[start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->sched_init_smp()->sched_init_domains()]
// /kernel/sched/topology.c:1778
int sched_init_domains(const struct cpumask *cpu_map)
{
int err;
zalloc_cpumask_var(&sched_domains_tmpmask, GFP_KERNEL);
zalloc_cpumask_var(&sched_domains_tmpmask2, GFP_KERNEL);
zalloc_cpumask_var(&fallback_doms, GFP_KERNEL);
arch_update_cpu_topology();
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
if (!doms_cur)
doms_cur = &fallback_doms;
cpumask_and(doms_cur[0], cpu_map, housekeeping_cpumask(HK_FLAG_DOMAIN));
err = build_sched_domains(doms_cur[0], NULL);
register_sched_domain_sysctl();
return err;
}sched_init_domains()函数传入的参数是cpu_active_mask。cpu_active_mask的值是什么时候初始化的?它和内核配置模块的宏CONFIG_NR_CPUS有什么关系?
先来看看cpu_possible_mask的初始化。[/arch/arm/kernel/devtree.c:70]
//start_kernel()->setup_arch()->arm_dt_init_cpu_maps()
void __init arm_dt_init_cpu_maps(void)
{
/*
* Temp logical map is initialized with UINT_MAX values that are
* considered invalid logical map entries since the logical map must
* contain a list of MPIDR[23:0] values where MPIDR[31:24] must
* read as 0.
*/
struct device_node *cpu, *cpus;
int found_method = 0;
u32 i, j, cpuidx = 1;
u32 mpidr = is_smp() ? read_cpuid_mpidr() & MPIDR_HWID_BITMASK : 0;
u32 tmp_map[NR_CPUS] = { [0 ... NR_CPUS-1] = MPIDR_INVALID };
bool bootcpu_valid = false;
cpus = of_find_node_by_path("/cpus");
if (!cpus)
return;
for_each_child_of_node(cpus, cpu) {
const __be32 *cell;
int prop_bytes;
u32 hwid;
if (of_node_cmp(cpu->type, "cpu"))
continue;
...
/*
* Since the boot CPU node contains proper data, and all nodes have
* a reg property, the DT CPU list can be considered valid and the
* logical map created in smp_setup_processor_id() can be overridden
*/
for (i = 0; i < cpuidx; i++) {
set_cpu_possible(i, true);
cpu_logical_map(i) = tmp_map[i];
pr_debug("cpu logical map 0x%xn", cpu_logical_map(i));
}
}在系统启动时,arm_dt_init_cpu_maps()函数通过查询DTS来获取CPU的核心数,然后通过set_cpu_possible()函数设置到cpu_possible_bits中,从而设置cpu_possible_mask变量。接下来看一下[/arch/arm/kernel/smp.c:442]
//start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->smp_prepare_cpus()
void __init smp_prepare_cpus(unsigned int max_cpus)
{
unsigned int ncores = num_possible_cpus();
init_cpu_topology();
smp_store_cpu_info(smp_processor_id());
/*
* are we trying to boot more cores than exist?
*/
if (max_cpus > ncores)
max_cpus = ncores;
if (ncores > 1 && max_cpus) {
/*
* Initialise the present map, which describes the set of CPUs
* actually populated at the present time. A platform should
* re-initialize the map in the platforms smp_prepare_cpus()
* if present != possible (e.g. physical hotplug).
*/
init_cpu_present(cpu_possible_mask);
/*
* Initialise the SCU if there are more than one CPU
* and let them know where to start.
*/
if (smp_ops.smp_prepare_cpus)
smp_ops.smp_prepare_cpus(max_cpus);
}
}[/kernel/cpu.c:1977]
void init_cpu_present(const struct cpumask *src)
{
cpumask_copy(&__cpu_present_mask, src);
}在初始化SMP时,smp_prepare_cpus()函数把cpu_possible_mask复制到cpu_present_mask中。
//start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->smp_init()
/* Called by boot processor to activate the rest. */
void __init smp_init(void)
{
int num_nodes, num_cpus;
unsigned int cpu;
idle_threads_init();
cpuhp_threads_init();
pr_info("Bringing up secondary CPUs ...n");
/* FIXME: This should be done in userspace --RR */
for_each_present_cpu(cpu) {
if (num_online_cpus() >= setup_max_cpus)
break;
if (!cpu_online(cpu))
cpu_up(cpu);
}
num_nodes = num_online_nodes();
num_cpus = num_online_cpus();
pr_info("Brought up %d node%s, %d CPU%sn",
num_nodes, (num_nodes > 1 ? "s" : ""),
num_cpus, (num_cpus > 1 ? "s" : ""));
/* Any cleanup work */
smp_cpus_done(setup_max_cpus);
}smp_init()函数遍历cpu_present_mask中的CPU中,然后使能该CPU。该CPU核心使能完成(cpu_up()函数)后就会被添加到cpu_active_mask变量中,总结如下:
cpu_possible_mask是通过查询系统DTS配置文件获取的系统CPU数量cpu_present_mask等同于cpu_possible_maskcpu_active_mask是经过使能后(cpu_online()函数)的CPU数量接下来看sched_init_domains()函数中的第16行代码,build_sched_domains()是真正开始建立调度域拓扑关系的函数。见[start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->sched_init_smp()->sched_init_domains()->build_sched_domains()]
///kernel/sched/topology.c:1643
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
enum s_alloc alloc_state;
struct sched_domain *sd;
struct s_data d;
struct rq *rq = NULL;
int i, ret = -ENOMEM;
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
...bulid_sched_domains()函数的参数cpu_mask是cpu_active_mask,attr参数设成NULL。首先看第10行代码中的__visit_domain_allocation_hell()函数,该函数调用__sdt_alloc()来创建调度域等数据结构。见[start_kernel()->rest_init()->kernel_init()->kernel_init_freeable()->sched_init_smp()->sched_init_domains()->build_sched_domains()->__visit_domain_allocation_hell()->sdt_alloc()]
// /kernel/sched/topology.c:1503
static int __sdt_alloc(const struct cpumask *cpu_map)
{
struct sched_domain_topology_level *tl;
int j;
for_each_sd_topology(tl) {
struct sd_data *sdd = &tl->data;
sdd->sd = alloc_percpu(struct sched_domain *);
if (!sdd->sd)
return -ENOMEM;
sdd->sds = alloc_percpu(struct sched_domain_shared *);
if (!sdd->sds)
return -ENOMEM;
sdd->sg = alloc_percpu(struct sched_group *);
if (!sdd->sg)
return -ENOMEM;
sdd->sgc = alloc_percpu(struct sched_group_capacity *);
if (!sdd->sgc)
return -ENOMEM;
for_each_cpu(j, cpu_map) {
struct sched_domain *sd;
struct sched_domain_shared *sds;
struct sched_group *sg;
struct sched_group_capacity *sgc;
sd = kzalloc_node(sizeof(struct sched_domain) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sd)
return -ENOMEM;
*per_cpu_ptr(sdd->sd, j) = sd;
sds = kzalloc_node(sizeof(struct sched_domain_shared),
GFP_KERNEL, cpu_to_node(j));
if (!sds)
return -ENOMEM;
*per_cpu_ptr(sdd->sds, j) = sds;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sg)
return -ENOMEM;
sg->next = sg;
*per_cpu_ptr(sdd->sg, j) = sg;
sgc = kzalloc_node(sizeof(struct sched_group_capacity) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
if (!sgc)
return -ENOMEM;
#ifdef CONFIG_SCHED_DEBUG
sgc->id = j;
#endif
*per_cpu_ptr(sdd->sgc, j) = sgc;
}
}
return 0;
}观察第7行代码中的for循环,遍历系统默认CPU拓扑层次关系数组default_topology,系统有一个指针sched_domain_topology数组。
// /kernel/sched/topology.c:1216
static struct sched_domain_topology_level *sched_domain_topology =
default_topology;
#define for_each_sd_topology(tl)
for (tl = sched_domain_topology; tl->mask; tl++)假设系统中只定义了CONFIG_SCHED_MC,那么default_topology数组只有MC、和DIE两层。通常不同的体系结构有不同的定义,例如对于ARM来说就定义了arm_topology[]数组,然后通过set_sched_topology()函数设置到sched_domain_topology变量中。
// /arch/arm/kernel/topology.c:292
static struct sched_domain_topology_level arm_topology[] = {
#ifdef CONFIG_SCHED_MC
{ cpu_corepower_mask, cpu_corepower_flags, SD_INIT_NAME(GMC) },
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};因此第7行代码中的for循环从sched_domain_topology数组开始,顺序是SMT->MT->DIE。第10-24行代码为每个SDTL的调度域(struct sched_domain)、调度组(struct sched_group)和调度组能力(struct sched_group_capacity)分配Per-CPU变量的数据结构。第26-64行代码为每个CPU都创建一个调度域、调度组和调度能力组数据结构,并且存放在Per-CPU变量中。
struct sched_domain_topology_level数据结构来描述,并且内嵌一个struct sd_data数据结构,包含sched_domain、sched_group和sched_group_capacity的二级指针Per-CPU变量的含sched_domain、sched_group和sched_group_capacity数据结构sched_domain、sched_group和sched_group_capacity数据结构,即每个CPU在每个SDTL中都有对应的调度域和调度组。下面继续看build_sched_domains()函数。
// /kernel/sched/topology.c:1642
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
...
/* Set up domains for CPUs specified by the cpu_map: */
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) {
sd = build_sched_domain(tl, cpu_map, attr, sd, i);
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP)
sd->flags |= SD_OVERLAP;
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
...
}首先遍历cpu_map中所有的CPU,然后对于每个CPU遍历所有的SDTL,相当于每个CPU都有自己的一套SDTL对应的调度域,为每个CPU都初始化一整套SDTL对应的调度域和调度组。第11行代码为每个CPU中的每个SDTL都调用build_sched_domain()函数来建立调度域和调度组。
// /kernel/sched/topology.c:1608
static struct sched_domain *build_sched_domain(struct sched_domain_topology_level *tl,
const struct cpumask *cpu_map, struct sched_domain_attr *attr,
struct sched_domain *child, int cpu)
{
struct sched_domain *sd = sd_init(tl, cpu_map, child, cpu);
if (child) {
sd->level = child->level + 1;
sched_domain_level_max = max(sched_domain_level_max, sd->level);
child->parent = sd;
if (!cpumask_subset(sched_domain_span(child),
sched_domain_span(sd))) {
pr_err("BUG: arch topology borkenn");
#ifdef CONFIG_SCHED_DEBUG
pr_err(" the %s domain not a subset of the %s domainn",
child->name, sd->name);
#endif
/* Fixup, ensure @sd has at least @child CPUs. */
cpumask_or(sched_domain_span(sd),
sched_domain_span(sd),
sched_domain_span(child));
}
}
set_domain_attribute(sd, attr);
return sd;
}build_sched_domain()函数第4行代码中的sd_init()函数由tl和cpu id来获取对应的struct sched_domain数据结构并初始化其成员。接下来我们查看sd_init()函数。
// /kernel/sched/topology.c:1080
static struct sched_domain *
sd_init(struct sched_domain_topology_level *tl,
const struct cpumask *cpu_map,
struct sched_domain *child, int cpu)
{
struct sd_data *sdd = &tl->data;
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
int sd_id, sd_weight, sd_flags = 0;
#ifdef CONFIG_NUMA
/*
* Ugly hack to pass state to sd_numa_mask()...
*/
sched_domains_curr_level = tl->numa_level;
#endif
sd_weight = cpumask_weight(tl->mask(cpu));
if (tl->sd_flags)
sd_flags = (*tl->sd_flags)();
if (WARN_ONCE(sd_flags & ~TOPOLOGY_SD_FLAGS,
"wrong sd_flags in topology descriptionn"))
sd_flags &= ~TOPOLOGY_SD_FLAGS;
*sd = (struct sched_domain){
.min_interval = sd_weight,
.max_interval = 2*sd_weight,
.busy_factor = 32,
.imbalance_pct = 125,
.cache_nice_tries = 0,
.busy_idx = 0,
.idle_idx = 0,
.newidle_idx = 0,
.wake_idx = 0,
.forkexec_idx = 0,
.flags = 1*SD_LOAD_BALANCE
| 1*SD_BALANCE_NEWIDLE
| 1*SD_BALANCE_EXEC
| 1*SD_BALANCE_FORK
| 0*SD_BALANCE_WAKE
| 1*SD_WAKE_AFFINE
| 0*SD_SHARE_CPUCAPACITY
| 0*SD_SHARE_PKG_RESOURCES
| 0*SD_SERIALIZE
| 0*SD_PREFER_SIBLING
| 0*SD_NUMA
| sd_flags
,
.last_balance = jiffies,
.balance_interval = sd_weight,
.smt_gain = 0,
.max_newidle_lb_cost = 0,
.next_decay_max_lb_cost = jiffies,
.child = child,
#ifdef CONFIG_SCHED_DEBUG
.name = tl->name,
#endif
};
cpumask_and(sched_domain_span(sd), cpu_map, tl->mask(cpu));
sd_id = cpumask_first(sched_domain_span(sd));
/*
* Convert topological properties into behaviour.
*/
if (sd->flags & SD_ASYM_CPUCAPACITY) {
struct sched_domain *t = sd;
for_each_lower_domain(t)
t->flags |= SD_BALANCE_WAKE;
}
if (sd->flags & SD_SHARE_CPUCAPACITY) {
sd->flags |= SD_PREFER_SIBLING;
sd->imbalance_pct = 110;
sd->smt_gain = 1178; /* ~15% */
} else if (sd->flags & SD_SHARE_PKG_RESOURCES) {
sd->flags |= SD_PREFER_SIBLING;
sd->imbalance_pct = 117;
sd->cache_nice_tries = 1;
sd->busy_idx = 2;
#ifdef CONFIG_NUMA
} else if (sd->flags & SD_NUMA) {
sd->cache_nice_tries = 2;
sd->busy_idx = 3;
sd->idle_idx = 2;
sd->flags |= SD_SERIALIZE;
if (sched_domains_numa_distance[tl->numa_level] > RECLAIM_DISTANCE) {
sd->flags &= ~(SD_BALANCE_EXEC |
SD_BALANCE_FORK |
SD_WAKE_AFFINE);
}
#endif
} else {
sd->flags |= SD_PREFER_SIBLING;
sd->cache_nice_tries = 1;
sd->busy_idx = 2;
sd->idle_idx = 1;
}
/*
* For all levels sharing cache; connect a sched_domain_shared
* instance.
*/
if (sd->flags & SD_SHARE_PKG_RESOURCES) {
sd->shared = *per_cpu_ptr(sdd->sds, sd_id);
atomic_inc(&sd->shared->ref);
atomic_set(&sd->shared->nr_busy_cpus, sd_weight);
}
sd->private = sdd;
return sd;
}sd_init()函数比较长,但是逻辑却不难理解。第7行代码,从tl->data中获取该CPU对应的struct sched_domain数据结构,注意tl数据结构中的mask和sd_flags都是函数指针变量。tl->mask(cpu)返回该CPU在某个SDTL下对应的兄弟CPU的bitmap,例如对于ARM处理器来说,定义了一个struct cputopo_arm数据结构来描述CPU之间的关系。
// /arch/arm/include/asm/topology.h:9
struct cputopo_arm {
int thread_id;
int core_id;
int socket_id;
cpumask_t thread_sibling;
cpumask_t core_sibling;
};cputopo_arm数据结构中又定义了两个bitmap来描述SMT级的兄弟关系和MC级的兄弟关系,这些在系统SMP初始化时会枚举完成。
回到bulid_sched_domain()函数的第8-23行,由于SDTL的遍历是从SMT级到MC级再到DIE级递进的,因此SMT级的CPU可以看做MC级的孩子,MC级可以看做SMT级CPU的父亲,它们存在父子关系或上下级关系。struct sched_domain()数据结构中有parent和child成员用于描述此关系。
经过每个CPU的遍历以及叠加每个SDTL层级的遍历后完成对调度域的初始化。接下来看调度组的初始化,build_sched_domains()函数如下
// /kernel/sched/topology.c:1642
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
...
/* Build the groups for the domains */
for_each_cpu(i, cpu_map) {
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
if (build_sched_groups(sd, i))
goto error;
...
}第7行代码,for循环依然遍历cpu_active_mask中的所有CPU,然后再遍历该CPU对应的调度域,因为每个CPU在每个SDTL都分配了调度域,这里*per_cpu_ptr(d.sd, i)获取最低的SDTL对应的调度域,sd->parent得到上一级的调度域。
build_sched_groups()函数创建调度组。
// /kernel/sched/topology.c:865
static int
build_sched_groups(struct sched_domain *sd, int cpu)
{
struct sched_group *first = NULL, *last = NULL;
struct sd_data *sdd = sd->private;
const struct cpumask *span = sched_domain_span(sd);
struct cpumask *covered;
int i;
get_group(cpu, sdd, &sd->groups);
atomic_inc(&sd->groups->ref);
if (cpu != cpumask_first(span))
return 0;
lockdep_assert_held(&sched_domains_mutex);
covered = sched_domains_tmpmask;
cpumask_clear(covered);
for_each_cpu(i, span) {
struct sched_group *sg;
int group, j;
if (cpumask_test_cpu(i, covered))
continue;
group = get_group(i, sdd, &sg);
cpumask_setall(sched_group_mask(sg));
for_each_cpu(j, span) {
if (get_group(j, sdd, NULL) != group)
continue;
cpumask_set_cpu(j, covered);
cpumask_set_cpu(j, sched_group_cpus(sg));
}
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
}
last->next = first;
return 0;
}build_sched_groups()函数为CPU在某个调度域内建立对应的调度组。和调度域一样,每个CPU在各个SDTL都会建立一个调度组。struct sched_domain数据结构中的groups指针指向该调度域里的调度组链表,struct sched_group数据结构中的next成员把同一个调度域中的所有调度组都串成一个链表。第11行代码,get_group()函数获取该CPU对应的调度组并放在sd->groups指针中。第14行代码,只处理该调度域中第一个CPU的情况,因为没有必要重复计算其他兄弟CPU。struct sched_group数据结构中的cpumask[0]用于描述该调度组包含的CPU情况。第22-45行代码,两个for循环依次设置了该调度域sd中不同CPU对应的调度组的包含关系,这些调度组分别用next指针串联起来。
举个例子,假设参数sd调度域是一个DIE级别的调度域,包含CPU0和CPU1,即span等于[cpu0|cpu1]。第一次循环i=0,sg为cpu0对应DIE级别的sg0,group返回cpu0,j=0时get_group()函数也返回cpu0,设置sg0->cpumask为[cpu0],j=1时get_group()函数也返回cpu0,因此设置sg0->cpumask为[cpu0|cpu1]。为什么j等于0和1时,get_group()都返回cpu0呢?
来看get_group()函数。
// /kernel/sched/topology.c:828
static int get_group(int cpu, struct sd_data *sdd, struct sched_group **sg)
{
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
struct sched_domain *child = sd->child;
if (child)
cpu = cpumask_first(sched_domain_span(child));
if (sg) {
*sg = *per_cpu_ptr(sdd->sg, cpu);
(*sg)->sgc = *per_cpu_ptr(sdd->sgc, cpu);
atomic_set(&(*sg)->sgc->ref, 1); /* for claim_allocations */
}
return cpu;
}j=1时,get_group()函数首先获取cpu1在DIE级别的调度域sd_die_1,然后通过child指针获取MC级别的调度域sd_mc_1。获取sd_mc_1域里的第一个CPU,为何会是CPU0而不是CPU1呢?我们返回来仔细看一下build_sched_domain()函数,发现sd_mc域的span兄弟位图的设置和tl->mask(cpu)函数相关,同属MC级别的CPUs应该包含同样的范围,也就是对于CPU0来说,它的兄弟位应该是[cpu0|cpu1],同样对于CPU1来说也是同样的道理。
继续来看build_sched_domains()函数。
// /kernel/sched/topology.c:1642
static int
build_sched_domains(const struct cpumask *cpu_map, struct sched_domain_attr *attr)
{
...
/* Calculate CPU capacity for physical packages and nodes */
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
/* Attach the domains */
rcu_read_lock();
for_each_cpu(i, cpu_map) {
rq = cpu_rq(i);
sd = *per_cpu_ptr(d.sd, i);
/* Use READ_ONCE()/WRITE_ONCE() to avoid load/store tearing: */
if (rq->cpu_capacity_orig > READ_ONCE(d.rd->max_cpu_capacity))
WRITE_ONCE(d.rd->max_cpu_capacity, rq->cpu_capacity_orig);
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
if (rq && sched_debug_enabled) {
pr_info("root domain span: %*pbl (max cpu_capacity = %lu)n",
cpumask_pr_args(cpu_map), rq->rd->max_cpu_capacity);
}
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}第7-15行代码,设置各个调度组能力系数(capacity)。内核通常设定单个CPU最大的调度能力系数为1024。不同体系架构对调度能力系数有不同的计算方法,例如ARM上的实现会考虑不同的CPU IP核的差异和频率的不同,可以见[/arch/arm/kernel/topology.c]。
最后cpu_attach_domain()把相关的调度域关联到运行队列的struct rq的root_domain中,还会对各个级别的调度域做一些精简,例如调度域和上一级调度域的兄弟位图(span)相同,或者调度域的兄弟位只有自己一个,那么就要删掉一个了。
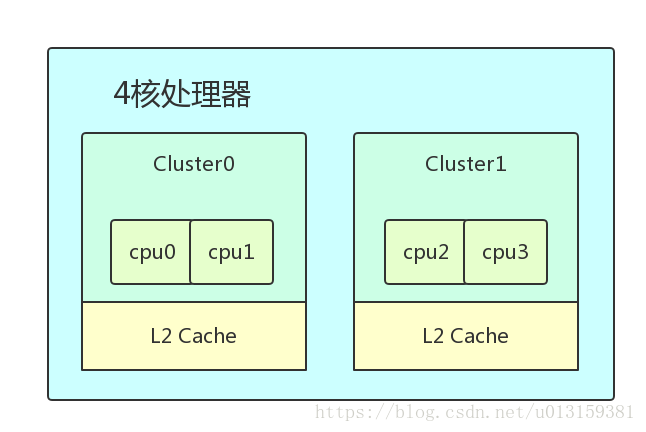
下面举例说明说明,如上图所示,假设在一个4核处理器中,每个物理CPU核心拥有独立L1 Cache且不支持超线程技术,分成两个簇Cluster0和Cluster1,每个簇包含两个物理CPU核,簇中的CPU核共享L2 Cache。
在分析之前先总结Linux内核里构建CPU域和调度组拓扑关系图的一些原则。
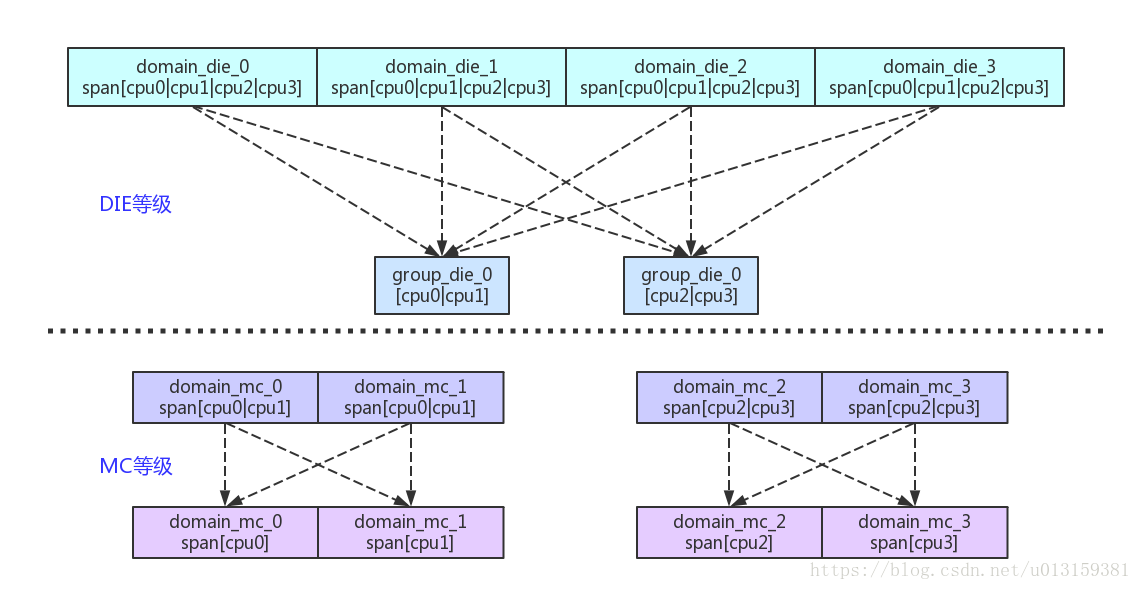
struct sched_domain_topology_level来描述,简称为SDTLPer-CPU变量,并且为每个CPU都分配响应的数据结构span成员来描述,调度组有cpumark成员来描述兄弟关系groups成员是链表头。因为每个CPU核心只有一个执行线程,所以4核处理器没有SMT属性。cluster由两个CPU物理核组成,这两个CPU是MC层级且是兄弟关系。整个处理器可以看做一个DIE级别,因此该处理器只有两个层级,即MC和DIE。根据上述原则,可以标识出上述4核处理器的调度域和调度组的拓扑关系图,如下图所示。
每个SDTL为每个CPU都分配了对应的调度域和调度组,以CPU0为例,在图中,虚线表示管辖。
对于DIE级别,CPU0对应的调度域是domain_die_0,该调度域管辖着4个CPU并包含两个调度组,分别为group_die_0和group_die_1。其中
group_die_0管辖着CPU0和CPU1group_die_1管辖着CPU2和CPU3对于MC级别,CPU0对应的调度域是domain_mc_0,该调度域管辖着CPU0和CPU1并包含两个调度组,分别为group_mc_0和group_mc_1。其中
group_mc_0管辖CPU0group_mc_1管辖CPU1为什么DIE级别的所有调度组只有group_die_0和group_die_1呢?
因为在建立调度组的函数build_sched_groups()有一个判断(if(cpu != cpumask_first(span))),这样只有参与cpu为调度域的第一个CPU才会建立DIE层级的调度组。注意get_group()函数,它会返回子调度域兄弟关系的第一个CPU。
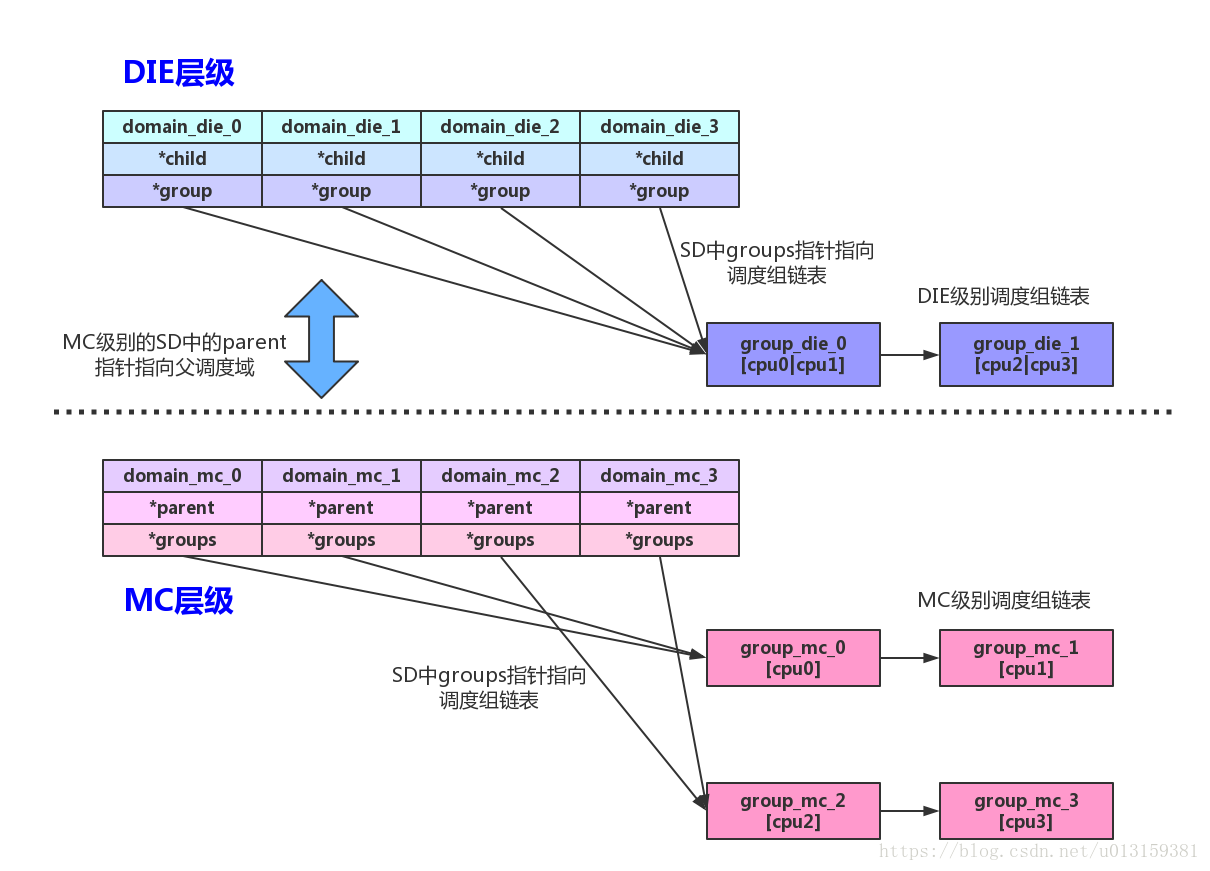
除此之外还有两层关系,一是父子关系,通过struct sched_domain数据结构中的parent和child成员来完成;另外一个关系是同一个SDTL中调度组都链接成一个链表,通过struct sched_domain数据结构中的groups成员来完成,如下图所示。
最后再关心一下,SMP是如何均衡负载的呢?在内核中,SMP负载均衡机制从注册软终端开始,每次系统处理调度tick时会检查当前是否需要处理SMP负载均衡。详情可见[start_kernel()->sched_init()->init_sched_fair_class()]。
// /kernel/sched/fair.c:10430
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMP
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
nohz.next_balance = jiffies;
nohz.next_blocked = jiffies;
zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
#endif
#endif /* SMP */
}看到那个run_rebalance_domains就是负载均衡的核心入口了。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!