社区微信群开通啦,扫一扫抢先加入社区官方微信群

社区微信群
字符串在Python内部的表示是Unicode编码,首先我们来认识Python中encode()和decode()的作用与区别:
在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符转换成unicode编码,如str1,decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2,encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
常见文档读取有:
其中TXT文档的读取较为简单,爬取网页数据时注意read()的编码设置即可
我们主要来介绍使用pdfminer3k模块读取PDF
——英文PDF文件支持最好且只支持英文PDF是pyPDF2库
——而对于多语言PDF文件支持最好的则是pdfminer,我们这里就使用pdfminer3k库来实现读取PDF。
1. 安装pdfminer3k:
——pip install pdfminer3k
——python setup.py install`在这里插入代码片`
2. 验证安装pdfminer3k是否成功:
在cmd下,进入tools目录下( cd ~/Downloads/pdfminer3k-1.3.1/tools)后使用命令 ——python3 pdf2txt.py ../samples/simple1.pdf #..是退回上一层目录的意思
3. Python读取PDF文档:
pdfminer3k中类的关系: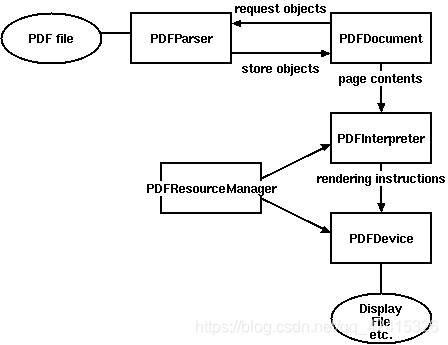
读取流程:
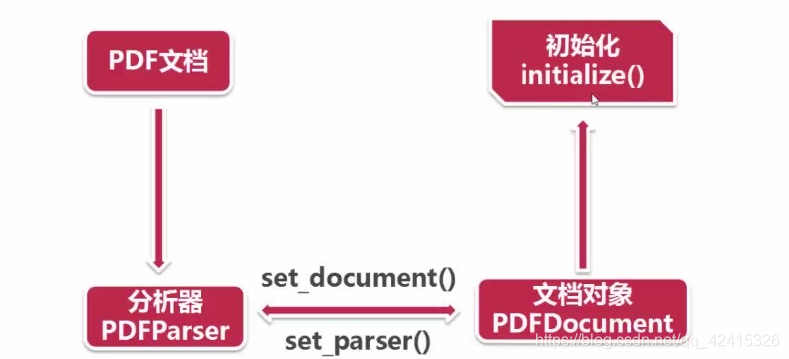
——打开pdf文档的文件对象:
fp = open("naacl06-shinyama.pdf", 'rb') #本地文档
fp = urlopen('https://www.tencent.com/zh-cn/articles/802741466496787.pdf') #在线pdf
——创建文档分析器(解析器):
pdf_parser = PDFParser(fp) #传入pdf,从中获取数据
——创建文档对象,保存获取的数据:
pdf_doc = PDFDocument() #保存获取的数据,和PDFParser是相互关联的
——连接分析器和文档对象:
pdf_parser.set_document(doc)
doc.set_parser(pdf_parser)
——判断文件是否允许文本提取:
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed #raise如果抛出异常,后续语句不执行
——对文档对象提供密码(password)初始化,没有就不用传该参数:
doc.initialize("")
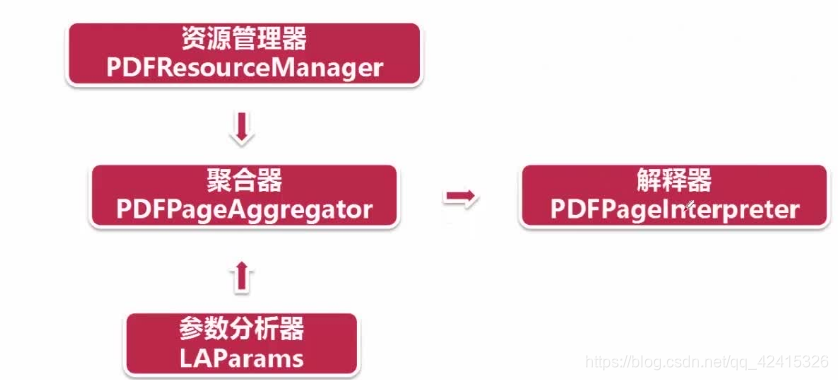
——创建资源管理器:
resource = PDFResourceManager() #用于存储共享资源,如字体或图像
——创建参数分析器:
laparam = LAParams()
——创建一个页面聚合器对象:
device = PDFPageAggregator(resource, laparams=laparam)
——创建一个页面解析器对象来处理页面内容:
interpreter = PDFPageInterpreter(resource, device) #传入的是页面资源和聚合器对象
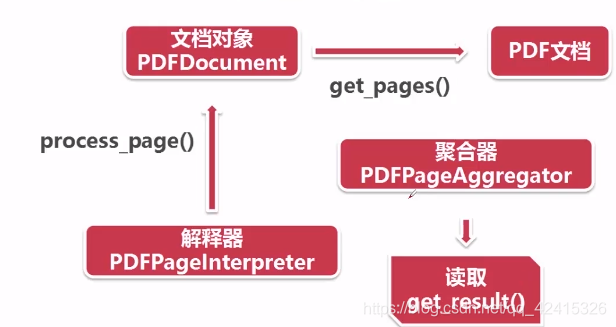
——获取page列表:
doc.get_pages()
——使用页面解释器来读取:
interpreter.process_page(page)
——使用页面聚合器获得内容:
layout = device.get_result() #这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
——循环遍历取出聚合器获得的对象内容:
for out in layout:
if hasattr(out, 'get_text'): #判断out对象是否具有get_text方法
print(out.get_text()) #输出out对象
Layout布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象,形成一个树结构。如图所示: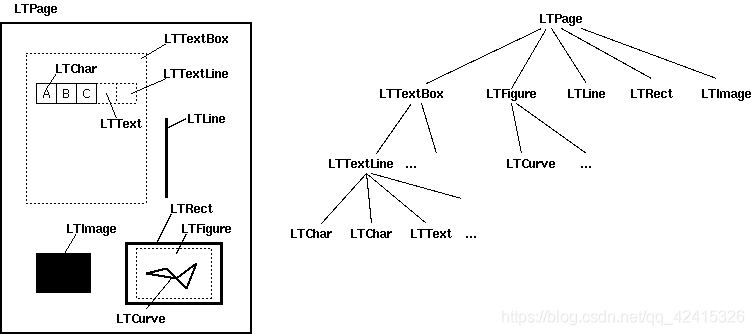
树结构节点含义:
| 节点 | 含义 |
|---|---|
| LTPage | 表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象 |
| LTTextBox | 表示一组文本块可能包含在一个矩形区域。注意此box是由几何分析中创建,并且不一定表示该文本的一个逻辑边界。它包含LTTextLine对象的列表。使用 get_text()方法返回文本内容 |
| LTTextLine | 包含表示单个文本行LTChar对象的列表。字符对齐要么水平或垂直,取决于文本的写入模式。使用get_text()方法返回文本内容 |
| LTAnno | 在文本中字母实际上被表示为Unicode字符串。需要注意的是,虽然一个LTChar对象具有实际边界,LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入 |
| LTImage | 表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象 |
| LTLine | 代表一条直线。可用于分离文本或附图 |
| LTRect | 表示矩形。可用于框架的另一图片或数字。 |
| LTCurve | 表示一个通用的Bezier曲线 |
读取PDF文档完整实例:
from urllib.request import urlopen
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
#获取文档
#fp = open("naacl06-shinyama.pdf", 'rb')
fp = urlopen('https://www.tencent.com/zh-cn/articles/802741466496787.pdf')
#创建解释器
pdf_parser = PDFParser(fp)
#PDF文档对象
doc = PDFDocument()
#连接解释器和文档对象
parser.set_document(doc)
doc.set_parser(parser)
#初始化文档
doc.initialize()
#创建PDF资源管理器
resource = PDFResourceManager()
# 创建一个PDF参数分析器
laparam = LAParams()
# 创建聚合器
device = PDFPageAggregator(resource, laparams=laparam)
#创建PDF页面解析器
interpreter = PDFPageInterpreter(resource, device)
# 循环遍历列表,每次处理一页的内容
# doc.get_pages() 获取page列表
for page in doc.get_pages():
#使用页面解释器来读取
interpreter.process_page(page)
#使用聚合器获得内容
layout = device.get_result()
for out in layout:
if hasattr(out, 'get_text'):
print(out.get_text())
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!
